

The use of FPGAs in HPC is limited less by the capabilities of current hardware and more by the challenges in programming them without sacrificing performance.
Recent work from Boston University has shown that with key optimizations that leverage OpenCL on Arria 10 FPGAs for 3D fast fourier transforms (FFTs), a common HPC workload, the performance can beat out FFT specific IP cores as well as GPU and CPU implementations of the same problem.
The team has implemented a broadside Radix-2 FFT module on a single FPGA. By using a set of code structure optimizations, the compiler takes advantage of the inherent flexibility of the FPGA to discover all angles of parallel. The compiler than hands the code off to HDL where the team can isolate compute pipelines from the remaining OpenCL system to addresses any limitations in the language that prevent realizing the data structures fully. This logic is then moved into the existing 3D FFT shells that were originally built for IP cores.
The research team uses Altera OpenCL for its work, which does have some limitations that they have tried to address with their OpenCL-HDL approach. They avoid using a full OpenCL generated system given language compatibility issues, the overhead of the board support package, and the problem of porting legacy codes to OpenCL from TRL. The team also notes that partial reconfiguration limits the board area where new logic can be implemented, which makes it tough to handle larger designs.
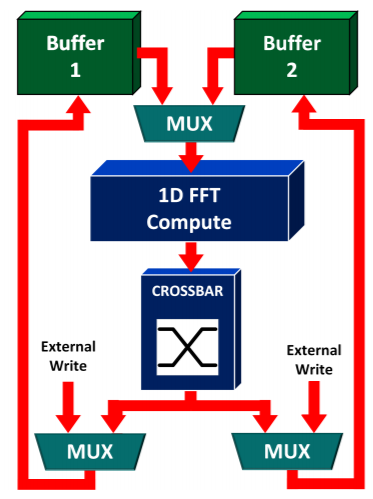
“Both OpenCL-HDL and IP core based designs can utilize the same shell for performing a 3D FFT. Consequently, the former can be seamlessly integrated into existing logic initially designed for the latter. Since FFT is a linear operation, a high dimensional FFT can be broken down into a series of 1D directional transforms in any order.”
“In order to avoid constructing complex and expensive memory structures that can stream data every cycle in all dimensions, a transpose is performed on the overall directional FFT result to reorder data within buffers. This reordering rotates the grid and allows a different directional 1D FFTs to be performed for the same data access pattern.”
In this work the OpenCL code is compiled using Altera OpencL SDK v16.0.2. The IP Core used is the Altera FFT IP core. The CPU code is implemented on a fourteen-core 2.4 GHz Intel Xeon E5-2680v4 with ICC compiler and MKL DFTI. The GPU used is NVIDIA TESLA P100 PCIe 12GB. It has 3584 Cuda cores and peak bandwidth of 549 GB/s. FFT code is written using cuFFT library and compiled with CUDA 8.0.
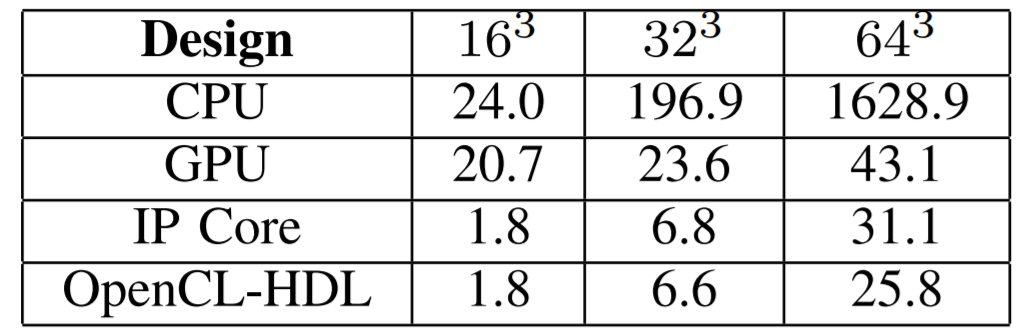
Results above show that the average speedup achieved is 29x vs CPU-MKL, 4.1x vs GPU cuFFT and 1.1x vs IP Core FFT.
Full details about optimizations found here.

Intel To Broaden FPGA Lineup And Make Them At Home
Back in 2015, when Intel was flush with cash thanks to a near-monopoly from X86 datacenter compute, it shelled out an incredible $16.7 billion to acquire FPGA maker Altera because a few hyperscalers and cloud builders were monkeying around with offloading whole chunks of CPU compute to FPGAs to create …

Intel To Set Its FPGA Unit Free To Pursue Its Own Path
Maybe Intel chief executive officer Pat Gelsinger has spent too much time at EMC and VMware. Because now Intel wants to spin out the FPGA business that is a small but bright spot in its datacenter and edge computing businesses. It never made a lot of sense that EMC, the …

Programming In The Parallel Universe
This week is the eighth annual International Workshop on OpenCL, SYCL, Vulkan, and SPIR-V, and the event is available online for the very first time in its history thanks to the coronavirus pandemic. One of the event organizers, and the conference chair, is Simon McIntosh-Smith, who is a professor of …
Why is there no publication date on the paper?
When will the arria 10 dev kits have a reasonable price drop to around 99 to 220 euro ?