

It is hard to quantify the amount of effort in systems and application software development that has been done precisely because there is no easy, efficient, and cheap way to make a bunch of cheap commodity servers look like one wonking system with a big ole flat memory space that is as easy to program as a PC but which brings to bear all that compute, memory, and I/O of a cluster as a single system image.
We have SMP and NUMA glue chips to do such shared memory clustering in hardware, scaling from two to four and sometimes eight, sixteen, or higher numbers of sockets, with from several to dozens of terabytes of main memory across the processor sockets, depending on the architecture. While there are many flavors of server virtualization that allows for a single machine to be diced and sliced into many smaller machines, it has proved somewhat elusive for a software stack to take multiple machines and glue them together using commodity networking.
This is by no means an exhaustive list, but way back in 2001, a startup called Virtual Iron tried this with its “Katana” VFe hypervisor, which allowed up to sixteen sockets of server oomph to be linked together across nodes using the then hot new InfiniBand interconnect. The dot-com boom went bust, and Virtual Iron shifted to being a Xen hypervisor maker, and then was eaten by Oracle in 2009 and this became the foundation of its Oracle VM hypervisor for its own Linux distribution. RNA Networks, which was founded in 2006, tried to create a cluster-spanning hypervisor to compete against hardware based SMP and NUMA clustering, too, and the RNAmessenger stack did not require InfiniBand’s low latency Remote Direct Memory Access (RDMA) to work or its Ethernet clone, RDMA over Converged Ethernet (RoCE), but it helped. RNA was acquired by Dell in 2011, and its software been used for some flash storage clustering and never heard from again. ScaleMP had a similar cluster hypervisor called vSMP, and the company just got $10 million in funding in August; a segment of vSMP is rumored to be behind Intel’s Memory Drive Technology for its Optane P4800X 3D XPoint SSD memory extension for servers. And the team that founded Exelero and developed its NVMesh flash clustering came from ScaleMP. We have not talked to ScaleMP in a bit, so it is time to see what is happening with vSMP, particularly now that it has some competition in the asymmetric cluster racket now that startup TidalScale has entered the fold with a complete stack.
Other technologies, such as the Message Passing Interface (MPI) protocol commonly used in distributed HPC simulation and modeling applications, and the Spark distributed in-memory processing framework, exist precisely because the kind of effortless NUMA-style scaling of clusters over regular Ethernet interconnects has not worked well across workloads.
Let’s Take a Look Under The HyperKernel Hood
The core of the TidalScale tool is called HyperKernel, and as the name suggests, it is a kind of hypervisor that creates a distributed kernel that looks like one giant Linux kernel to the applications running on it, just as if they were running on a big NUMA box that costs a heck of a lot more dough than a cluster of plain vanilla Xeon servers using absolutely bog standard 10 Gb/sec Ethernet as the interconnect backplane. (Technically, this is a Unified Memory Architecture, not Non-Unified Memory Architecture as is done in server hardware these days.)
No, we didn’t believe it either. But the TidalScale team is not fooling around here.
The company was founded in 2013 by Ike Nassi, who is an adjunct professor of computer science at the University of California Santa Cruz and currently is the company’s chief technology officer. Among other things, Nassi was one of the designers of the Ada programming language and worked for Gordon Bell and Ken Fisher at early parallel supercomputer maker Encore Computer more than three decades ago. More recently, Nassi headed up the development of SAP’s HANA in-memory database, too. And in all of these jobs, memory is something Nassi has on his mind. David Reed, the company’s chief scientist, worked on SAP HANA as well and was an adjunct professor at the MIT Media Lab as well as HP Fellow working on peer-to-peer communications as well as the former chief scientist at spreadsheet and groupware pioneer Lotus, which was acquired by IBM in the 1990s. (Reed has a law named after him, which states that the utility of networks scales exponentially with its size, and he should know because he helped craft the TCP/IP protocol that underpins the Internet.)
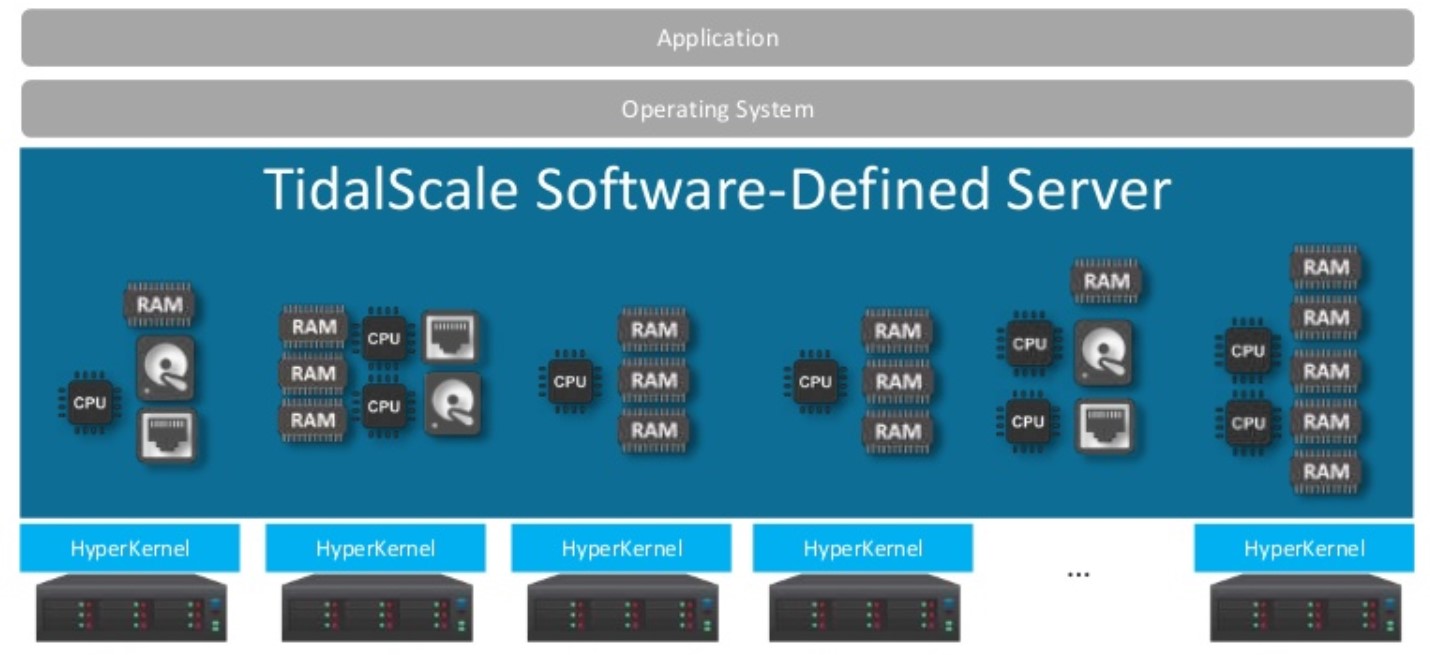
The HyperKernel distributed hypervisor spans multiple physical – and bare metal – servers, and they link to each other over a pretty modest 10 Gb/sec Ethernet switch over which the nodes create a private VLAN for that hypervisor that becomes its resource bus, Chuck Piercey, vice president of product management at TidalScale, explains to The Next Platform. The distributed HyperKernels running atop each node in the cluster are booted on the machines, which can be managed by a REST API stack or a graphical management console called WaveRunner. The HyperKernel distributed hypervisor has been shipping for more than a year now, and WaveRunner just started shipping in July. The point is the HyperKernel boots unmodified operating systems – in this case, Linux – and unmodified applications. There is no API layer, and as far as users are concerned, it just looks like a Linux system with a lot of cores and a lot of memory to feed them. (Or, more accurately, a Linux system with a lot of memory and a lot of cores to chew on it.)
“We run our test suites and are certified as server, we are not certified as a virtual machine, but as hardware,” says Nassi with a laugh. “Even though it is not hardware, it is a virtual machine. We run the Linux test procedures every day, and we have been hardware certified for a couple of years now to our satisfaction. And then Wall Street came to us and told us we needed to get certified to run on Red Hat, we tried to explain that it was the other way around, that Red Hat has to be certified on us. But we didn’t push it, and we just got Red Hat certified on us.”
Under the covers, everything physical in the servers in the cluster is virtualized: CPU, memory, and I/O, and equally importantly, everything is mobile – not just RAM. So the state of any CPU or any I/O chunk can also flit around by action of the HyperKernel. The right way to think of this HyperKernel, says Piercey, us is that you have your L1, L2, and L3 cache in the physical server and effectively what HyperKernel does is give you an L4 cache that just happens to be the size of all of the servers in a cluster of virtual machines for that node. And all the nodes think they have the same thing.
Now, let’s get technical. Take a two node cluster as an example. When the application gets a VM exit and you have a CPU on Node 0 that wants to get a page on Node 1, HyperKernel has a cost function that has a couple of options it can make. If it is just a read-only access, it may choose to copy that page over and then return it to the guest. (This is what ScaleMP and what we presume other similar tools like RNAmessenger and Virtual Iron were trying to do, too.) Or, if that page happens to be sitting in a nice locality set, HyperKernel can actually lift up the CPU from Node 0 and plunk it into one jumbo Ethernet frame and move it over to the guest running on Node 1.
“There are three things that make this work now where it did not in times past,” says Piercey. “Basically, the number of options here appears, from our data, to not tax a 10 Gb/sec Ethernet link. It is hardly taxed at all, and our theory was that because we can move the CPU to the locality set that it wants to be near, that seems to solve the problem of really stressing the network. The mobilizing of the CPU is the secret sauce. The other twist is that we have machine learning algorithms that continuously enhance the locality of the CPU, memory, and I/O. The way we are using the network, the latency is not as critical. We just use the raw Ethernet frame and the TCP/IP protocol. We get slightly better latency than storage. If you have a 100 step operation and you pay the price of moving the vCPU over to be local at the first step, the next 99 steps you are operating at local RAM. With VTx and VTd, you have a real nice set of capabilities that allow us to extract a vCPU from one system and put it back onto another one very quickly. The third thing is just managing dumb locality – what did the vCPU see most recently and what do you expect to need next, and use machine learning to make that better.”
As was the case with its predecessors, HyperKernel is not foolproof, and Piercey gives a funny example in trying to run the Lawrence Metagenomics Analysis Toolkit, or LMAT, genetic modeling tool on a cluster at Lawrence Livermore National Laboratory.
“To save on memory space, the programmer who created that software would every period of time go and touch every page and try to rewrite it in a more compressed format,” Piercey explains. “Which, as you can imagine on a hypervisor that is constantly shuffling memory pages around to find locality sets, is kind of a pathologically bad situation. So this is not perfect in all cases, but if you don’t need to touch all of the pages – and most applications don’t – and you have a reasonable mix of reads and writes, then this tends to work quite well.”
At the moment, TidalScale is supporting Red Hat Enterprise Linux and its CentOS clone as well as Ubuntu Server and FreeBSD Unix with HyperKernel. Windows Server is in alpha testing now, but there is no timetable for when it will be commercially available. HyperKernel can run on any Intel Xeon processor that supports VTx hardware-assisted virtualization, and at the moment the 10 Gb/sec networking driver for HyperKernel is only tested on Intel’s XL540/XL720 Ethernet adapter chip; other networking cards are supported, just not certified. TidalScale is not supporting AMD Epyc processors, or ARM server processors, or IBM Power processors, but Nassi says that there is nothing constraining TidalScale us from supporting other architectures. You just start with the Xeon because it owns the datacenter footprint today.
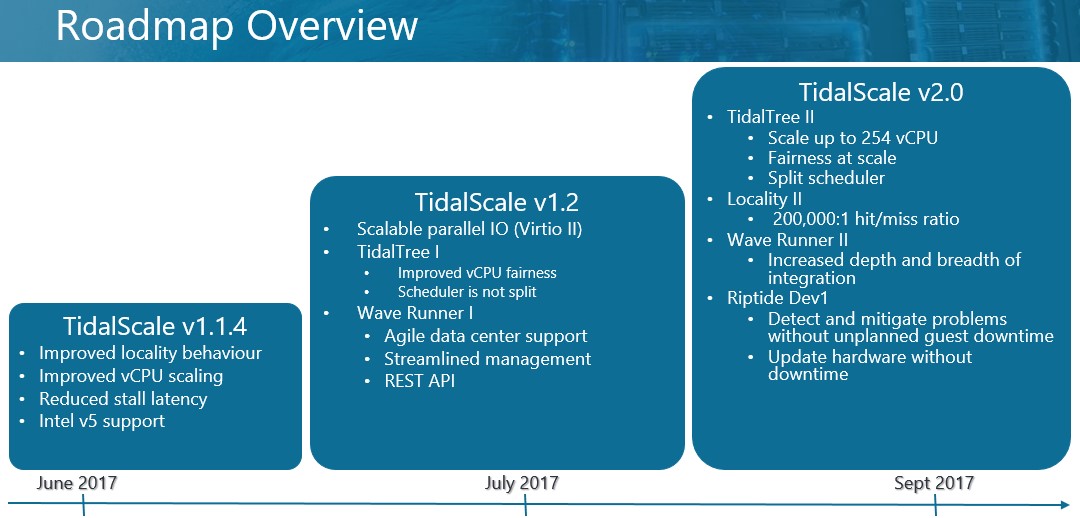
HyperKernel had early adopter shipments in early 2016, and has nearly a dozen customers in production now. WaveRunner, which automates the configuration of the servers, the switches, and the storage, started shipping in July and lets TidalScale take on a much larger and more diverse number of customers. Both the raw HyperKernel and the WaveRunner interface are based on a single REST API, so there is a way to programmatically control how hyperserver configurations are interlinked and change over time. Internally, TidalScale has used this API to integrate with the Jenkins continuous software development platform and with Docker containers for its own product development efforts and its testbed.
Now, if TidalScale would only open source the code for HyperKernel, it might get the hyperscalers interested. In fact, it is a wonder that they have not already invented something like HyperKernel for themselves. For all we know, they have.
So is HyperKernel going to be expensive? It doesn’t look like it. There is an annual subscription fee per server, on the order of $1,000 a pop with some wiggle for different support levels, and then an incremental 25 cents per GB per month for the memory used on that server node. This seems like a very reasonable price, especially considering what VMware charges just to slice up and manage a single node using ESXi and vCenter. And with HyperKernel, customers can use LCX or Docker containers to compartmentalize applications running across the cluster without having to resort to Xen, KVM, or another server virtualization hypervisor.
TidalScale heralds HPC industry luminary Gordon Bell as one of its outside investors, which includes Bain Capital Ventures, Hummer Winblad Venture Partners, Sapphire Ventures (the investment arm of SAP), Citrix Systems (which controls the Xen hypervisor), Samsung (which makes main memory), and Infosys (which needs to expand out beyond making money in IT services). It has raised $17.2 million to date, and currently has 26 employees. It seems very likely that some key IT player will try to acquire TidalScale before this takes off in the datacenter. It seems like the perfect piece of software to put on an FPGA and make a malleable NUMA chipset that could be embedded on a network card and removed from the CPU die entirely. That’s what we would do, provided the performance is good.
We will try to get a handle on the performance of HyperKernel running real applications next.




What they are doing is similar with MOSIX project.