

We all expected that the Summit supercomputer at Oak Ridge National Lab would be a major part of pushing deep learning forward in HPC given its balanced GPU and IBM Power9 profile (not to mention the on-site expertise to get those graphics engines doing cutting-edge work outside of traditional simulations).
Today, researchers from Berkeley Lab and Oak Ridge, along with development partners at Nvidia demonstrated some rather remarkable results using deep learning to extract weather patterns based on existing high-res climate simulation data. This places the collaboration in the running for this year’s Gordon Bell Prize, an annual award based on high performance, efficient use of real-world applications that can scale on some of the world’s most powerful supercomputers.
We have written before about how deep learning could be integrated into existing weather workloads on supercomputers, but this particular piece of news captures the performance potential of integrating AI into scientific workflows.
The team made modifications to the DeepLabv3+ neural network framework to extract pixel-level classifications of extreme weather patterns and demonstrated peak performance of 1.13 exaops (not flops or floating point operations per second, which is the basis of the exascale classification metric) and sustained performance of 0.999 exaops.
We will follow up with much longer pieces early next week with Prahbat and Thorsten Kurth, both of whom are contributing authors on the work. In a very brief interview today, Prabhat told The Next Platform that indeed, the exaop performance is quite different from exaflop and while exascale performance barriers have been achieved, the important difference is that the work was achieved using half-precision on the Nvidia Volta TensorCore, which is key to the performance.
If you’ll recall, last year at the Supercomputing Conference, IBM and Nvidia made the claim that they could achieve exaops on the Summit supercomputer—a striking figure, and one that the team came close to using almost the entire machine. Kurth tells us they used 4560 nodes (and all 6 GPUs/node) out of 4608. This was almost all of the machine and the stable fraction of nodes we could rely on. I think fair to say is that we ran on about 99% of the machine (there is always some dropout on these large systems).”
“What is impressive about this effort is that we could scale a high-productivity framework like TensorFlow, which is technically designed for rapid prototyping on small to medium scales, to 4,560 nodes on Summit,” he said. “With a number of performance enhancements, we were able to get the framework to run on nearly the entire supercomputer and achieve exaop-level performance, which to my knowledge is the best achieved so far in a tightly coupled application,” says Thorsten Kurth, an application performance engineer at NERSC.
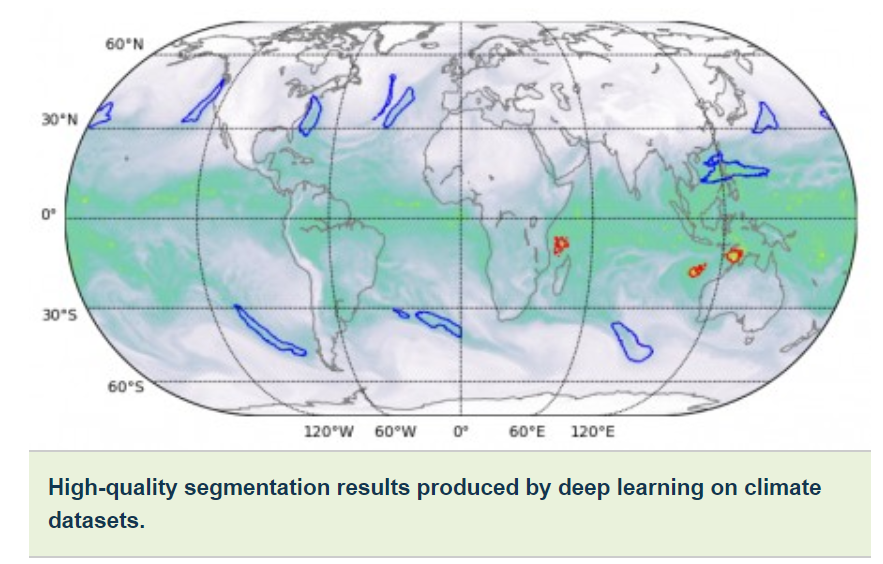
Other innovations included high-speed parallel data staging, an optimized data ingestion pipeline and multi-channel segmentation. Traditional image segmentation tasks work on three-channel red/blue/green images. But scientific datasets often comprise many channels; in climate, for example, these can include temperature, wind speeds, pressure values and humidity. By running the optimized neural network on Summit, the additional computational capabilities allowed the use of all 16 available channels, which dramatically improved the accuracy of the models.
“We believe that field of deep learning is poised to have a major impact on the scientific world. Scientific data requires training and inference at scale, and while deep learning might appear to be a natural fit for existing petascale and future exascale HPC systems, careful consideration must be given towards balancing various subsystems (CPUs, GPUs/accelerators, memory, storage, I/O and network) to obtain high scaling efficiencies. Sustained investments are required in the software ecosystem to seamlessly utilize algorithmic innovations in this exciting, dynamic area.”
The full paper, which we believe presents evidence that this will likely be Gordon Bell prize winning work, can be found here.




Be the first to comment