
When it comes to HPC, compute is like the singers in a rock band, making all of the noise and soaking up most of the attention. But the network that lashes the compute together is literally the beat of the drums and the thump of the bass that keeps everything in synch and allows for the harmonies of the singers to come together at all.
In this analogy, it is not clear what HPC storage is. It might be the van that moves the instruments from town to town, plus the roadies who live in the van that set up the stage and lug that gear around.
In any event, we always try to get as much insight into the networking as we get into the compute, given how important both are to the performance of any kind of distributed system, whether it is a classical HPC cluster running simulation and modeling applications or a distributed hyperscale database. There is a healthy rivalry between Intel’s Omni-Path and Mellanox Technologies’ InfiniBand, and as part of the discussion at the recent SC17 supercomputing conference, we got our hands on some benchmark tests that pit the 100 Gb/sec implementations of both protocols against each other on popular HPC applications and also got some insight into how Mellanox will be positioning 200 Gb/sec HDR Quantum InfiniBand, which was previewed conceptually last year at SC16 and which will be shipping around the middle of next year in both leaf/spine and modular form factors, against Intel’s 100 Gb/sec Omni-Path 100 series interconnects.
Despite being a relative niche player against the vast installed base of Ethernet gear out there in the datacenters of the world, InfiniBand continues to hold onto the workloads where the highest bandwidth and the lowest latency are required. (We are using the term InfiniBand there to encompass both the EDR Switch-IB and Switch-IB 2 switches and now HDR Quantum switches from Mellanox as well as the current Omni-Path 100 and future Omni-Path 200 switches from Intel that compete with them. We are well aware that the underlying technologies are different, but Intel Omni-Path runs the same Open Fabrics Enterprise Distribution drivers as the Mellanox InfiniBand, so this is a hair that Intel is splitting that needs some conditioner. Like the lead singer in a rock band from the 1980s, we suppose. Omni-Path is, for most intents and purposes, a flavor of InfiniBand, and they occupy the same space in the market.
Intel’s Omni-Path, which is derived from its $125 million QLogic InfiniBand acquisition in 2012, is distinct from the Mellanox implementation of InfiniBand in one important respect. Mellanox has an offload model, which tries to offload as much of the network processing from the CPUs in the cluster to the host adapters and the switch as is possible. With the combination of Quantum HDR InfiniBand switches and ConnectX-6 adapters, about 70 percent of the load of the MPI protocol and other related protocols for HPC is shifted to the network, freeing up CPU cycles to do HPC work. Both the 20 Gb/sec and 40 Gb/sec QLogic True Scale and 100 Gb/sec Intel Omni-Path 100 interconnects employ an onload model, where a lot of this MPI and related processing is done across the distributed compute in the cluster. Intel will argue that this allows for its variant of InfiniBand to scale further because the entire state of the network can be held in the memory and processed by each node rather than a portion of it being spread across adapters and switches. We have never seen a set of benchmarks that settled this issue. And it is not going to happen today.
What we can do is take a look at the latest benchmark information, in this case compiled by Mellanox, to see how the 100 Gb/sec generations of InfiniBand and Omni-Path are faring, and then look ahead at what may happen with 200 Gb/sec follow-ons competitively speaking.
As part of its SC17 announcements, Mellanox put together its own comparisons. In the first test, the application is the Fluent computational fluid dynamics package from ANSYS, and it is using a wave loading stress on an oil rig floating in the ocean. The test, which has various published benchmarks here, has 7 million hexahedral cells in the simulation and, to quote, “uses the VOF, SST K-omega Turbulence model and the Pressure based segregated solver, Green-Gauss cell based, unsteady solver.” Mellanox hauled out some benchmarks ran by Intel which pit EDR InfiniBand against Omni-Path 100 using machines with two 18-core “Broadwell” Xeon processors per node and a varying number of nodes:
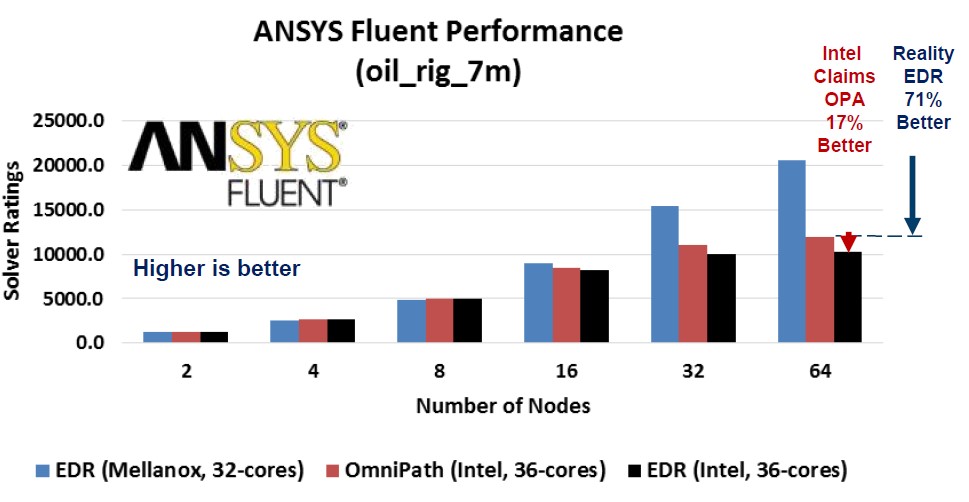
In this test, the red column is the results Intel got for Omni-Path and the black column is what Intel got for EDR InfiniBand. Mellanox was not happy with these numbers, and ran its own EDR InfiniBand tests on machines with fewer cores (16 cores per processor) with the same scaling of nodes (from 2 nodes to 64 nodes) and these are shown in the light blue columns. Obviously, Mellanox is pretty keen to point out that on this simulation, its InfiniBand beats Intel’s InfiniBand in large scale clusters. The difference seems to be negligible on relatively small clusters, however. You might be thinking that Mellanox and Intel stopped scaling up ANSYS Fluent because the application does not scale, but you will recall that earlier this year, the Shaheen II system built by Cray with 6,174 “Haswell” Xeon nodes demonstrated Fluent running across 197,568 cores, a factor of 86X more scalability than the upper limits of the tests shown above.
Here is how 100 Gb/sec Omni-Path and Switch-IB 2 InfiniBands stack up against each other running the LS-DYNA finite element analysis software developed by Livermore Software Technology Corp. This particular test is a 3 vehicle collision simulation, specifically showing what happens when a van crashes into the rear of a compact car, and that in turn crashes into a mid-sized car. (This is what happens when the roadie is tired.) Take a look:
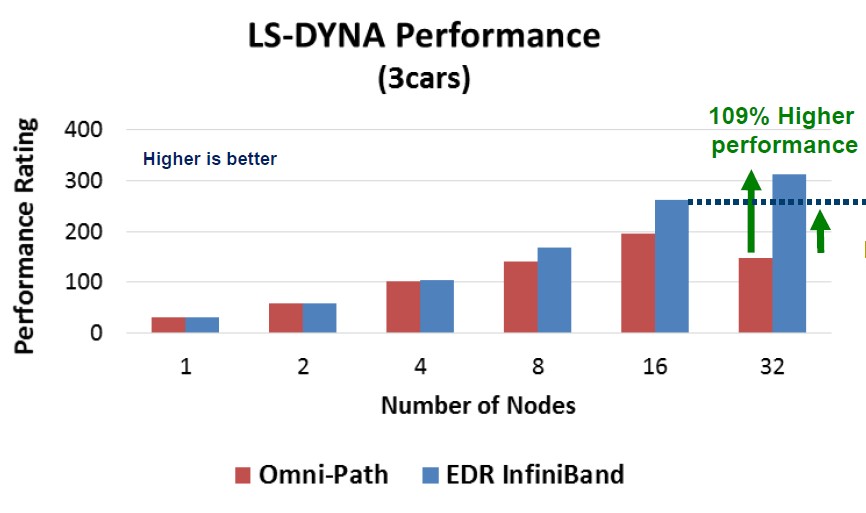
This set of benchmarks was done by Mellanox, again with Omni-Path in red and Switch-IB 2 in light blue. It is not clear what happens to the Omni-Path cluster as it scales from 16 to 32 nodes, but there was a big drop in performance. It would be good to see what Intel would do here on the same tests, with a lot of tuning and tweaks to goose the performance on LS-DYNA. The EDR InfiniBand seems to have an advantage again only as the application scales out across a larger number of nodes. This runs counter to the whole sales pitch of Omni-Path, and we encourage Intel to respond.
With the Vienna Ab-inito Simulation Package, or VASP, quantum mechanical molecular dynamics application, Mellanox shows its InfiniBand holding the performance advantage against Omni-Path across clusters ranging in size from 4 to 16 machines:
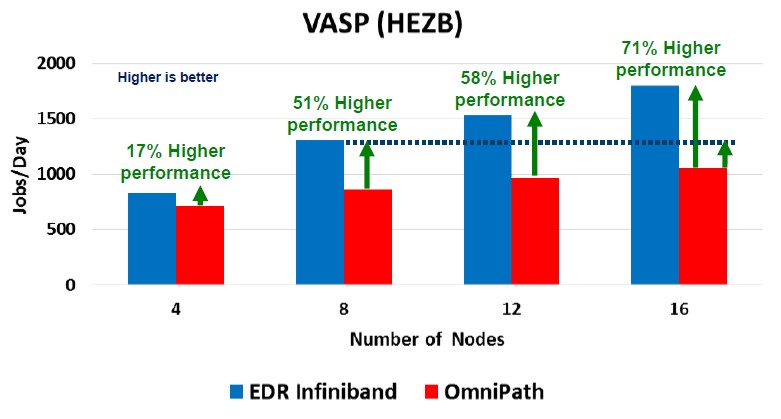
In this particular test, the compute nodes were based on the latest “Skylake” Xeon SP processors from Intel. The application is written in Fortran and uses MPI to scale across nodes.
That leaves the GRID lattice quantum chromodynamics simulator, which is written in C++ with a hybrid MPI-OpenMP scale (OpenMP on the nodes and MPI across the nodes) with some NUMA-aware optimizations. The particular test run is called the DiRAC-ITT test, which runs the application in single precision. The HPC-X 2.0 has two new accelerated transports that use enhanced verbs, and just for fun the tests were run in double precision, which swamps the network for the same test size.
Here is a set of tests on the GRID benchmark that Intel ran (in the red and black columns again) that showed Omni-Path 100 and EDR InfiniBand essentially neck and neck; then Mellanox did a rerun of its EDR InfiniBand with the HPC-X transport tweaks, and got a pretty significant jump in performance. The processors in the two socket servers were Intel’s “Broadwell” Xeon E5-2697A chips. Take a gander:
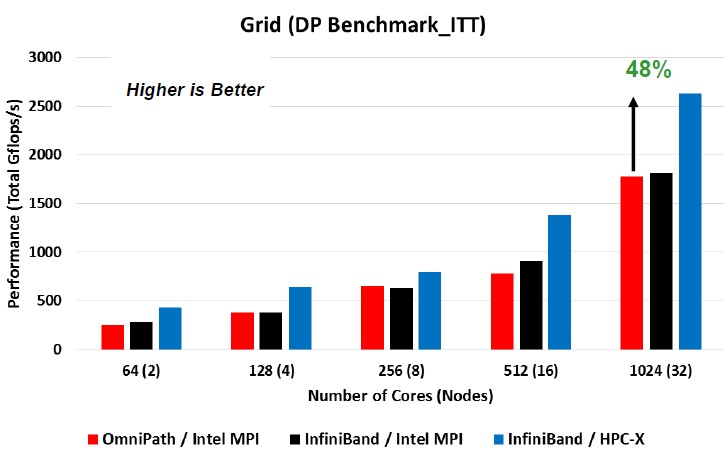
Here is another test that Mellanox did, pitting the InfiniBand/HPC-X combo against Omni-Path with Intel’s MPI implementation. In this test, Mellanox ran on clusters with from two to 16 nodes, and the processors were the Xeon SP-6138 Gold chips:
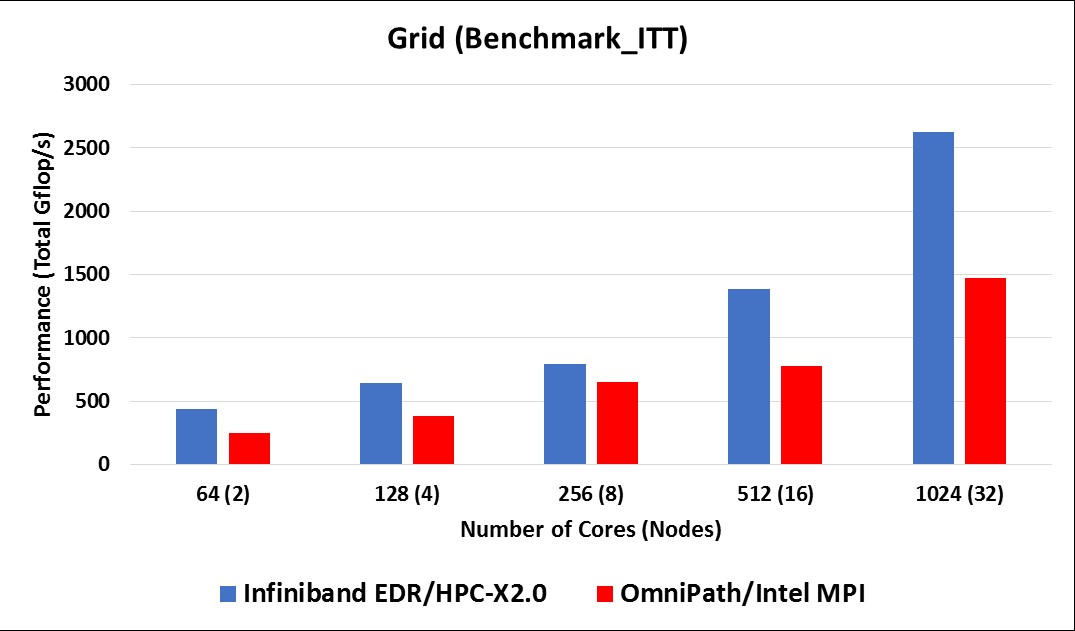
What is immediately clear from these two charts is that the AVX-512 math units on the Skylake processors have much higher throughput in terms of delivered double precision gigaflops, even if you compare the HPC-X tuned-up version of EDR InfiniBand, it is about 90 percent more performance per core on the 16-node comparison, and for Omni-Path, it is more like a factor of 2.6X. Which is peculiar, but probably has some explanation. Mellanox wanted to push the scale up a little further, and on the Broadwell cluster with 128 nodes (which works out to 4,096 cores in total) it was able to push the performance of EDR InfiniBand up to around 9,250 aggregate gigaflops running the GRID test. (You can see the full tests at this link).
To sum it all up, this is a summary chart that shows how Omni-Path stacks up against a normalized InfiniBand:

Intel will no doubt counter with some tests of its own, and we welcome any additional insight.
The point of this is not just to get a faster network, but to either spend less money on servers because the application runs more efficiently or to get more servers and scale out the application even more with the same money. The savings, says Gilad Shainer, vice president of marketing for the HPC products at Mellanox, can be quite high.
Take the 32-node LS-DYNA configuration running EDR InfiniBand. That cluster costs $278,238 with the InfiniBand network in it. But to get the same performance on LS-DYNA, you would have to build a system that cost $491,280 – and that would not even include the cost of the Omni-Path network, by Shainer’s math. That is a worst case example, and the gap at four nodes is negligible, small at eight nodes, and modest at 16 nodes, if you look up to the data. The gap is similar on the Fluent test, where a 64 node cluster running EDR InfiniBand would cost $540,000, and to get the same performance would take a cluster that costs $982,560 – again, without the Omni-Path networking included. These are big gaps, obviously, and are much bigger than the gaps that Intel’s own tests showed.
Which brings us to our point. These benchmarks are a way to analyze how you might structure your own benchmarks for your own applications, to be ever-ware of how the nodes scale up and the clusters scale out. This interconnect stuff is tricky.
Looking Ahead To 200 Gigabits
The Omni-Path roadmap was timed for speed bumps to roughly coincide with the Knights family of many core processors. The InfiniBand roadmap is on a roughly two year cadence, with product previews at every other SC supercomputing conference and shipments somewhere between 12 months and 18 months after that. The 200 Gb/sec Quantum HDR InfiniBand is a little bit unusual in that it is tied to the IBM Power9 and Intel Xeon SP processors, and maybe even the AMD Epyc, Cavium ThunderX2, and Qualcomm Centriq 2400 processors, too.
With the move from EDR Switch-IB 2 to HDR Quantum ASICs, Mellanox moved from 36 ports running at 100 Gb/sec to 40 ports running at 200 Gb/sec, and as we have detailed, those Quantum ports can be configured at the chip or sliced down by splitter cables to deliver 80 ports running at 100 Gb/sec, which will be plenty of bandwidth for many applications. That factor of 2.2X increase in port density allows InfiniBand networks of a given node count and tier complexity to be built with far fewer switches, and it allows customers to switch to 200 Gb/sec when they are ready and only have to buy another block of switches in the future.
With the Omni-Path 100 switches, Intel offered configurations with 24 ports or 48 ports per switch, which gave it an advantage on density over the EDR InfiniBand boxes from Mellanox, something which Intel talked up quite a bit. Intel never talked about what processes were used to make the Omni-Path chips, but networking ASICs tend to be on the bleeding edge so we assume that 14 nanometer processes were used for the Omni-Path 100 series, just like the “Knights Landing” Xeon Phi processor it was sold alongside of; moreover, we think that 200 Gb/sec Omni-Path 200 was to be etched in 10 nanometer processes, just like the now defunct “Knights Hill” parallel processor that was due to be installed in the “Aurora” 180 petaflops pre-exascale system at Argonne National Laboratory. That machine was canceled and now there is an A21 replacement due in 2021 from Intel that will be based on a different and as yet undisclosed architecture. We think that, among many things, the 10 nanometer processes that Knights Hill and presumably Omni-Path 200 were etched in are causing Intel all kinds of headaches, and it is not clear now when Intel will get a kicker to Omni-Path 100 out the door. With such a process shrink, Intel might have been able to get more ports running at a higher speed – perhaps 56 ports at 200 Gb/sec or 112 ports at 100 Gb/sec – to give it a density lead. It seems unlikely it could have stayed at 48 ports at 200 Gb/sec and have no density increase, but maybe not and this is another problem.
Whatever is happening, it is leaving Mellanox doing all of the talking right now.
Intel is being vague about both the future of the Knights processors and the Omni-Path interconnect, and did not take the opportunity to clear this up at SC17. The reason for this, we believe, is that Intel is still not sure of the plan going forward because it needs to work with its own technical people and bean counters as well as those at the national labs that have invested in Knights and Omni-Path to plot a course to the future. How open Intel will be with the rest of the HPC community about its plans, given that it wants to have wiggle room to change as conditions and technologies do, remains to be seen.

Intel Gets Its Chiplets In Order With 6th Gen Xeon SPs
Based on what Intel has been saying for the past several weeks in various events, but especially the Hot Chips 2023 a few weeks ago and the more recent Intel Innovation 2023 extravaganza, the company’s foundry process roadmap and its server processor roadmaps are going to align harmoniously to make …
Chip Makers Press For Standardized FP8 Format For AI
In March, Nvidia introduced its GH100, the first GPU based on the new “Hopper” architecture, which is aimed at both HPC and AI workloads, and importantly for the latter, supports an eight-bit FP8 floating point processing format. Two months later, rival Intel popped out Gaudi2, the second generation of its …
Intel To Broaden FPGA Lineup And Make Them At Home
Back in 2015, when Intel was flush with cash thanks to a near-monopoly from X86 datacenter compute, it shelled out an incredible $16.7 billion to acquire FPGA maker Altera because a few hyperscalers and cloud builders were monkeying around with offloading whole chunks of CPU compute to FPGAs to create …
Be the first to comment