

It would be ideal if we lived in a universe where it was possible to increase the capacity of compute, storage, and networking at the same pace so as to keep all three elements expanding in balance. The irony is that over the past two decades, when the industry needed for networking to advance the most, Ethernet got a little stuck in the mud.
But Ethernet has pulls out of its boots and left them in the swamp and is back to being barefoot again on much more solid ground where it can run faster. The move from 10 Gb/sec to 40 Gb/sec was slow and costly, and if it were not for the hyperscalers and their intense bandwidth hunger we might not even be at 100 Gb/sec Layer 2 and Layer 3 switching, much less standing at the transition to 200 Gb/sec and looking ahead to the not-to-distant future when 400 Gb/sec will be available.
Bandwidth has come along just at the right moment, when advances in CPU throughput are stalling as raw core performance did a decade ago and as new adjunct processing capabilities, embodied in GPUs, FPGAs, and various kinds of specialized processors are coming to market to get compute back on the Moore’s Law track. Storage, thanks to flash and persistent flash-like and DRAM-like memories such as 3D XPoint from Intel and Micron Technology, is also undergoing an evolution. It is a fun time to be a system architect, but perhaps only because we know that with these advanced networking options that bandwidth is not going to be a bottleneck.
The innovation that is allowing Ethernet to not leap ahead so much as jump to where it should have already been is PAM-4 signaling. The typical non-return to zero, or NRZ, modulation used with Ethernet switching hardware, cabling, and server adapters can encode one bit on a signal. With pulse amplitude modulation, or PAM, multiple levels of signaling can be encoded, so multiple bits can be encoded in the signal. With PAM-4, there are four levels of signaling which allow for two bits of data to be encoded at the same time on the signal, which doubles the effective bandwidth of a signal without increasing the clock rate. And looking ahead down the road, there is a possibility of stuffing even more bits in the wire using higher levels of PAM, and the whiteboards of the networking world are sketching out how to do three bits per signal with PAM-8 encoding and four bits per signal with PAM-16 encoding.
With 40 Gb/sec Ethernet, we originally had 10 Gb/sec lanes aggregated. This was not a very energy efficient way to do 40 Gb/sec, and it was even worse for early 100 Gb/sec Ethernet aggregation gear, which ganged up ten 10 Gb/sec lanes. When the hyperscalers nudged the industry along in July 2014 to backcast this 25 GHz (well, really 28 GHz before encoding) to 25 Gb/sec and 50 Gb/sec Ethernet switching with backwards compatibility to run 10 Gb/sec and 40 Gb/sec, the industry did it. So we got to affordable 100 Gb/sec switching with four lanes running at 25 Gb/sec, and there were even cheaper 25 Gb/sec and 50 Gb/sec options for situations where bandwidth needs were not as high, and at a much better cost. (Generally, you got 2.5X the bandwidth for 1.5X to 1.8X the cost, depending on the switch configuration.)
With the 200 Gb/sec Spectrum-2 Ethernet switching that Mellanox Technologies is rolling out, and that other switch makers are going to adopt, the signaling is still running at 25 GHz effective, but with the Spectrum-2 gear Mellanox has just unveiled, it is layering on PAM-4 modulation to double pump the wires, so it delivers 50 Gb/sec per lane even though it is still running at the same speed as 100 Gb/sec Ethernet lanes. And to reach 400 Gb/sec with Spectrum-2 gear, Mellanox is planning to widen out to eight lanes running at this 25 GHz (effective) while layering on PAM-4 modulation to get 100 Gb/sec effective per lane. At some point, the lane speed will have to increase to 50 GHz, but with PAM-8 modulation the switching at eight lanes could be doubled again to 800 GB/sec, and with PAM-16 you could hit 1.6 TB/sec. Adding in the 50 GHz real signaling here would get us to 3.2 TB/sec – something that still probably seems like a dream and that is probably also very far into the future.
This all sounds a lot easier in theory than it will be to actually engineer, Kevin Deierling, vice president of marketing at Mellanox, tells The Next Platform. “You can go to PAM-8 and you can go to Pam-16, but when you do that, you are starting to shrink the signal and it gets harder and harder to discriminate from one level in the signal and the next. Your signal-to-noise ratio goes away because you are shrinking your signal. Some folks are saying let’s go to PAM-8 modulation, and other folks are saying that they need to use faster signaling rates like 50 GHz. I think we will see a combination of both.”
The sweet thing about using PAM-4 to get to 200 Gb/sec switching is that the same SFP28 and QSFP28 adapters and cables that were used for 100 Gb/sec switching (and that are used for the 200 Gb/sec Quantum HDR InfiniBand that was launched by Mellanox last year and that will start shipping later this year) are used for the doubled up Ethernet speed bump. You need better copper cables for Spectrum-2 because the signal-to-noise ratio is shrinking, and similarly the optical transceivers need to be tweaked for the same reason. But the form factors for the adapters and switch ports remain the same.
With the 400 Gb/sec Spectrum-2 switching, the adapters have new wider form factors, with Mellanox supporting the QSFP-DD (short for double density) option instead of the OSFP (short for Octal Small Form Factor) option for optical ports. Deierling says Mellanox will let the market decide and support whatever it wants – one, the other, or both – but it is starting with QSFP-DD.
The Spectrum-2 ASIC can deliver 6.4 Tb/sec of aggregate switching bandwidth, and it can be carved up in a bunch of ways, including 16 ports at 400 Gb/sec, 32 ports at 200 Gb/sec, 64 ports at 100 Gb/sec (using splitter cables), and 128 ports running at 25 Gb/sec or 50 Gb/sec (again, using splitter cables). The Spectrum-2 chip can handle up to 9.52 billion packets per second, and has enough on chip SRAM to handle access control lists (ACLs) that span up to 512,000; with one of the 200 Gb/sec ports and a special FPGA accelerator that is designed to act as an interface to a chunk of external DRAM next to the chip, the Spectrum-2 can handle up to 2 million additional routes on the ACL – what Deierling says is the first internet-scale Ethernet switch based on a commodity ASIC that is suitable for hyperscaler-class customers who want to do Layer 3 routing on a box at the datacenter scale.
As for latency, which is something that everyone is always concerned with, the port-to-port hop on the Spectrum-2 switch is around 300 nanoseconds, and this is about as low as the Ethernet protocol, which imposes a lot of overhead, can go, according to Deierling. The SwitchX-2 and Quantum InfiniBand ASICs from Mellanox can push latencies down to 100 nanoseconds or a tiny bit lower, but that is where InfiniBand hits a wall.
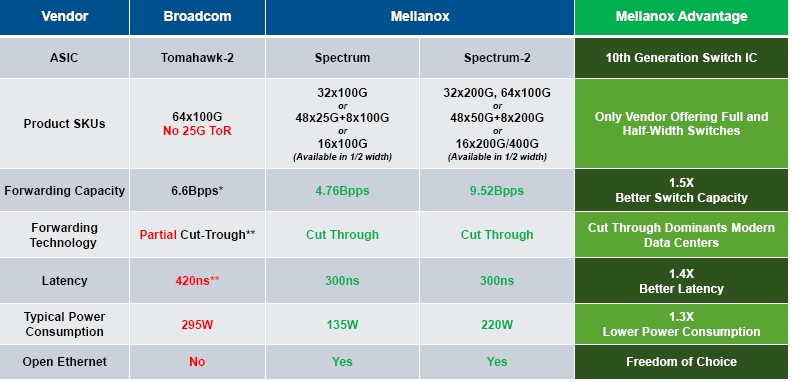
At any rate, Mellanox reckons that Spectrum-2 has the advantage in switching capacity, with somewhere between 1.6X and 1.8X the aggregate switching bandwidth compared to its competition – and without packet loss – and somewhere on the order of 1.5X to 1.7X lower latency, too.
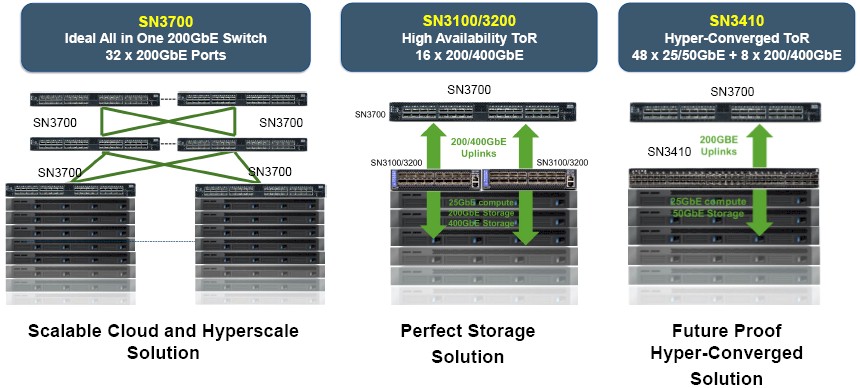
At the moment, Mellanox is peddling four different configurations of its Spectrum-2 switches, which are shown below:

The Spectrum-2 switches are being made available in two different form factors, two full width devices and two half width devices. The SN3700 has a straight 32 ports running at 200 Gb/sec for flat, Clos style networks, while the SN3410 has 48 ports running at 50 Gb/sec with eight uplinks running at 200 Gb/sec for more standard three tiered networks used in the enterprise and sometimes on the edges of the datacenter at hyperscalers. The SN3100 is a half-width switch that has 16 ports running at 200 Gb/sec, and the SN3200 has 16 ports running at 400 Gb/sec.
It is interesting that there is not a full width SN series switch with 400 Gb/sec ports. This is intentionally so and based on the expected deployment scenarios. In scenarios where a very high bandwidth switch is needed to create a storage cluster or a hyperconverged storage platform, 16 ports in a rack is enough and two switches at 16 ports provides redundant paths between compute and storage or hyperconverged compute-storage nodes to prevent outages.
There is even a scenarios that, using the VMS Wizard software for the Spectrum-2 switch that converts a quad of the 2100 Gb/sec and 400 Gb/sec switches that creates a virtual modular switch that with 64 of the SN3410 devices that can support up to 3,072 ports in a single management domain. Take a look:
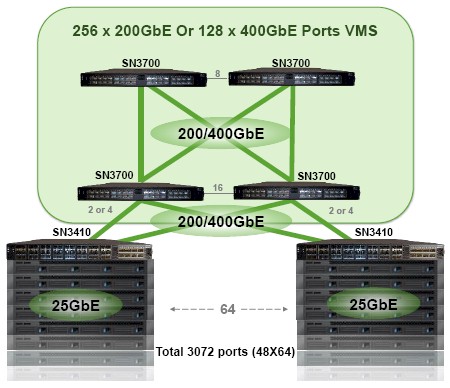
This Virtual Modular Switch is about 25 percent less expensive than actual modular switches with the same port count and lower bandwidth and higher latency.
Programmability is a big issue with networking these days, and the Spectrum-2 devices will be fully programmable and support both a homegrown compiler and scripting stack created by Mellanox as well as the P4 compiler that was created by Barefoot Networks for its “Tofino” Ethernet switch ASICs and that is being standardized upon by some hyperscalers. Mellanox expects for hyperscalers to want to do a lot of their own programming, but that most enterprise customers will simply run the protocols and routines that Mellanox itself codes for the machines. The point is, when a new protocol or extension comes along, Spectrum-2 will be able to adopt it and customers will not have to wait until new silicon comes out. The industry waited far too long for VXLAN to be supported in chips, and that will not happen again.
As for pricing, the more bandwidth you get, the more you pay, but the cost per bit keeps coming down and will for the 200 Gb/sec and 400 Gb/sec speeds embodied in the Spectrum-2 lineup. Pricing depends on volumes and on the cabling, of course, but here is how it generally looks. With the jump from 40 Gb/sec to 100 Gb/sec switching (based on the 25G standard), customers got a 2.5X bandwidth boost for somewhere between 1.5X and 1.8X the price – somewhere around a 20 percent to 30 percent price/performance benefit. Today, almost two years later, 100 Gb/sec ports are at price parity with 40 Gb/sec ports back then, and Deierling says that a 100 Gb/sec port costs around $300 for a very high volume hyperscaler and something like $600 per port for a typical enterprise customer. The jump to 200 Gb/sec will follow a similar pattern. Customers moving from 100 Gb/sec to 200 Gb/sec switches (moving from Spectrum to Spectrum-2 devices in the Mellanox lineup) will get 2X the bandwidth for 1.5X the cost. Similarly, those jumping from 100 Gb/sec to 400 Gb/sec will get 4X the bandwidth per port for 3X the cost.
Over time, we expect that there will be price parity between 100 Gb/sec pricing today and 200 Gb/sec pricing, perhaps two years hence, and that the premium for 400 Gb/sec will be more like 50 percent than 100 percent. But those are just guesses. A lot depends on what happens in the enterprise. What we do know is that enterprises are increasingly being forced by their applications and the latency demands of their end user applications to deploy the kind of fat tree networks that are common at HPC centers and hyperscalers and they are moving away from the over-subscribed, tiered networks of the past where they could skimp on the switch devices and hope the latencies were not too bad.

What If Omni-Path Morphs Into The Best Ultra Ethernet?
UPDATED: Nvidia is a member of the Ultra Ethernet Consortium. The jury is still out on a lot of things about this exploding AI market and the re-convergence that it will have with traditional HPC systems for running simulations and models. But one of the ideas that a lot of …
Nvidia Unfolds GPU, Interconnect Roadmaps Out To 2027
There are many things that are unique about Nvidia at this point in the history of computing, networking, and graphics. But one of them is that it has so much money on hand right now, and such a lead in the generative AI market thanks to its architecture, engineering, and …
Nvidia Passes Cisco And Rivals Arista In Datacenter Ethernet Sales
There is not one Ethernet business, but several, and now, with the evolution of Ethernet switches for back-end AI cluster networks, there is a new one that has the possibility to dominate revenues and profits. These Ethernet segments – campus, edge, datacenter front end, and datacenter back-end are the four …
Be the first to comment