
For decades, the IT market has been obsessed with the competition between suppliers of processors, but there are rivalries between the makers of networking chips and the full-blown switches that are based on them that are just as intense. Such a rivalry exists between the InfiniBand chips from Mellanox Technologies and the Omni-Path chips from Intel, which are based on technologies Intel got six years ago when it acquired the InfiniBand business from QLogic for $125 million.
At the time, we quipped that AMD needed to buy Mellanox, but instead AMD turned right around and shelled out $334 million to buy microserver maker SeaMicro, which had its own interconnect but not one suitable for HPC as we know it, and Intel almost immediately went out and bought the “Gemini” and “Aries” HPC interconnect business from supercomputer maker Cray for $140 million. In July 2011, Intel snapped up innovative Ethernet chip maker Fulcrum Microsystems for an undisclosed sum, which started off its buying spree.
At the moment, Omni-Path is an InfiniBand-derived networking technology with a proprietary protocol that uses an onload model, meaning a lot of the networking jobs are pulled onto the processors of the cluster and are not done by the switch; Omni-Path also borrows some technology from the Aries interconnect with the Omni-Path 100 Series, which debuted in November 2015 and which, as the name suggests, runs at 100 Gb/sec. With the future 200 Series, which was expected to debut this year in the original “Aurora” Knights Hill supercomputer slated for Argonne National Laboratory, Intel is moving to 200 Gb/sec speeds and will incorporate more goodies from Aries. We have also heard through the grapevine that this Omni-Path 200 will offer more offload of functions, as Mellanox does with its InfiniBand switches.
The current “Switch-IB 2” EDR InfiniBand from Mellanox runs at 100 Gb/sec, but the impending “Quantum” HDR InfiniBand, which will be available in August or September if all goes according to plan, runs at 200 Gb/sec and will have even more offload of network processing from the CPUs in the cluster to the server adapter cards and the switch ASICs. Mellanox also has a fast-growing 100 Gb/sec Ethernet “Spectrum” chip and switch business, and the “Spectrum-2” chip will double the speed up to 200 Gb/sec with some of the same signaling tricks used with the InfiniBand chips. Mellanox has a path to 400 Gb/sec and is looking ahead to 800 Gb/sec, keeping the pedal to the metal. Intel has been mostly quiet about Omni-Path, and has not said anything about its plans with the Fulcrum Ethernet chips or Ethernet in general. Intel may not be in a mood to try to take on Broadcom, the market leader for Ethernet switch chips in the datacenter, but Mellanox has been and it has been able to take away some share here. In fact, the success that Mellanox has had in this regard would usually goad Intel into action with Ethernet, but thus far, it has stuck to pushing Omni-Path in HPC and AI niches and left the broader Ethernet market to Broadcom and upstarts like Barefoot Networks, Marvell (which will soon own Cavium and therefore the XPliant switch chips), and Innovium.
For the sake of simplification, we consider Omni-Path a flavor of InfiniBand, and considering that the drivers created by the OpenFabrics Alliance for InfiniBand work on Omni-Path as do the applications that ride above them, this seems reasonable to us. QLogic InfiniBand was always distinct from Mellanox InfiniBand, so this is not new, and neither is the intense rivalry between these two flavors of this HPC networking scheme which has made its way in to storage, database, and other kinds of clusters.
What got us to thinking about the rivalry this week was a brief announcement by Mellanox that a weather research institute in China – which Mellanox did not name – had switched from Omni-Path to InfiniBand networking because it was dissatisfied with the networking performance of Omni-Path. (More on this in a moment.) We did quick search to find out more, and this benchmarking test blog from Intel popped up at the top of the list, and it was in fact a response to a story we had written last November about some comparative benchmarks that Mellanox had done pitting EDR InfiniBand against Omni-Path 100. This post by Joe Yaworski, director of high performance fabric marketing at Intel, was exactly the kind of response we were looking for. But the funny bit was that Intel never reached out to tell us it made any response at all, which it did in early January. This is peculiar, to say the least, considering we actually tried to compel Intel to respond to what Mellanox was saying about the relative performance of the two networks on HPC jobs.
That initial story focused on some benchmark tests that Mellanox did showing the performance of the two networks running ANYSYS Fluent, LS-DYNA, and VASP, three popular HPC applications that can spread across cores within a node and across nodes in a cluster to boost their performance. Yaworski started off by pointing out that ANSYS Fluent performance was very dependent on memory bandwidth, and to such an extent that a 32-core machine as Mellanox showed would do better than a 36-core machine that Intel also showed, and he also said that Fluent scaled better across nodes than it did within nodes because cores had to share the same memory bandwidth inside of a box – more cores chewing on the same bandwidth can dramatically lower performance. The implication is that a node with fewer cores can do better with Fluent, and then scaling the application across a cluster can boost it even further. The trick with Fluent, it seems, is to get the right number of cores for the memory bandwidth available and then scale replicas of that node.
Mellanox was reacting to benchmarks done by Intel, which showed Omni-Path 100 having a 17 percent performance advantage on a 64 node cluster compared to EDR InfiniBand on the same iron. Yaworski says that he does not know where Mellanox got these benchmark results from inside Intel, and implies that if the same 32-core machines were used running Omni-Path 100, we might see the same performance because the memory bandwidth and compute capacity for Fluent were balanced right.
In its own labs, here is the results that Intel got using clusters of Xeon machines with 32 cores per node on EDR InfiniBand compared to machines with 40 cores using the Xeon SP-6148 Gold processor and Omni-Path 100, running the Fluent oil_rig_7m model:
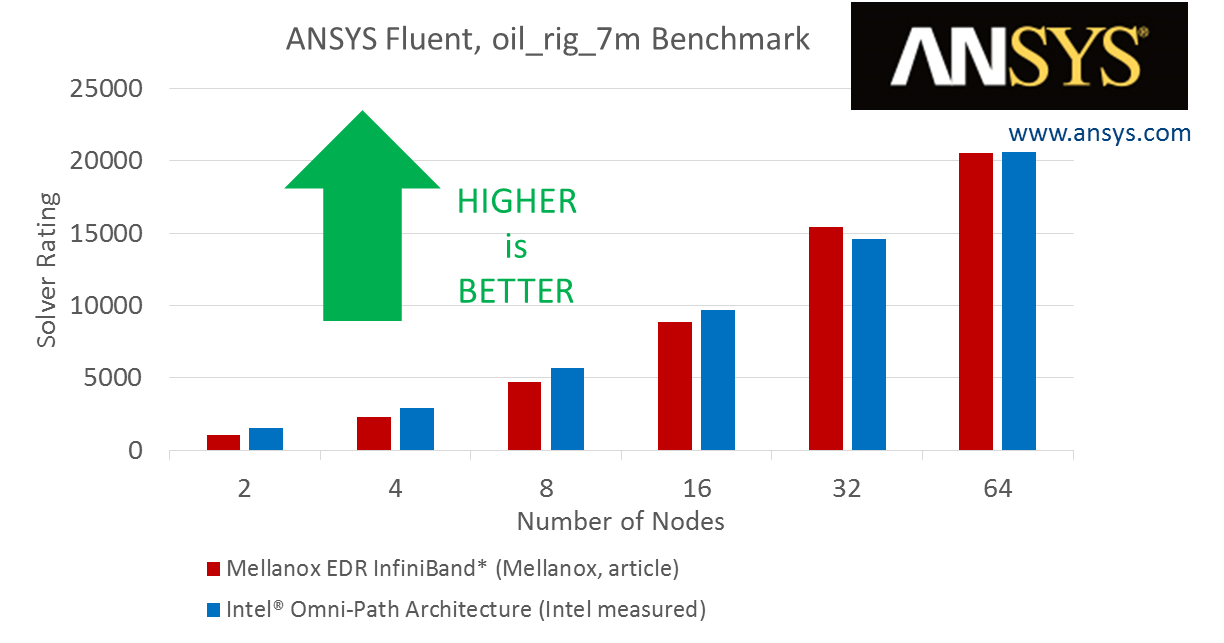
This is not an apples-to-apples comparison, either, since the compute nodes are different, but Intel is making the point that even with more cores (and presumably more memory bandwidth to balance it), the performance between the two networks is pretty close – sometimes Mellanox is ahead, sometimes Intel is ahead.
To stress the scalability point even further, Intel added in a larger f1_racecar_140m model in Fluent:
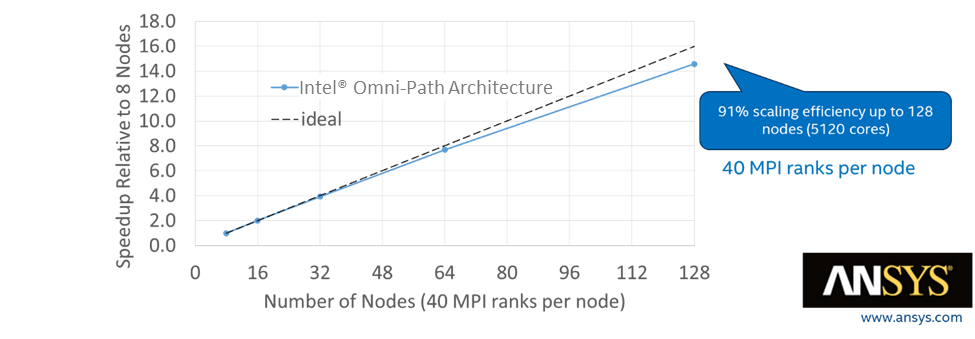
This test has 40 MPI ranks per node, and scales from eight nodes up to 128 nodes, and delivered 91 percent efficiency on the scale out across those 128 nodes and 5,120 cores. Intel goes on to cite a blog from ANSYS which in turn cites a whitepaper Intel created on behalf of ANSYS that shows Omni-Path 100 meeting or beating EDR InfiniBand on various scales of cluster running Fluent models ranging in size from 2 million to 14 million cells. (These are nowhere near as large as the F1 racecar model cited above.)
Moving on to the LS-DYNA three car collision simulation benchmark, here is how Intel showed off its performance:
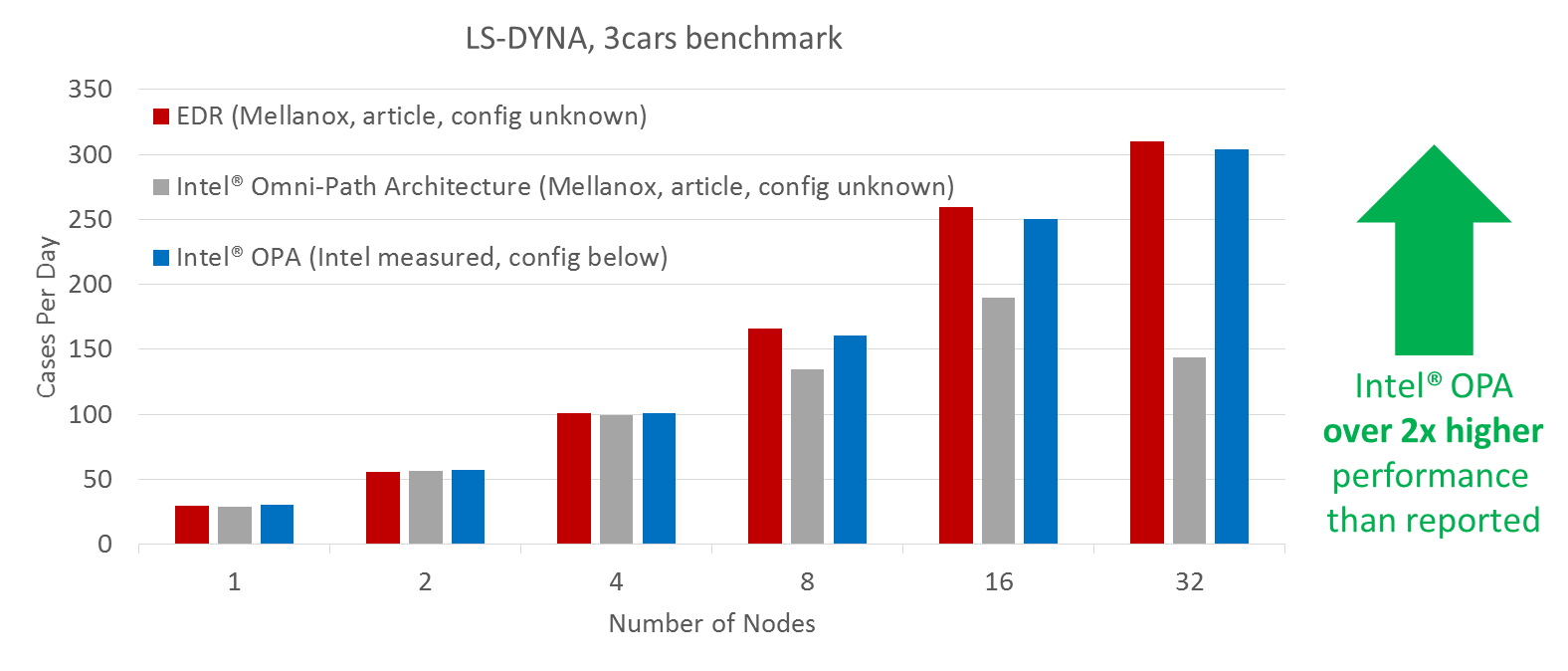
The dropoff that Mellanox saw in its tests was reversed with some tweaking of the buffer size in one parameter by Intel, believe it or not. And as you can see, EDR InfiniBand and Omni-Path 100 are basically neck and neck with InfiniBand a few points ahead.
Next and last comes the benchmark that Mellanox did on the Vienna Ab-inito Simulation Package, or VASP, quantum mechanical molecular dynamics application. The Mellanox tests showed the performance between the two networks on machine with 4 to 16 nodes in a cluster, using a workload called HEZB. Intel says it has no idea what this HEZB workload is, so it ran its VASP application tests using four different models of chemical compounds. Here is what this looks like, showing the performance of clusters relative to the performance of a base four-node cluster:
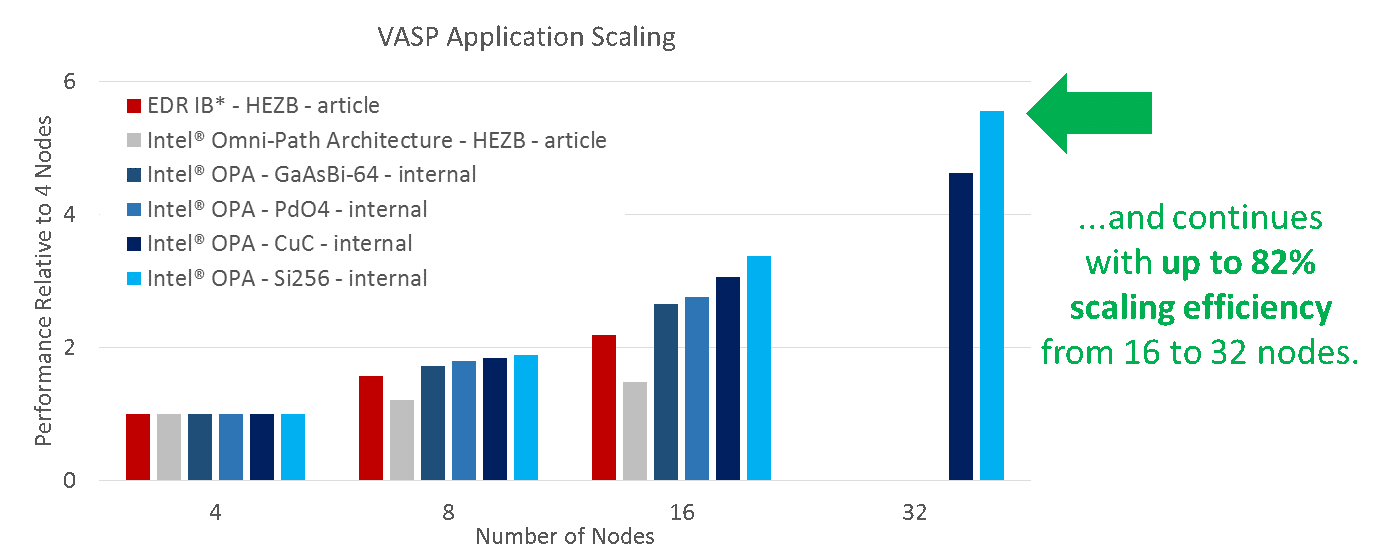
If you are not frustrated by now with the mixing of tests and configurations to try to isolate the performance of the network, you have more patience than we do.
This brings us back to a point we make all of the time. First, customers have to do their own benchmarks to test their own code using different network switches and adapters. There is no substitute for doing this. But the job is not even close to finished here. Just because users can do tests on clusters with two or four nodes does not mean that a particular application running on a larger cluster will scale well, much less something close to linearly. It could do it, but there is no guarantee that it will do it. That is where the networking industry has to step up and actually create a consortium for running networking benchmarks that are audited by independent third parties, much as has been done for compute for decades (the SPEC and TPC suites are the most famous) and storage for about a decade (the SPEC SFS tests).
We present the data as we find it, but we would rather be interpreting independent networking benchmarks alongside vendor supplied ones. More data is always better. Such independent networking tests would run representative HPC, AI, storage, and database clustering workloads on sensible compute nodes and stress the network as it is done in the real world, and would have to scale the network from 10 nodes to 100 nodes to 1,000 nodes to maybe even 5,000 nodes to actually show the effect of scale out on the cluster on overall performance. This is the kind of data that is usually missing in any benchmark comparison in the networking world. (And by the way, this data is even thinner outside of the HPC realm.) Configuring clusters with 4 to 16 nodes shows you something, but not the limits of scale of a network.
As you might imagine, we would want for such network benchmarks to include not only configuration details and performance metrics, but pricing. HPC is certainly about performance, but it is also limited by cost and driven by bang for the buck.
That brings us back around again to the unnamed Chinese weather research institute cited by Mellanox in its recent announcement. According to Gilad Shainer, vice president of marketing at Mellanox, this agency had a cluster of 100 nodes, which was running a modified version of the Weather Research and Forecasting (WRF) model out of the US National Center for Atmospheric Research. This cluster was built using Omni-Path 100 interconnects, but because of performance issues, the network was changed out by H3C, the cluster vendor, to EDR InfiniBand and the performance of the application went up by 1.9X. As you might imagine, we would love to talk to this HPC center to get the details, and for that matter, anyone else who switches from one network to another in the HPC realm.


The Ticking And Tocking Of Intel’s “Ice Lake” Xeon SP
It has been a long time since Intel changed its manufacturing process – what it used to call a “tick” – and the microarchitecture and architecture of a processor design – what it used to call a “tock” – at the same time. But with the fourth generation “Ice Lake” …
With VMware, Broadcom Has A Real Enterprise Software Stack
Once Dell spun out VMware on Wall Street, it was only a matter of time before someone would put together enough money to acquire it. A year ago, we mused about Intel being the logical buyer of VMware once Pat Gelsinger left the top job at VMware to return to …

Intel Targets DAOS Object Storage At More Than HPC
Intel is looking to position itself as a leader in AI and HPC through a holistic approach that plays to the company’s strengths across a broad swath of the IT ecosystem. This covers not just silicon hardware such as CPUs and ASICs, but also the firm’s expertise in open software …
If you want a conscientious objector, go speak to Dell EMC or HPE and ask to access their internal Supercomputers – I did this via my local Dell rep, and ran 50 nodes vs 50 nodes in identical configuration, before I bought my new cluster. Their system was rattler and zenith (can’t remember which is which), but across 5 codes it was 1% difference between the fabrics, and it was 50/50. We bought OPA as it allowed for an additional 5 nodes being supplied in the budget.
I’m sure other vendors offer the same access, and we did this through a local channel supplier to Dell.
I remember the Mellanox rep saying performance would be 2x greater, and the Intel rep never coming to see us, so we had to take it into our own hands and run our own benchmark.