

Despite some of the inherent complexities of using FPGAs for implementing deep neural networks, there is a strong efficiency case for using reprogrammable devices for both training and inference.
There has been much written about the role of FPGAs within key frameworks like TensorFlow but until more recently, this has been tougher than with GPUs because of the RTL transformation of the code within vendor specifications.
The dream end state for FPGA makers is to be able to automate or abstract so much of the FPGA part of the deep learning workflow that users care only about their performance, but that is still far off. Even still, there is some hope on the horizon for those who want a higher level set of tools to prototype and experiment.
A team of researchers from the University of British Columbia have grabbed Google’s XLA compiler which can spit out LLVM code directly from th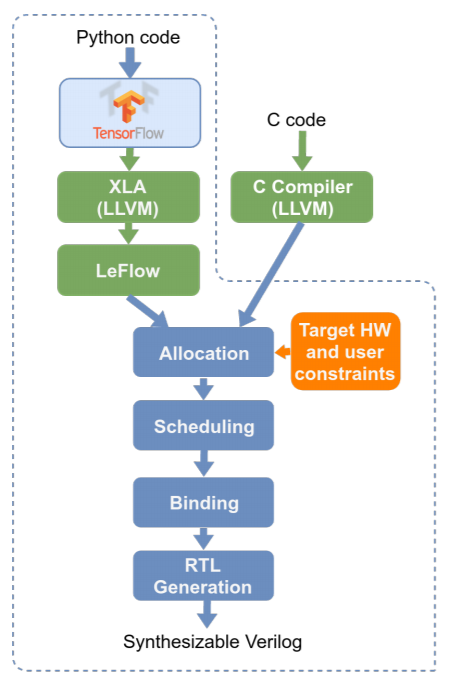 e TensorFlow specifications and then be used to realize the device. This all happens with minimal Python code and with noteworthy results, which means Python developers can test out machine learning problems on FPGAs without going through the labors of a hardware design process or using hardware directives.
e TensorFlow specifications and then be used to realize the device. This all happens with minimal Python code and with noteworthy results, which means Python developers can test out machine learning problems on FPGAs without going through the labors of a hardware design process or using hardware directives.
If this work (called LeFlow) sounds familiar it is because we have covered some much earlier efforts, most notably Caffeine (for the Caffe framework) but others, including this toolkit from Intel are also available.
Projects like LeFlow are all worth following since they will either make or break the future of FPGAs for this emerging set of workloads. But as with so many things in reconfigurable computing land, nothing is easy, even if the performance or efficiency rewards are great. The team has succeeded in making a more portable tool to generate LLVM but what they automate gets rather hairy.
LeFlow generates LLVM IR and they use this as input for the HLS side. However, due to “mismatches between the XLA IR output and requirements of the HLS tool, significant transformations are required to ensure a seamless flow.” This is where much of the in-depth work is focused.
The team says LeFlow “may suffer somewhat in terms of throughput or power compared to a hand-optimized hardware design, the advantage of a rapid prototyping path may be compelling for a large number of design scenarios, and may open the door for hardware acceleration to many domain experts.”
Even if it is not the automagical tool to bring FPGA deep learning to the masses, it does open the door for more developers who want to toy with the performance and process—and at this point in the game, that matters.
Since one of the best prototyping environments is on the cloud, it would be particularly useful to use this approach could be applied to the F1 instances on Amazon. The team notes that since the commercial HLS tools are based on LLVM, FPGA hardware vendors could migrate the flow they have developed into their systems. LeFlow has been demonstrated using the LegUp synthesis tool.


Intel To Amp Up Security With “Ice Lake” Xeon SP Servers
Security is one of those necessary things that should not be an afterthought, but often is, and ideally is so invisible that it doesn’t get in the way of applications and the infrastructure it runs on. Speaking very generally, the cost of security has been so high on servers that …
Xilinx Keeps Pushing Programmable Logic As It Awaits AMD Takeover
The top brass at FPGA maker Xilinx are not hosting calls with Wall Street because of the pending $35 billion acquisition of the company by AMD, so we are left to get our own insight out of the financial report and accompanying statement that Xilinx has released for its latest …
The Inevitability Of FPGAs In The Datacenter
You don’t have to be a chip designer to program an FPGA, just like you don’t have to be a C++ programmer to code in Java, but it probably helps in both cases if you want to do them well. The trick to commercializing both technologies – Java and FPGAs …
Be the first to comment