
Stranded capacity has always been the biggest waste in the datacenter, and over the years, we have added more and more clever kinds of virtualization – hardware partitions, virtual machines and their hypervisors, and containers – as well as the systems management tools that exploit them. There is a certain amount of hardware virtualization going on these days, too, with the addition of virtual storage and virtual switching to so-called SmartNICs.
The next step in this evolution is disaggregation and composability, which can be thought of in a number of different ways. The metaphor we like here at The Next Platform is smashing all of the server nodes in a cluster and then stitching all of the components back together again with software abstraction that works at the peripheral transport and memory bus levels – what is commonly called composability. You can also think of this as making the motherboard of the system extensible and malleable, busting beyond the skin of one server to make a giant pool of hardware that can allow myriad, concurrent physical hardware configurations – usually over the PCI-Express bus – to be created on the fly and reconfigured as workloads dictate. This way, CPUs, memory, flash storage, disk storage, and GPU and FPGA accelerators are not tied so tightly to the nodes they happen to be physically located within.
There are a lot of companies that are trying to do this. Among the big OEMs, Hewlett Packard Enterprise has its Synergy line and Dell has its PowerEdge MX line and its Kinetic strategy. Cisco Systems did an initial foray into composability with its UCS M Series machines. DriveScale has offered a level of server composability through a special network adapter that allows compute and storage to scale independently at the rack scale, across nodes, akin to similar projects under way at Intel, Dell, the Scorpio alliance of Baidu, Alibaba, and Tencent, and the Open Compute Project spearheaded by Facebook. Juniper Networks acquired HTBase to get some composability for its network gear, and Liqid dropped out of stealth in June 2017 with its own PCI-Express switch fabric to link bays of components together and make them composable into logical servers. TidalScale, which dropped out of stealth a few months later in October 2017, has created what it calls a HyperKernel to glom together multiple servers into one giant system that can then be carved up into logical servers with composable components; rather than use VMs to break this hyperserver down, LXC or Docker containers are used to create software isolation. GigaIO has been coming on strong in the past year with its own PCI-Express switches and FabreX fabric.
There are going to be lots of different ways to skin this composability cat, and it is not clear which way is going to dominate. But our guess is that the software approaches from DriveScale, Liqid, and TidalScale are going to prevail compared to the proprietary approaches that Cisco, Dell, and HPE have tried to use with their respective malleable iron. Being the innovator, as HPE was here, may not be enough to win the market, and we would not be surprised to see HPE snap up one of these other companies and then Dell to snap up whichever one HPE doesn’t acquire. Then again, the Synergy line of iron at HPE was already at an annualized revenue run rate of $1.5 billion – with 3,000 customers – and growing at 78 percent in the middle of this year, so maybe HPE thinks it already has the right answer.
Liqid, for one, is not looking to be acquired and in fact has just brought in $28 million in its second round of funding, bringing the total funds raised to date to $50 million; the funding was led by Panorama Point Partners, with Iron Gate Capital and DH Capital kicking in some dough. After three years of hardware and software development, Liqid needs more cash to build up its sales and marketing teams to chase the opportunities and also needs to plow funds back into research and development to keep the Liqid Fabric OS, managed fabric switch, and Command Center management software moving ahead.
“We have a handful of large customers that make up a good chunk of our revenues right now,” Sumit Puri, co-founder and chief executive officer at Liqid, tells The Next Platform. “These are the customers we started with back in the day, and we have ramped them to the size we want all of our customers to be, and some of them are showing us projects out on the horizon that are at massive scale. We have dozens of proofs of concept under way, and some of them will be relatively small and never grow into a seven-figure customer. Some of them will.”
Puri is not about to get into specific pricing for the switches and software that turn a rack of servers with peripherals into a stack of composable, logical servers, but says that the adder over the cost of traditional clusters is on the order of 5 percent to 10 percent to the total cost of the infrastructure. But the composability means that every workload can be configured with the right logical server setup – the right number of CPUs, GPUs, FPGAs, flash drives, and such – so that utilization can be driven up by factors of 2X to 4X on the cluster compared to the industry average. Datacenter utilization, says Puri, averages something on the order of 12 percent worldwide (including compute and storage), and as best as Liqid can figure Google, which is the best at this in the industry, is average 30 percent utilization in its datacenters. The Liqid stack can drive it as high as 90 percent utilization, according to Puri. That’s mainframe-class right there, and about as good as it gets.
The prospect pipeline is on the order of thousands of customers, and that is why funding is necessary. It takes people to attack that opportunity, and even if HPE has been talking about composability for the past five years, it is not yet a mainstream approach for systems.

As with most distributed systems, there is a tension between making one large pool of infrastructure and making multiple isolated pools to limit the blast area in the event that something goes wrong in the infrastructure. The typical large enterprise might have pods of compute, networking, and storage that range in size from a half rack, a full rack, or up to one, tow, or even three racks, but rarely larger or smaller than that. They tend to deploy groups of applications on pods and upgrade the infrastructure by the pod to make expanding the infrastructure easier and more cost effective than doing it a few servers at a time.
In a deal that Liqid is closing right now, the customer wants to have a single 800-node cluster, but only wants to have 200 of the nodes hanging off the Liqid PCI-Express fabric because it does not want to pay the “composability tax,” as Puri put it, on all of those systems. Over time, as the company will possibly expand the Liqid fabric into the remaining 600 servers, but it is far more likely that it will be the new servers that are adding in the coming years that will have them, and after a three or four year stint, the old machines that did not have composability will simply be removed from the cluster.
There are a number of different scenarios where composability is taking off according to Liqid. The important thing to note is that the basic assumption is that components are aggregated into their own enclosures and then the PCI-Express fabric in the Liqid switch can reaggregate them as needed, tying specific processors in servers to specific flash or Optane storage, network adapters, or GPUs within enclosures. You can never attach more devices to a given server than it allows, of course, so don’t think that with the Liqid switch you can suddenly hang 128 GPUs off of one CPU. Your can’t do more than the BIOS says. But you can do that much and less as needed.

The Liqid fabric is not just restricted to PCI-Express, but can also be extended with Ethernet and InfiniBand attachment for those cases when distance and horizontal scale is more important than the low latency that PCI-Express switching affords. Liqid’s stack does require disaggregation at the physical level, meaning that the peripherals are ganged up into their respective enclosures and then linked together using the PCI-Express fabric or using NVM-Express over Ethernet or perhaps GPUDirect over RDMA networks to link flash and GPUs to compute elements.
Next week at the SC19 supercomputer conference in Denver, Liqid will be showing off the next phase of its product development, where the hardware doesn’t have to be pooled at the physical layer and then composed, but rather standard servers using a mix of CPUs and GPUs and FPGAs for compute and flash and Optane for storage will be able to have their resources disaggregated, pooled, and composable using only the Liqid software to sort it into pools and then ladle it all out to workloads. The performance you get will, of course, be limited by the network interface used to reaggregate the components – Ethernet will be slower than InfiniBand will be slower than PCI-Express, and for many applications, the only real impact will be the load time for the applications and the data. Any application that requires a lot of back and forth chatter between compute and storage elements will want to be on PCI-Express. But this new capability will allow Liqid to go into so-called “brownfield” server environments and bring composability to them.
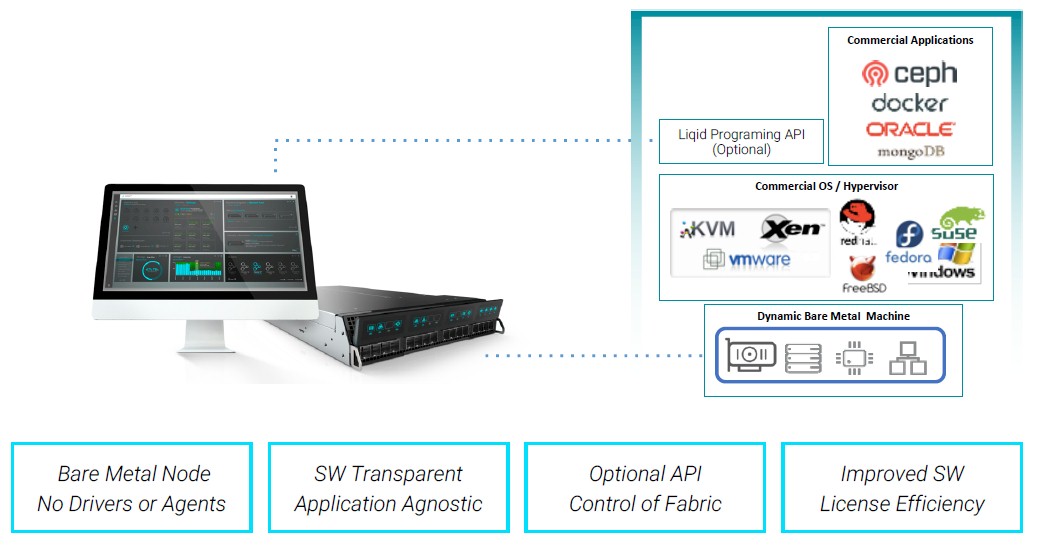
So where is composability taking off? The first big area of success for Liqid was, not surprisingly, for GPU-centric workloads, where the GPUs traditionally get locked away inside of a server node and are unused most of the time. Disaggregation and composability allow for them to be kept busy doing workloads, and the hardware configuration can change rapidly as needed. If you put a virtualization or container layer on top of the reaggregated hardware, then you can move workloads around and change hardware as necessary. This is, in fact, what companies are now interested in doing, with either a VMware virtualization or Kubernetes container environment on top of the liquid hardware. Composable bare metal clouds are also on the rise, like this:

Liqid has also partnered recently with ScaleMP so it can offer virtual NUMA servers over composable infrastructure and therefore be better able to compete with TidalScale, which did this at the heart of its eponymous composable architecture.
There is also talk about using Liqid on 5G and edge infrastructure – but everybody is trying to get a piece of that action.

What To Do When You Can’t Get Nvidia H100 GPUs
In a world where allocations of “Hopper” H100 GPUs coming out of Nvidia’s factories are going out well into 2024, and the allocations for the impending “Antares” MI300X and MI300A GPUs are probably long since spoken for, anyone trying to build a GPU cluster to power a large language model …

AI Is Driving Storage Down New Avenues
Storage systems are inherently data intensive. But the rapid emergence of artificial intelligence as a standard datacenter workload has storage vendors scrambling to design platforms that better meet the more stringent performance needs of these applications. Panasas, one of the few HPC storage specialist that hasn’t been swallowed by a …
Why There’s Hard, Cold Cash For Soft, Disaggregated Routing
No matter if you are talking about compute or networking, there are two opposing forces that are constantly at interplay on a field of green money. The first force is the desire to implement as many specialized functions in transistors to accelerate the performance of those functions. The other force …
Be the first to comment