
In a world where allocations of “Hopper” H100 GPUs coming out of Nvidia’s factories are going out well into 2024, and the allocations for the impending “Antares” MI300X and MI300A GPUs are probably long since spoken for, anyone trying to build a GPU cluster to power a large language model for training or inference has to think outside of the box.
For those who want to buy and control their own iron, that might mean going to Intel for Gaudi 2 accelerators, or trying to get some Nvidia A100s or AMD MI250Xs, or even going to Cerebras Systems, SambaNova Systems, Groq, or Graphcore, Or it may mean paying a 2.5X to 3X premium to run LLMs on a big cloud – and don’t assume you can get reserved instance capacity there, either.
Or, you can build a cluster that makes use of Nvidia’s tweaked “Lovelace” L40S accelerator and employing composable infrastructure from Liqid to get a much higher ratio of GPU to CPU compute to boot. Provided your LLM can do its AI training without very much FP64 double precision floating point – and clearly, there are models that make do with FP32 and lower precision because none of the exotic AI engines above have any FP64 math at all. Portions of their workloads suffer a performance degradation because of this, but they make up for it in other ways. (Computer architecture is always about tradeoffs, isn’t it?)
For years now, composable infrastructure supplier Liqid has been stressing how composable GPU enclosures and composable I/O infrastructure linking them to servers in a cluster allow companies to share GPUs across different workloads with different configurations and therefore allow the overall GPU utilization to be driven upwards. This is a way to get more work out of the GPU money that you have spent. Which is important. But these days, you need to be able to get a lot of work out of whatever GPUs you can get your hands on.
Back in early August, Nvidia launched the L40S accelerator based on its Lovelace AD102, a passively cooled server variant of the same GPU that is used in its RTX 5000 and RTX 6000 graphics cards and L40 CPU compute engine for its OVX metaverse platforms, the latter announced back in September 2022. We were on holiday in August when these L40S devices came out amongst a bunch of other graphics cards, and had not yet circled back to look at them.
The launch of the UltraStack systems by Liqid at the SC23 supercomputing conference this week was a good reason to circle back. So let’s go.
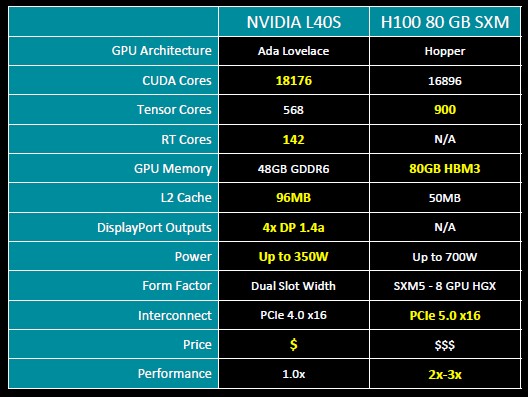
The L40S is billed by Nvidia to be the “universal datacenter GPU,” which is presumably the case because it can drive graphics as well as 32-bit and lower precision compute. Specifically, the L40S is a variant of the L40 that is certified on a wider variety of servers and that is certified to run AI training and inference workloads alike. The L40 was aimed only at AI inference.
The L40S package has a single AD102 GPU and 48 GB of GDDR6 frame buffer memory, which delivers 864 GB/sec of memory bandwidth and 91.6 teraflops of FP32 performance, 183 teraflops of FP32 performance using the Nvidia TF32 format on the Tensor Cores in the AD102, and 366 teraflops of performance with sparsity support on the Tensor Cores. If you want to push to the low precision limit, then the L40S can push 733 teraflops at FP8 and double that at 1.47 petaflops with sparsity support activated. It can drive INT8 and INT4 data at the same rate. FP64 is a measly 1.4 teraflops on the vector cores running in emulation mode. It’s basically non-existent.
The original Hopper H100 SXM5 device, by contrast, had 80 GB of HBM3 memory and 3.35 TB/sec of memory bandwidth, and delivered a raw 67 teraflops of FP32 performance on its vectors and 989 teraflops on its Tensor Cores in TF32 mode with sparsity on and 3.96 petaflops in FP8 or INT8 formats with sparsity on.
The performance of the L40S is not simple to gauge against the H100, but generally, it is better on AI workloads that Nvidia has talked about compared to the A100 by between 1.2X and 1.7X where the rubber hits the road. George Wagner, executive director of product and technical marketing at Liqid, tells The Next Platform that on a wide variety of AI training and inference workloads, the H100 has between 2X and 3X the performance of the L40S, but the H100 burns twice as much juice and costs on the order of 3X as much. And, importantly, are not really available right now. If you want an H100, you are now waiting on the order of six months for it.
And that is why people have been banging on Liqid’s doors to use its composable infrastructure to cram a lot more Lovelace GPU accelerators into a system than Nvidia has designed into the HGX system boards it sells to OEMs and ODMs based on the Hopper GPUs, which it uses in its own DGX systems as well.
“We have been talking about the benefits of composability for more than three years now,” Wagner says. “We have this whole approach around software being able to deliver performance, flexibility, and efficiency. What we are finding is there are a bevy of customers – and its not surprising, really – who just want the performance. We have one customer who told us he bought Liqid just because he could put 20 GPUs behind the server and meet his performance requirements, and that was kind of the end of that. He had money and he needed results.”
The good news is that with the Liqid fabric that expands the PCI-Express bus and virtualizes it, companies can attach anywhere from 8 to 16 of the L40S GPUs to a single server. And Liqid can push it further if you need it to.
The initial UltraStack server from Liqid is being built in conjunction with Dell, and is based on its 2U rack-mounted PowerEdge R760xa server, which uses Intel’s “Sapphire Rapids” Xeon SP processors.

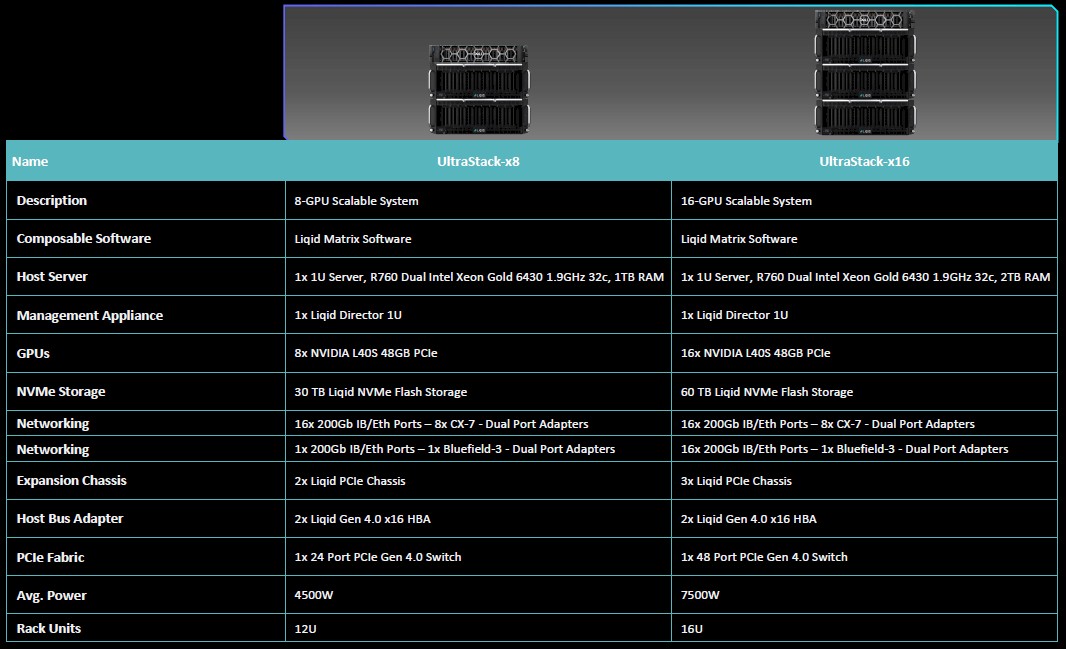
The UltraStack includes one of these PowerEdge R760xa servers paired with the Liqid Director management console and the Liqid PCI-Express fabric switch and three expansion units that have up to 16 of the L40S GPUs, up to 16 of Liqid’s “Honey Badger” 4 TB NVM-Express flash drives. There is a single BlueField-3 DPU from Nvidia with a pair of 200 Gb/sec ports for north-south traffic on the network and eight dual port, 200 Gb/sec ConnectX-7 NICs in the enclosures to lashing the GPUs to each other across multiple enclosure sets.
Here are how the UltraStack-x8 and UltraStack-x16 machines are configured:
And here is how the UltraStack setup compares to just buying four 2U servers with storage and four L40S GPUs in each box, which is the standard way to go:

It is hard to argue against the UltraStack with 35 percent higher performance thanks to the L40S compute engines linked directly to each other over the PCI-Express fabric and a 35 percent reduction in power when moving from four X86 host servers down to one, which also cuts software licensing costs by 75 percent and improves the overall total cost of ownership by 25 percent.
None of this takes into account any benefits that would derive from composability. No one has time for that now. But if they buy Liqid systems, they will essentially get it for free and can figure out how to use it when they come up for air.

A Tale Of Two Nvidia Eos Supercomputers
Note: This story augments and corrects information that originally appeared in Half Eos’d: Even Nvidia Can’t Get Enough H100s For Its Supercomputers, which was published on February 15. So, as it turns out, there are two supercomputers named Eos, and even the people in the press relations department at Nvidia, …
Nvidia Says “Blackwell” GPU Issues Are Fixed, Ramp Starts In Fiscal Q4
Welcome to the most important earnings call in history, with the weight of the aggregate stock markets of the entire world hanging on what Nvidia says and doesn’t say. Well, the most important one until thirteen weeks from now. And get used to that cadence until this GenAI boom either …
Berkeley Lab Opens Bidding For Future NERSC-10 Exascale System
The National Energy Research Scientific Computing Center at Lawrence Berkeley National Laboratory, one of the key facilities of the US Department of Energy that drives supercomputing innovation and that spends big bucks so at least a few vendors will design and build them, has opened up the bidding on its …
Interesting! MLPerf 3.1 Training (11/08/23 https://mlcommons.org/benchmarks/training/ ) has some interesting results for L40, L40S, and others. With DLRM-dcnv2, for example, training is reported to take 25 minutes with 8x L40, 23 minutes with 8x L40S, 12 minutes with 8x H100-PCIe, and just 4 minutes with 8x H100-SXM5 (scaling beyond 8x is not extra super though as 64x H100-SXM5 gives 1.4 minutes, and 128x yields 1 minute).
I would expect that Ultrarack-x16 or even -x32 (if planned) would be the more interesting ones for AI trainers (eg. Wagner mentions a satisfied customer who wanted to “put 20 GPUs behind the server”; so maybe -x24 too). And composability (or de-composability) to be a great bonus when switching over to inference-oriented workloads. Cool stuff!
If you are in need for H100 you can contact me on LinkedIn – Amit Kuperman, in Nebius we have big capacity and really good prices for many kind of GPU clusters.