

While there are plenty of distributed applications that are going to chew through the hundreds of gigabits per second of bandwidth per port that modern Ethernet or InfiniBand ASICs deliver inside of switches, there are still others that might benefit from having a more streamlined stack that is also more malleable and composable.
A number of vendors have proposed using PCI-Express to extend the reach of interconnect outside of the server skin. In one interesting twist back in 2011, NEC created ExpEther, which runs the PCI-Express peripheral protocol over standard Ethernet, using a software-based PCI-Express switch that runs on hosts, giving it the trustworthiness of PCI-Express and the reach and radix of Ethernet. Not much has happened with ExpEther since the 40 Gb/sec bump back in 2015, so this idea has not set the datacenter on fire. (But this could be a very interesting bit of software to offload to a SmartNIC, if someone wants to do that.)
The other logical thing to do is to just cut out Ethernet completely from the cluster and use PCI-Express switching to link servers and their peripherals to each other, and in most cases, this has been done with a layer of systems software that allows for the pooling of PCI-Express devices such as network adapters, GPU accelerators, FPGA accelerators, and NVM-Express flash drives.
Back in the early 2000s, in the wake of the establishment of the InfiniBand universal fabric from the merger of the Future I/O and Next Generation I/O projects, StarGen created the initial PCI-Express switch fabric. StarGen, which was acquired by Dolphin Interconnect in 2007, worked with Intel and Integrated Device Technologies to develop the Advanced Switching standard, and eventually the PCI Special Interest Group (PCI-SIG) that controls the Peripheral Component Interconnect standard, saw some merit in this and added Multi-Route I/O Virtualization (MRIOV) for sharing devices across many hosts. This laid the formal groundwork for PCI-Express switching.
PLX Technologies, which was acquired by Avago in the summer of 2014 for $300 million a year before Avago spent $37 billion to buy Ethernet switch and adapter chip giant Broadcom (and take its name in the bargain), was out there with the next generation of PCI-Express switch chips. A3Cube, another startup, came out with its own twist on PCI-Express switching later that same year. And the idea behind the PLX ExpressFabric and the A3Cube Fortissimo fabric was the same one that a new startup, called GigaIO, is now talking about many years later with some twists of its own. And here is that idea: With every peripheral and the CPUs all talking PCI-Express natively, why convert PCI-Express to Ethernet or InfiniBand at all? Why not just stretch PCI-Express fabrics as far as they can go out of the chassis and across the racks, interconnecting the CPUs, GPUs, FPGAs, and SSDs into pools of capacity that can be configured on the fly, and add things like congestion management and flow control to it, which it lacks. Why not?
As Scott Taylor, director of software development at GigaIO, explained in a session at the recent Hot Interconnects conference in Santa Clara, the overhead of those Ethernet and InfiniBand networking stacks is pretty high, as represented in this chart:
![]()
There have been many great advances in making InfiniBand and Ethernet better, and making flash run more natively and faster on PCI-Express, and these have certainly helped with getting the latencies down and systems back into balance. Remote Direct Memory Access allowed InfiniBand to radically remove latencies by letting systems in a cluster directly talk to the main memory in each system without having to go through the operating system stack. Ethernet added RDMA over Converged Ethernet (RoCE) to drive its own latencies down, and NVM-Express over PCI-Express (and now other fabrics that fan out from PCI-Express) stopped making flash drives emulate disk drives and speak their own native language to the PCI-Express bus. But what is obvious from this chart above is that the most efficient kind of networking is to eliminate protocols like Ethernet and InfiniBand from the stack wherever possible. Think of it as Interconnect-Express and you get the right idea.
Both the earlier PCI and PCI-X buses had Non-Transparent Bridging (NTB), which provides a point-to-point interconnect between devices and which creates a window into remote memory and I/O so the two devices can share data. It is, in effect, the leanest and meanest kind of RDMA. But PCI, PCI-X, and PCI-Express have all been limited by bandwidth and the availability of proper copper and optical cabling to extend distances between the devices. Both problems have been solved, and that is why PCI-Express switching across server and storage enclosures, and not just within them, could be poised for a breakout.
The cables, oddly enough, were as big of a problem as the bandwidth.
“This may sound stupid, but the PCI-SIG, at the urging of Facebook, finally approved external cabling and connectors that are modern,” Alan Benjamin, co-founder and president of GigaIO, tells The Next Platform. “Our very first prototype was done on what was their approved standard before, and it was awful. The cables looked like they were battery jumper cables and there is no datacenter in the world that was going to put those in their racks. But when the PCI-SIG approved the Mini SAS HD connectors, they look a little different from an Ethernet QSFP, but it isn’t awful and its up to date, cost competitive, and something that datacenter managers think they can use.”
The other thing that gives PCI-Express switching a better chance in the datacenter now than seven years ago is that a lot of the software that is necessary to make this all work has been encoded into Linux.
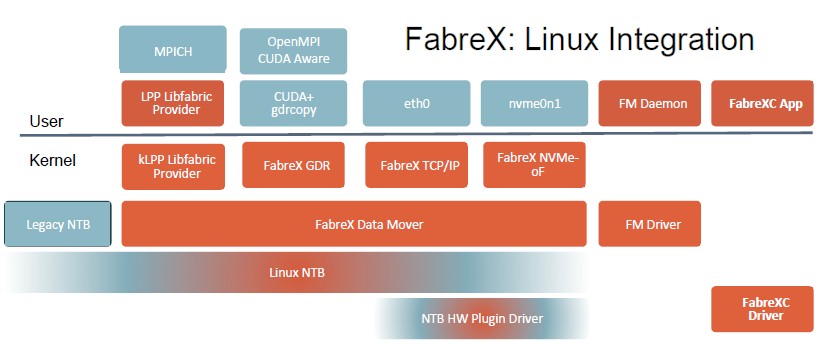
“The whole construct of virtual machines in particular has led over the last five years to some major additions to Linux to be able to support all that environment,” says Benjamin. “This Linux stack does a lot of what we need and we didn’t have to build any of it.”
It doesn’t hurt that PCI-Express bandwidth increases are no longer stuck in the mud, either.
The original PCI-Express 1.0 devices specified in 2003 delivered a raw 2.5 Gb/sec of bandwidth per lane each way, with about 20 percent of that eaten up by the encoding scheme. So an eight lane, or x8 device could deliver 2 GB/sec of throughput each way, but really only 1.6 GB/sec after encoding. In 2007, with the 2.0 spec, PCI-Express doubled up the raw bandwidth to 5 Gb/sec per lane kept the same encoding (thus delivering 3.2 GB/sec effective bandwidth both ways on an x8 link), and in 2010, because of thermal and other issues, the raw transfer rates were only increased by 60 percent to 8 Gb/sec, but with a radically more efficient encoding scheme where only 1.5 percent of the bandwidth was eaten up, an x8 device could deliver 7.88 GB/sec of bandwidth both ways and for fatter devices like GPU and FPGA accelerators, the x16 slots could double that up to 15.75 GB/sec.
The FabreX PCI-Express switches can configure ports at various data rates using the current PCI-Express 3.0 switches. The x4 setup delivers 32 Gb/sec, the x8 delivers 64 Gb/sec, and the x16 delivers 128 Gb/sec.
Here we are finally at the PCI-Express 4.0 generation, seven long years later, and we have finally doubled up that signaling to 16 Gb/sec, and the PCI-SIG is finally on the proper two-year cadence that networking technology needs to be on. So the PCI-Express 5.0 spec will be ratified soon with 32 Gb/sec signaling, and the PCI-Express 6.0 spec, with 64 Gb/sec signaling, is expected to be ratified in 2021. Products tend to appear about a year after the specs are out, and various peripherals cards like network adapters or NVM-Express flash drives tend to come out ahead of PCI-Express switch ASICs that implement the standards.
This lag between specs and switch ASICs is one of the reasons why the initial products from GigaIO are still using PCI-Express 3.0 switches and host adapters. But Benjamin says that a “steady supply” of PCI-Express 4.0 switch ASICs will be available by the end of this year or early next, and that is when the FabreX switch and adapters from GigaIO will be updated with the faster silicon.
What PCI-Express 3.0 lacks in bandwidth, lane for lane, compared to Ethernet and InfiniBand running at 25 Gb/sec or 50 Gb/sec or some years out 100 Gb/sec per lane, it makes up for with extremely low latency. It takes about 11 nanoseconds to do a port-to-port hop inside a PCI-Express 3.0 switch, says Benjamin, and about 50 nanoseconds to jump from a port on one switch to a port on a separate switch. This is considerably better than the 90 nanoseconds fro a port-to-port hop within a 100 Gb/sec or 200 Gb/sec InfiniBand switch or anywhere from 400 nanoseconds to 800 nanoseconds or higher on a port-to-port hop inside a 100 Gb/sec or 200 Gb/sec Ethernet switch.
More importantly, the latency running through the network stack on clustered systems is very high. Taylor explains that sharing these diverse elements inside of systems across an Ethernet or InfiniBand fabric requires data flowing through multiple protocols and doing multiple DMA transfers and making multiple memory copies in bounce buffers, and this adds up to a latency of 2,500 nanoseconds or more going from the memory of one device to another over that hybrid network. Using 96 lane PCI-Express 3.0 switches – GigaIO isn’t say which one it is using, but it is probably the PLX 8796 from Broadcom – that deliver 24 ports, rack-scale clustering can link devices point-to-point with latencies, memory to memory, of under 200 nanoseconds. Call it at least an order of magnitude better latency where it actually matters at this higher – and real – level.
The real question is how far do you want to stack up in a PCI-Express leaf/spine network, and also how do you want to carve up the bandwidth on future PCI-Express 4.0 and 5.0 switches. High radix – meaning ports per ASIC – might be as important than high bandwidth because that eliminates hops and therefore cost and latency across a network. It all depends on how much oversubscription – the ratio of downlinks to uplinks – you want to put into the network. At hyperscalers, that ratio is usually 3:1, so there is no reason not to do this with PCI-Express switching, like this:
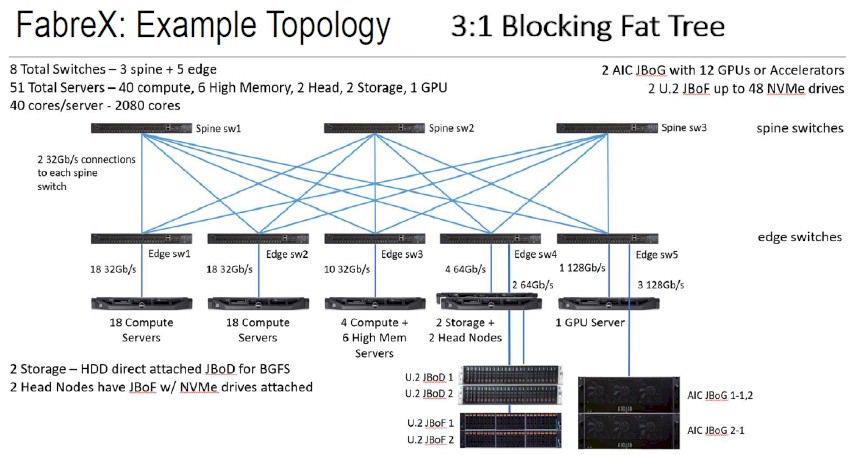
This fat tree topology has a total of 51 servers linked by eight switches. At list price, the 24-port switches cost $8,000 plus anywhere between $3,000 to $4,500 for the FabreX OS operating system; the FabreX host adapter cards list for $795 a pop. So all in with all the software bells and whistles, this FabreX network would cost $140,545. (Copper cables for the links will run another $75 to $100 each, and we are not counting these.) This is on par with what Ethernet or InfiniBand, with higher bandwidth (depending on how many lanes are aggregated for the FabreX links, will cost at list price, but the Ethernet and InfiniBand options have much higher point to point latencies. So what is that worth?
Taylor says that GigaIO can easily lash together 64 nodes and can add layers of switches to boost that to 128 nodes or 256 nodes “if they get creative.”
The real fun begins when PCI-Express 4.0 and 5.0 switches become available, and it is not clear what customers will do: Go for higher port counts and fewer switches or higher bandwidth. Benjamin thinks that with the PCI-Express 4.0 switches coming down the pike, customers will want to have 48 ports running at the same 32 Gb/sec using two lanes instead of four and with PCI-Express 5.0, that could double up again to 96 ports running at 32 Gb/sec or more likely shift to 64 ports running at 48 Gb/sec. We shall see.
For applications where latency is more important than bandwidth, PCI-Express switching can perhaps finally find its home across the racks and rows of the datacenter and not just as a bridge to GPU and FPGA accelerators in fat nodes. We might be skipping from the node and right over the rack to start talking about row-scale infrastructure soon.




There are some critical points missing from GigaIO reasoning:
1. Not all Ethernet ports need to travel the PCIe path (some come right off the CPU, next to PCIe lanes)
2. The number of developers with Ethernet/RoCE familiarity
3. The amount of already deployed Ethernet switching infrastructure in the data center