
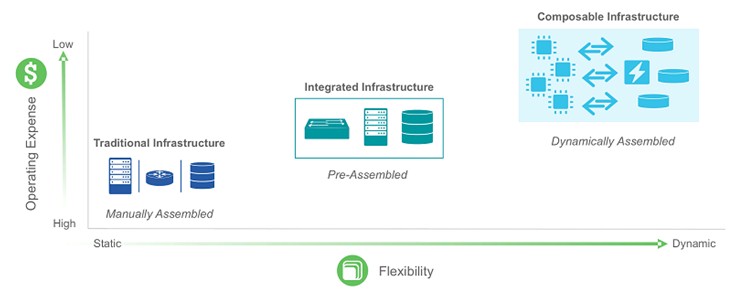
Sometimes you have to break something to make it work right. While distributed computing in its myriad forms has done much to allow for massive scale and relative uniformity in the datacenter, the basic building block of a distributed computing cluster – the server – still looks largely the same as it did twenty years ago.
That has to change, and it looks like it will with a movement that is underway that people are starting to call composable infrastructure.
“This is definitely the next age of compute, there is no question about that,” James Leach, director of platform management for the Computing Systems Product Group at Cisco Systems, tells The Next Platform. “It is about wrapping code around servers instead of sheet metal.”
But it is more than that. To put it simply, composable infrastructure means breaking apart the key components of the system – CPU, memory, I/O, and storage – from each other so they can be changed independently of each other. This may not seem like a very disruptive idea, but it is.
And it is an idea that upstart server chip makers – that means you, AMD, with your Zen and K12 chips, and it also means all of the members of the ARM collective and members of the OpenPower consortium trying to revitalize the Power chip – would do well to embrace if they want to make headway in the datacenter in the coming years. Composable infrastructure, which is definitely part of Intel’s future “Skylake” Xeon E5 v5 launch (if the Unified Path Interconnect, or UPI, does what we think it does), may be one of the reasons why ARM chip makers are being cagey about their chip designs, and the advent of this approach to server deconstruction and reconstruction may cause more than a few of them to rip up their roadmaps. But the payoff could be worth it, particularly if composable infrastructure becomes table stakes.
The changes that are underway in system design are not just going to alter the kinds of iron that enterprises, cloud builders, HPC centers, and hyperscalers buy, but when they buy them. Or more precisely, when they buy different parts of what will comprise a server. Intel, more than any other chip maker, and its server partners have benefitted from the tight coupling of processor, memory, and I/O technologies with each generation of CPU. In some ways, this coupling has become worse as first memory controllers and then Ethernet controllers have been added to processors. This integration is great for Intel and good for customers in some ways, but the coupling of CPU, memory, and I/O often means customers have to swap out whole new machines just to upgrade one component that has run out of gas. It would be best to preserve as much investment in hardware and to change as little as possible to get the desired performance and density.
So in a sense, composable infrastructure will move in the other direction, breaking these components free from each other, we think by having a more generic kind of memory and I/O port on the die that can in turn reach out to different generations of memory and I/O in the system. To a certain extent, IBM is already doing this with its Power8 chip, which has a generic memory port on the die and specific electronics for supporting DDR3 memory on its “Centaur” memory buffer chip. IBM can put out an upgraded Centaur chip and support DDR4 memory pretty easily on exiting Power8 chips or future Power8+ or Power9 chips, but that does not mean IBM will construct servers in a modular fashion that will allow Power8 or future systems to do such a memory swap. (Obviously, it should do this as a competitive advantage.)
Interestingly, at the moment, the evolution of composable systems from the largely monolithic boxes that we see is not something that hyperscalers or HPC centers are already doing. As far as Todd Brannon, director of product marketing for Cisco’s Unified Computing System line, knows there are no homegrown machines being built by the Googles, Facebooks, and Amazons of the world that are using composable infrastructure techniques. This is one time when enterprises might get their hands on a technology around the same time as the hyperscalers and HPCers.
It All Started With Blades
To be fair, with the blade servers that first started appearing in commercial settings in the late 1990s from Compaq and Hewlett-Packard, which were separate companies back then, and a few years later from IBM, Hitachi, Fujitsu, and a few others that are gone like RLX Technologies, bunches of servers were grouped together and had some of their I/O virtualized and power and cooling shared across multiple server nodes. Blade servers simplified management of the devices and allowed for a certain amount of upgradeability for the infrastructure, too, and they found their niches. (Blades were used in the telecom industry long before they were commercialized for corporate datacenters, and telcos actually have standards that they make vendors adhere to for cross-platform compatibility of components. Imagine that.)
Modular machines, inspired by some of the dense packaging required by hyperscale and HPC centers, also found their place, with multiple independent nodes crammed into a single chassis and providing density and shared power, but independent networking. Converged systems like Cisco’s Unified Computing System, IBM’s Flex System (now owned by Lenovo), and variants of blade servers with virtualized networking from HP and Dell brought servers and networking together into a single management framework, and hyperconverged systems are running virtual SAN and virtual server atop clustered infrastructure.
The evolution has been towards every progressive integration at both the processor and across the server, storage, and network tiers in the datacenter. Oddly enough, composable infrastructure will not stop these kinds of convergence, but will make the underlying systems that comprise converged and hyperconverged systems more malleable.
Intel has been on the forefront of the composable infrastructure evolution, starting several years ago with discussions it had at various Open Compute Summits sponsored by Facebook to talk about the possibilities with silicon photonics linking various system components across the datacenter, across rows of machines, and within racks eventually – and we think probably across server components themselves at some point.
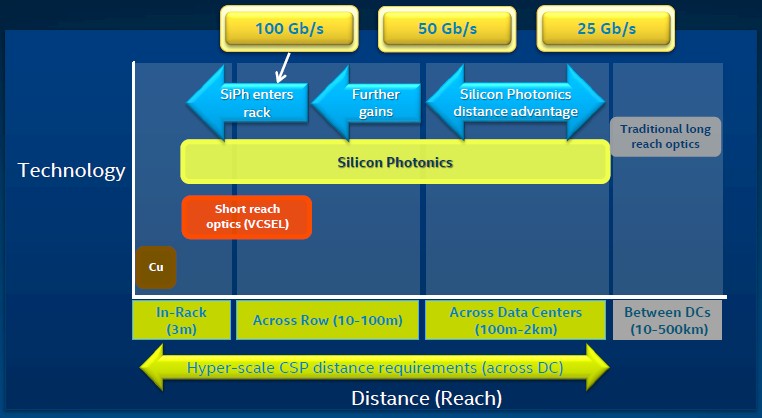
Why not use very fast light pipes to link blocks of CPU to blocks of memory, and make them reconfigurable? This seems logical enough, and keeping latencies low will be mandatory for composable server building blocks.
For now, as Alexis Bjorlin, general manager of the Silicon Photonics Group within Intel’s Data Center Group, explained at the company’s Data Center Day briefing with Wall Street back in late June, Intel is working on connectivity for hyperscale-class datacenters, providing connectivity that can span the 2 kilometer distances for linking servers and storage to each other. (Facebook’s North Carolina datacenter has two halls with 750,000 square feet of space, somewhere on the order of 120 megawatts of juice, and an estimated 120,000 servers, all of them linked together in a Clos network, as The Next Platform has discussed with Facebook networking director Najam Ahmad earlier this year.) Intel has created a silicon photonics module that runs at 25 Gb/sec and that can cram 16 channels of transmission and 16 channels of reception all running at that speed, for an aggregate of 400 Gb/sec both ways. This is four times the bandwidth of the fastest Ethernet and InfiniBand switching available on the market today.
Over times, Intel will boost the speeds on those silicon photonics channels, doubling to 50 Gb/sec at some point, allowing for this technology to be used across rows of racked up gear, and when it pushes the channel speed up to 100 Gb/sec it will be able to bring silicon photonics into the rack, linking components to each other. We think it will be composable infrastructure blocks, not individual servers, but that is our guess and Intel has said nothing about this.
What Bjorlin did say is that Intel is targeting switch-to-switch interconnects with its initial 25 Gb/sec silicon photonics, which have been delayed by approximately a year because the circuits were burning a little hot. The silicon photonics chips are sampling now, and will be in production next year, probably married to Intel’s own switch chip ASICs in some fashion. The precise timing for the speed bumps for future Intel silicon photonics were not divulged.
HP Enterprise, as the datacenter part of the former Hewlett-Packard is now known, is working on its own photonics and its own composable infrastructure, which is being done under Project Synergy and which is being done in parallel with its efforts to bring The Machine, its futuristic, memory laden system, to market. HPE is being a bit vague about the multi-year effort with Project Synergy, but generally speaking the idea is to create a new breed of system management tools that are like Google’s Borg or Microsoft’s Autopilot and that create and orchestrate a pool of physical, virtual, and container resources for compute and another pool of file, block, and object storage for data.
Having done the convergence thing with UCS, and added software from SimpliVity and Maxta to create hyperconverged infrastructure on top of that, Cisco is looking at the future with its modular UCS M Series machines and is working on how they can be converted to composable infrastructure.
“People are still very unfamiliar with this term, composable,” explains Brannon. “The M Series was our next step forward in disaggregation, but nobody cares about all of the servers being taken apart. They want to know what happens when you put Humpty Dumpty back together again, and here we are almost two years later, and composable infrastructure is still nascent in the industry as a concept. It is a fun time to be working with customers on this, because they see the potential in this. It is all about being able to match your infrastructure to a workload and being able to tailor it on the fly – the ultimate instantiation of software-defined infrastructure. There are two precursors for this to be realized: disaggregation of components, and a control plane and APIs to stitch it all back together again.”
The M Series machines came out in September 2014, and initially launched with server cartridges that had two single-socket Xeon E3-1200 v3 processors. The 2U UCS M4308 chassis held eight of these M142 compute cartridges as well as two UCS fabric interconnects, which provided virtualized network interface cards between the compute and the top-of-rack switches that linked out to other servers, storage, and the broader network. The M1414 server cartridge had a single Xeon E3-1200 v3 processor running at a higher frequency and were aimed at EDA and CAD workloads where clock speed matters more than anything. Both of these nodes topped out at 32 GB of memory, which is not much. This past summer, Cisco quietly launched the M2814 server cartridge, which packs two NUMA-linked Xeon E5-2600 v3 processors with up to 256 GB of memory, something that is suitable for a wider variety of compute workloads. Because of the dense packaging, Cisco is only supporting Xeon E5 v3 processors with eight or ten cores; the biggest of these “Haswell” generation of Xeons have 18 cores. Cisco has also launched an M-Series storage variant called the UCS C3260, which has a pair of two-socket Xeon E5 server nodes, each with up to 14 2.5-inch flash SSDs, plus a shared 60 3.5-inch SATA drives, all in a 4U enclosure.
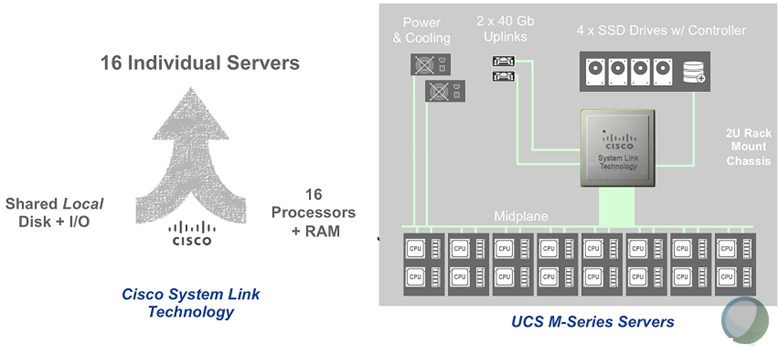
The secret sauce in the UCS M Series machines is a homegrown ASIC called System Link, which Cisco created to abstract away the I/O, networking, and storage inside the chassis, allowing different nodes to be allocated different capacities of these components. It does not virtualize using Single Root I/O Virtualization (SR-IOV), as is done in many systems today, but rather carves up the physical PCI-Express bus like Cisco does in the UCS machines for its virtual network interface cards. (Which predate SR-IOV, by the way.) System Link doesn’t just virtualize the network interfaces, but also creates virtual drives from RAID disk groups on the server and presumably will at some point be able to virtualize links between server enclosures and storage server enclosures like the C3260 that are linked to them. In the long run, when processors and memory are broken from each other by Intel, System Link will be able to virtualize compute and memory pools, too. Cisco cannot say because it is not at liberty to talk about what it knows about Intel’s plans.
What Cisco can tell you is that just having composability for network and storage using its M-Series iron can pay off bigtime:
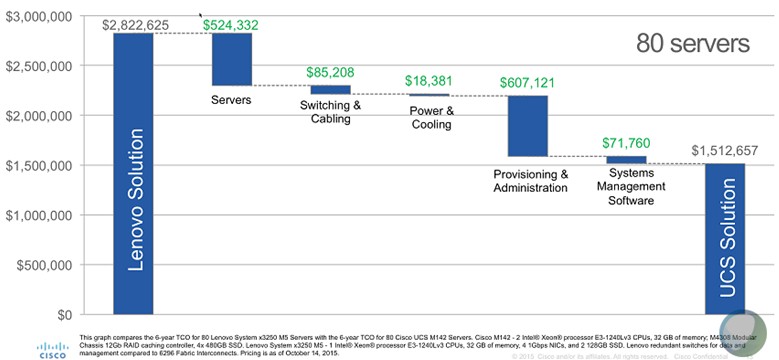
In the above comparison, Cisco is pitting forty of its two-node UCS M142 server cartridges against eighty of Lenovo’s single-socket System x3250 M5 servers, both of which are using the same Xeon E3-1200 v3 processors and each equipped with 32 GB of memory. This is a six-year total cost of ownership comparison that has initial server acquisitions and two processor refreshes. Because of shared components and power in the M Series chassis, Cisco can bring the server cost down considerably compared to having to swap whole servers twice with the rack machines. But as you can see, Cisco believes the big savings come from automated provisioning and administration through service profiles, a key aspect of the original UCS blade serves and the newer M-Series machines.
“There is an incredible CapEx component from not having to replace the entire server each time, but also an OpEx component, where you have your operations team pulling an entire chassis out and installing new ones every couple of years and recabling everything. By disaggregating processor and memory with System Link, you just have to replace the cartridge and you are not building new servers from scratch, you are just applying a service profile to set up the software. For operation at scale, we really think this is a superior approach to tackle the problem. There is just so much stranded resource in the datacenter with the monolithic approach.”
It will be very interesting indeed to see what a similar comparison will look like when companies can, some years hence, be able to upgrade processing and memory separately from each other when infrastructure is truly and completely composable. We suspect that companies will upgrade memory to avoid processor upgrades, but we will see. It will all depend on the bang for the buck for particular workloads for upgrading specific components.


If You Want To Maximize Enterprise AI, Don’t Just Focus On GPUs
Paid Post There’s no doubt that the repurposing of GPU silicon has accelerated the development of artificial intelligence technology over the last decade. But focusing exclusively on GPUs when building out your own AI infrastructure can leave you with a misleading picture of what your ecosystem should really look like. GPUs are …
The Highly Profitable Chip Making Monopoly Called TSMC
When Taiwan Semiconductor Manufacturing speaks, the datacenter sector of the IT industry listens because, with few exceptions, this foundry etches the compute, networking, and storage engines that power the datacenter. And the rest of the entire IT industry also listens, particularly the smartphone industry and a good portion of the …

Cache Is King
The gap between the performance of processors, broadly defined, and the performance of DRAM main memory, also broadly defined, has been an issue for at least three decades when the gap really started to open up. And giving absolute credit where credit is due, the hardware and software engineers that …
This idea is not exactly new.
Egenera tried this stuff in the past (15 years ago?) when they still manufactured own boards, to build distinct pools of resources decoupling CPU & memory from I/O and networking.
I agree. The Unisys ES7000 had composable IO via crossbar, compute with TLC and centralized main memory in 1999. Way more flexible than today’s rudimentary attempts. Blades and the new offerings from Cisco and Dell are hardly composable. These new offerings are just composable IO via SAS or FC. Let’s hope they don’t kill us with custom drivers, and low volume cheap, gear. Fail FAST Folks, Fail FAST 😉
That was a very good server design, wasn’t it?