
Enterprises that want to leverage the huge amounts of data they are generating to gain useful insights and make faster and better business decisions are going to have to use machine learning at scale for modeling and training. It’s commonplace among hyperscalers like Google, Amazon and Microsoft, and larger corporations are rapidly embracing the technologies. However, it’s not easy for enterprises, which often don’t have the manpower or the money to venture into artificial intelligence in a big way. The algorithms are there, but it’s expensive to train and deploy the models in any sort of scale.
GPUs, with their parallel processing capabilities, have helped bring down the costs and the time it takes to train a model to within reach of some enterprises, but often they have not been brought down enough. The algorithms needed for machine learning and training models are coming into place, according to Mathew Lodge, senior vice president of products and marketing at data science platform provider Anaconda. Many of these algorithms are better than humans at such tasks as image recognition and medical analysis. However, the compute power needed to train these models is large and growing. ImageNet is trained using 14 million images, Lodge tells The Next Platform. AI models need to scale by factors of at least 10X each year.
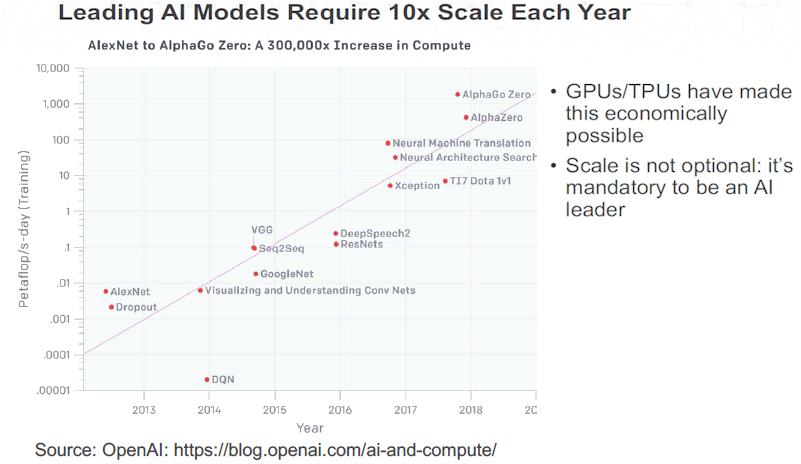
“That’s why GPUs are important, because if we want to do leading-edge AI, you need to use GPUs to make it economically viable to do so,” Lodge says. “The challenge for most enterprise organizations is they’re coming off ten or twelve years of big data, and big data has meant sending files distributed throughout the system, [with] MapReduce as sort of the dominant paradigm for doing parallel computations and addressing datasets that won’t fit in memory. The challenge there is this: First of all, MapReduce is not a good fit for the way machine algorithms work. They don’t fit well with that style of computing. Secondly, big data is very Java-centric, so it’s great if you’re writing in Java but if you’re not – and most data scientists are writing in Python or R – suddenly it gets very clunky. It’s also very expensive.”
HDF storage can cost as much as $100 per TB, he said, while cloud-base storage like Amazon Web Services’ S3 can cost $20 per TB.
“Most enterprises are trying to figure out, ‘How can we do what Google does? How can we train something like Alpha Go 0?’” Lodge says. “Google does that with containers and something that looks very much like Kubernetes. Enterprises want to take advantage of the shift that’s going on and do what Google does, and do what Amazon does and do what Microsoft does inside their own organizations with their own data.”
Anaconda has been building out its Python-based Anaconda Enterprise platform – it also supports R – with capabilities to make it easier for enterprises to adopt machine learning and AI technologies within their own environments. Anaconda is among a broad array of tech vendors that are looking to open up AI for broader adoption among enterprises. For Anaconda, that includes leveraging GPUs, technologies like Docker containers and Kubernetes and libraries and toolkits like TensorFlow, H2O.ai and MXNet to reduce complexity and costs. The vendor this month rolled out version 5.2 of the data science platform that includes support for GPU clusters through the latest GPUs from Nvidia and that latest version of Kubernetes, which includes improved support for GPUs. There’s also improved support for Docker containers, automated job scheduling and the integration of existing source code control systems and continuous integration tools like Bitbucket and Git.
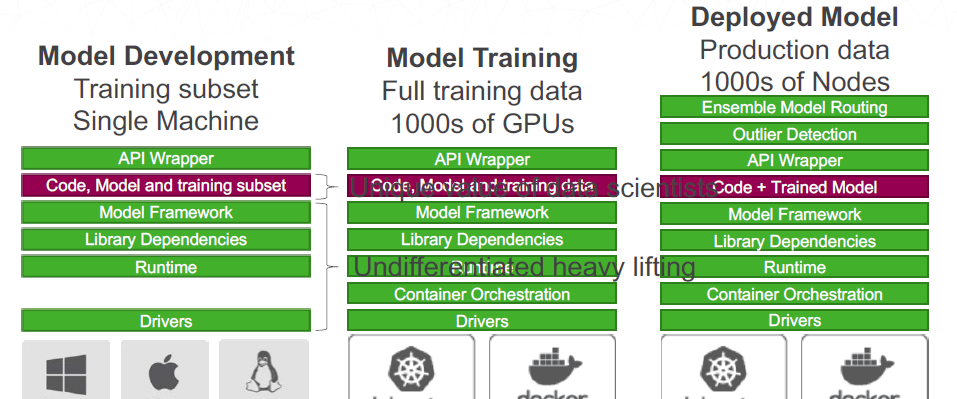
The platform makes it easier for data scientists to use GPU clusters that run in self-managed environments, and to scale their machine learning models from their laptops to the GPU clusters without having to make changes to the code. Most data scientists do model development in-memory on their laptops. It’s there where they decide the components they’ll use, whether it’s TensorFlow or XGBoost or something else. However, once the model has been selected, they need to train it using the entire dataset, which can’t fit into memory, so it needs to move to the cluster. Organizations can use the open-source Dask software to parallelize Python programs or use libraries like TensorFlow that are parallelized at the start. Once deployed and in product, the tasks of running and managing the model – such using containers and Kubernetes, scheduling, security, and upgrades – are automated.
Anaconda has about 6 million users, and its list of customers includes major corporations like Ford, BMW, HSBC, and Cisco Systems; Citibank is both a customer and an investor, using the technology for both fraud detection and credit card risk management. The concentration in customers now is in the financial services, manufacturing and federal government verticals, Lodge says, adding that he expects to see AI and machine learning continue to cascade into enterprises due to the prevalence of APIs, containers and Kubernetes and other cloud-native technologies.
“The advent of scale is what’s really going to make machine learning more applicable or easier for your average enterprise IT organization to take advantage of,” Lodge says. “Deploying at scale is very difficult today and that’s why they haven’t done very much of it. New technologies like containers and Kubernetes make that a lot easier to run those things at scale. The other thing that’s going to be interesting is more sophisticated model management. All of our focus today is on training – the middle step in the process – because training takes so long and requires so much CPU power. You have to learn how to access the data and all these other things and there’s a lot of hard problems in there. But serving the models themselves and being more sophisticated about how you upgrade a model or deal with different versions or having multiple competing models is going to get a lot more attention in the future.”
The more sophisticated management will mean better results, according to Lodge.
“You might have one model that’s 75 percent accurate in one prediction and you’ve got a competing idea from another data scientist,” he says. “They think about it differently. You can run the two models in parallel, almost like a competition, and maybe it turns out that the second model is 90 percent accurate, but then its accuracy also drifts over time. The model can become less accurate because maybe it hasn’t been retrained on the latest data. Actively managing models and their accuracy and keeping them up to date has a lot of upside.”

Is Mojo The Fortran For AI Programming, Or More?
When Jim Keller talks about compute engines, you listen. And when Keller name drops a programming language and AI runtime environment, as he did in a recent interview with us, you do a little research and you also keep an eye out for developments. The name Keller dropped was Chris …

Python Delivers Big On Complex Unlabeled Data
A collaboration of researchers from the University of California Davis, the National Energy Research Scientific Computing Center, and Intel are working together on the DisCo project to extract insight from complex unlabeled data. DisCo is short for the Discovery of Coherent Structures, and it discovers the inherent structures in unlabeled …

Coiling Python Around Hybrid Quantum Systems
At this nascent stage of quantum computing, each of the limited hardware/device makers have their own software stacks. As the ecosystem evolves and early use cases prove out, there might be a more accessible, generalizable way to interface the quantum and traditional computing worlds: good old-fashioned Python. After all, if …
Be the first to comment