
Sometimes, if you stick around long enough in business, the market will come to you.
For decades, Xilinx was the leader in field programmable gate arrays and still owns about 60 percent of the market. Intel, with its $16.7 billion acquisition of FPGA rival Altera almost three years ago, holds the bulk of the rest of the market. While Xilinx has seen steady growth over the years – it hit a record $2.54 billion in revenue for its fiscal 2018, an 8 percent jump from the previous year – FPGAs are still just beginning to find their footing as compute engines in their own right within datacenters. CPUs from Intel, AMD, and IBM are still the primary drivers of compute, with the help of GPU accelerators from Nvidia and AMD and a hopeful Arm collective hoping to get in on the action, led by Cavium. Increasingly, other accelerators – like FPGAs and custom ASICs – are being used, but right now it is still largely a CPU dominated datacenter.
Nonetheless, Victor Peng, a ten-year veteran of Xilinx and, since January, its chief executive officer, sees this changing and envisions a time when the programmable pieces of silicon are what’s driving much of the computing in HPC centers, among hyperscalers and cloud builders, and within regular enterprise datacenters.
There are shifts underway in computing that are driving the need for more heterogeneous computing that can adapt to the workload at hand without having to change any of the underlying infrastructure. In particular, more endpoints from the core out to the network edge and into the cloud are becoming connected and are being infused with intelligence through sensors, cameras and other devices, and they are creating massive amounts of mostly unstructured data. That data is driving demand for more computing and more storage, and for the use of technologies like artificial intelligence (AI) and machine learning to drive better insights and decisions from it.
As we have talked about at The Next Platform, FPGAs are generating interest around machine learning and deep learning, and Xilinx added to its portfolio this summer with the acquisition of startup DeePhi, whose work centered on neural networks and FPGAs.
“This intelligence, it’s all fully connected, it’s really happening and it’s in really, really early days, especially from the perspective of today that intelligence means there’s not only some sort of processor at some level – in many cases an SoC – but also because all these applications have some form of artificial intelligence, typically machine learning of some form, also being integrated,” Peng said during his keynote at the Hot Chips 2018 conference in Silicon Valley. “The reason this is so exciting is because it has not only already had an impact on people’s daily lives, but because it’s only emerging and it’s going to have really profound impacts on people’s lives because change is happening at an exponential rate.”
Peng noted that some predictions are putting the amount of data at more than 10 zettabytes per year in the near future, and “getting some sort of value out of that usually means processing it and in some form extracting that information from just the raw data and that’s driving a strong growth rate in the number of servers in hyperscale datacenters. Datacenters are being scaled out more significantly than we have ever seen, the computation and storage and memory are increasing and the capabilities so far have been able to keep up if you look at the processing and total storage in that space that is moving at an exponential rate.”
(It is funny to think that this is all fueled by advertising dollars in one form or another among the hyperscalers and from raw infrastructure services among the cloud builders.)
However, there’s a big “but” in this scenario, and that’s Moore’s Law, what Peng called “one really, really big existential challenge.” The Moore’s Law shrinking in the size of transistors and the ability to pack more of them into a given area to produce more function and lower cost, has been serving the industry very well for five decades and now is running out of gas.
“This is what’s ingrained in all of us, even out of tech, everyday consumers, is to expect faster and cheaper,” he said. “Every year, everything electronic in nature, we’ve had this expectation that it really was a physical law that the products, for the same price, would get so much more capable and better, so it’s pretty profound when we say that this engine is no longer working for us.”
Chip makers over the years have pulled a lot of levers to keep pace with Moore’s Law, including adding more cores, driving threading within those cores, and leveraging accelerators. But Peng said making systems faster and better was not only achieved through processor technology, but also through architecture. Architectures have their own challenges, particularly power and density, which also are limiting performance.
“For the past 40 years, compute was focused on CPUs and microprocessors,” Peng said. “That started running out of gas in the 2000s. Since 2010, things started moving toward heterogenous systems, where the computing was split between the general purpose processor and what you can broadly call fixed-hardware accelerators. That could have been a GPU or an MPU, and certainly there’s been a resurgence of ASICs, particularly around machine learning.”
Machine learning and other modern workloads, as well as the proliferation of connected, intelligent devices – tens of billions, working their way up to hundreds of billions – is driving new rounds of investments in silicon technologies and the demand for hardware platforms that are configurable and adaptable. Heterogeneous architectural design will be the key to driving performance going forwards. With machine learning and all those connected devices and systems, “you just cannot have that be fixed, because you can’t predict what all the needs are going to be when you deploy this, and you don’t want to have to deliver capabilities to that infrastructure by changing physical devices” Peng said. “This notion of being able to change not only at the software level but at the hardware level vast intelligent devices remotely is becoming more and more powerful and absolutely needed in order to realize this future.”
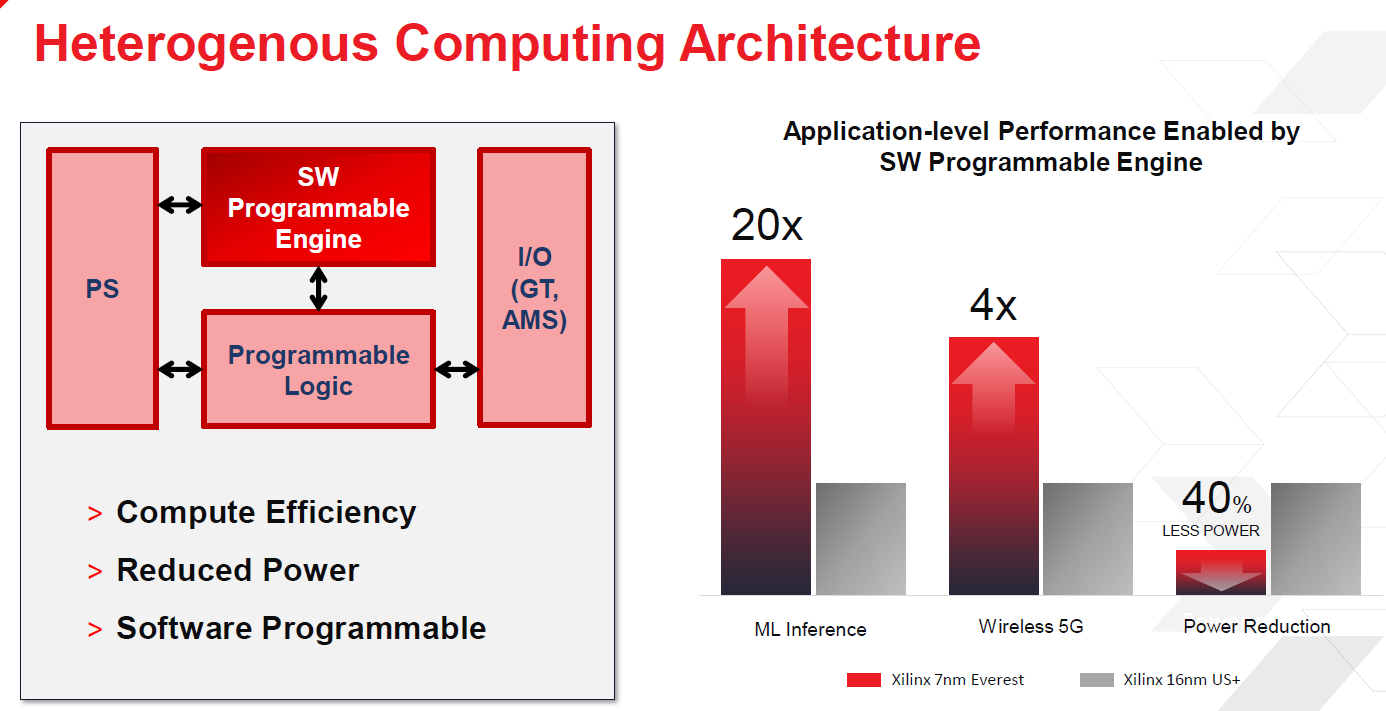
At Hot Chips, Peng and other Xilinx officials in presentations spoke about what the company has coming up, including its upcoming Adaptable Compute Acceleration Platform (ACAP) and 7 nanometer “Everest” SoC. Xilinx first talked about ACAP in March, and while there wasn’t a huge deep dive into the platform at Hot Chips – that will most likely come at the Xilinx Developer Forum in October – Peng did spend some time on it. Xilinx says that ACAP will bring 20X the performance in machine learning inference of the company’s current 16 nanometer FPGA and 4X the performance in 5G networking. The Everest SoC will tape out later this year on Taiwan Semiconductor Manufacturing Corp’s 7 nanometer process.
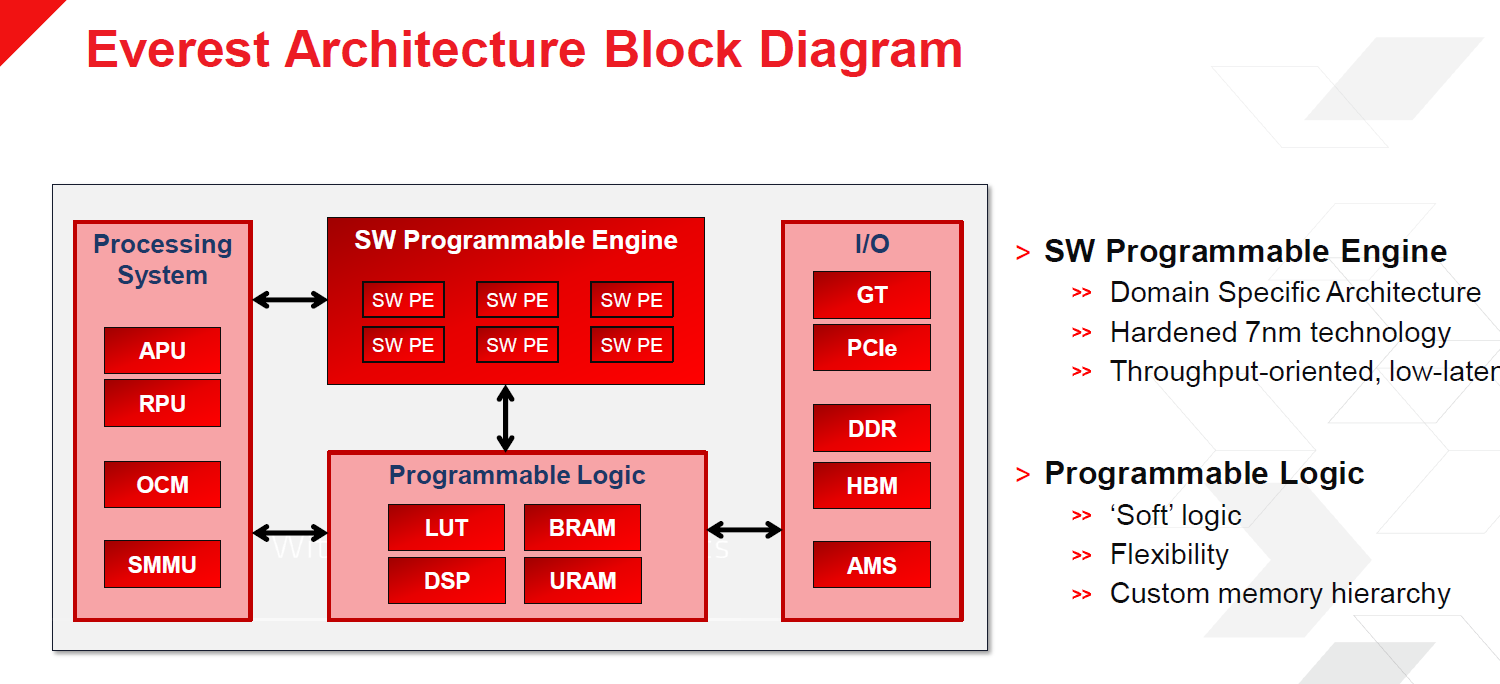
ACAP is all about adaptability and programmability. The platform’s Programmable Engines will initially handle machine learning inference and 5G networking workloads. At the core of the architecture are arrays of tiles that each feature an interconnect and local memory with extensions that can target particular applications. Xilinx will offer a number of SKUs that will be aimed at a broad array of markets. Programmable logic will include DSPs, LUTs, URAM, and BRAM. In keeping with Peng’s vision, the architecture will allow users to program the architecture to best address applications needs. This enables organizations to essentially deploy the same silicon for different workloads.
“It will make the capability to swap kernels and DSAs in and out more rapidly with fewer design restrictions around that,” Peng said. “It is multi-market. There is a lot of discussion about datacenter and cloud, but because of its flexibility and depth, it will serve all markets. The architecture is scalable, so it will be in automotive applications, it will be in cloud applications, and in things in-between – communications, infrastructure. And it will absolutely be software programmable from the get-go, but underneath that of course it will be hardware programmable.”
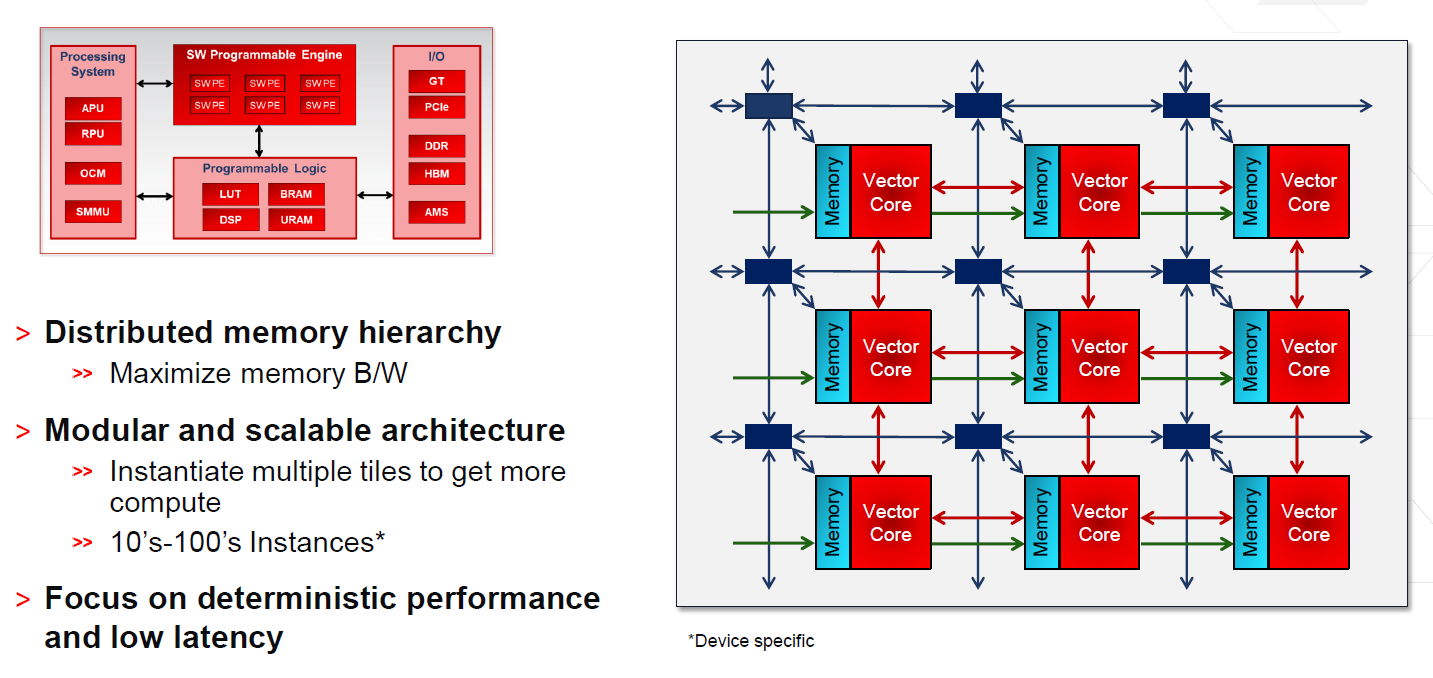
It also will lead to higher throughput, lower latency and lower power, all of which are as important as frequency when talking about modern workloads.
“These days, especially because of the focus on machine learning, we’re getting into this frenzy about TOPS,” said Peng. “This absolutely reminds me of the Megahertz Wars in the 1990s. It’s really not what matters. What matters is the application acceleration. We’re running these things at generally hundreds of megahertz or around a gigahertz or so as opposed to multiple gigahertz, and a lot of it is because, with the generally adaptability of our architecture, we have a lot of distributed on-chip memory and the connectivity of that, and even the configuration of some of that in terms of ports, can be customized. You can not only optimize the data path and the data flow, but you can optimize the memory hierarchy as well as the bandwidth, and there’s massive amounts of on-chip bandwidth.”


AMD Girds For Compute War With Xilinx Deal
The rumors were right, and AMD president and chief executive officer Lisa Su is indeed printing out a tower of stock to acquire FPGA maker Xilinx for what amounts to about $35 billion and, as it turns out, she is relinquishing her position as president to Victor Peng, chief executive …

The Ticking And Tocking Of Intel’s “Ice Lake” Xeon SP
It has been a long time since Intel changed its manufacturing process – what it used to call a “tick” – and the microarchitecture and architecture of a processor design – what it used to call a “tock” – at the same time. But with the fourth generation “Ice Lake” …
Tuning The FPGA For Clouds And Comms
It has been a long time since plain vanilla programmable logic circuits known as field programmable gate arrays have been available in a raw form. For many years, Xilinx, Altera, and others making what we call FPGAs have been adding hard-coded circuits for certain functions that might otherwise be synthesized …
One wonders what the market position would be if Xilinx and AMD would merge under the AMD banner and compete in a similar manner to Intel/Altera. AMD would still have its GPU IP and CPU IP and then some and AMD does have a patent pending for FPGA compute right on the HBM/HBM2/Newer HBM# stacks.
AMD after all is the one along with SK Hynix that is responsible for the now JEDEC HBM/HBM2 standard.
Well, yes. Add in Mellanox and you have a real contender.