
If it were not for the insatiable bandwidth needs of the twenty major hyperscalers and cloud builders, it is safe to say that the innovation necessary to get Ethernet switching and routing up to 200 Gb/sec or 400 Gb/sec might not have been done at the fast pace that the industry as been able to pull off.
Knowing that there are 100 million ports of switching up for grabs among these companies from 2017 through 2021 – worth tens of billions of dollars per year in revenues – is a strong motivator to get clever.
And that is precisely what the networking industry has been doing. Barefoot Networks has been pushing the envelope of network programmability with its P4 language and its “Tofino” switch ASICs, which deliver 6.5 Tb/sec of aggregate bandwidth and deliver 200 Gb/sec ports, and Innovium is planning to get its “Teralynx” switch ASICs out the door this year with a top-end 12.8 Tb/sec chip that can drive 400 Gb/sec ports. Mellanox Technologies is already delivering 200 Gb/sec ports using its “Spectrum-2” ASICs, which peak at 6.4 Tb/sec per chip, and has a plan to push that up to 400 Gb/sec ports and 12.8 Tb/sec per chip in the not-too-distant future. Everyone is chasing Broadcom, which is the volume leader in Ethernet datacenter switch chips, or trying to leapfrog it to higher bandwidth or higher port counts – or both – to try to carve out a bigger slice of those tens of billions in networking dollars.
That task just got a little bit harder now that Broadcom has unveiled its third generation of “Tomahawk” ASICs, the grandchild of the original Tomahawk-1 launched in 2014, which delivered 32 ports running at 100 Gb/sec, and the Tomahawk-2 launched in 2016, which cranked up the radix and therefore the server density and also flattened networks thanks to being able to deliver 64 ports at 100 Gb/sec speeds. Broadcom is picking up the pace, and like its peers is getting network bandwidth increases back on a curve that is rising faster than Moore’s Law, and hopefully gets networking between nodes and across racks and datacenters to be less of a bottleneck in distributed systems.
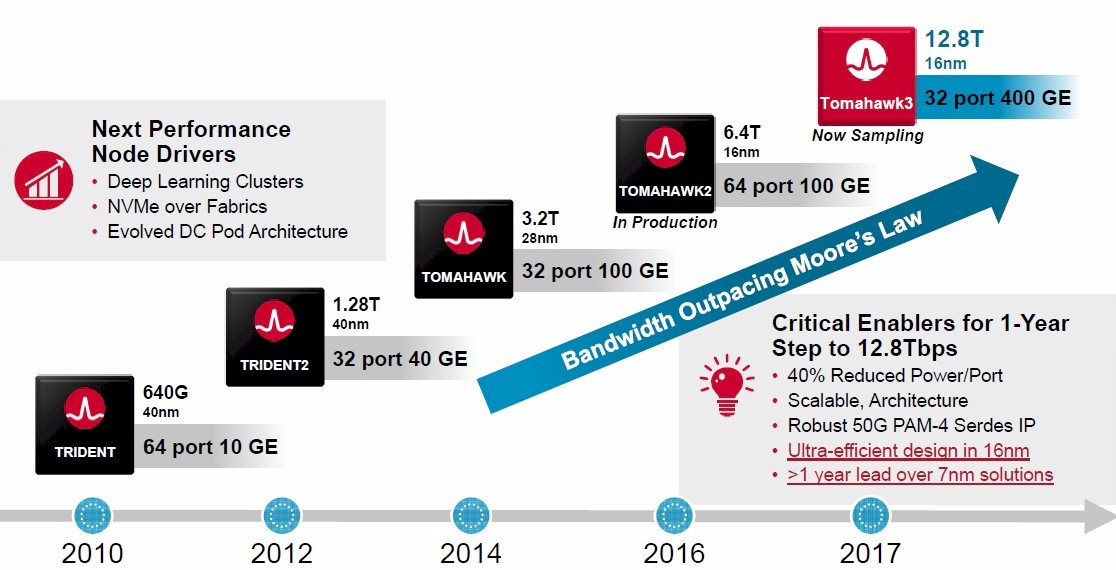
The Tomahawk family of chips is distinct from the “Trident” family, which is aimed more at enterprise customers that need a broad set of network protocols than hyperscalers and cloud builders that need bandwidth and only some protocols. (The Trident and Trident-2 chips were, nonetheless, favorites of the hyperscalers and cloud builders in the early days of their explosive growth, and made Broadcom plenty of money.) The Trident line was last updated in August 2017, with the Trident-3 ASIC, which spans from a low-end X2 version that delivers 200 Gb/sec of aggregate bandwidth for WiFi access points to a high-end X7 version that delivers 3.2 Tb/sec and either 32 ports running at 100 Gb/sec or a combination of 48 ports running at 50 Gb/sec plus eight uplinks running at 100 Gb/sec. The “Jericho” line of switch ASICs came from Broadcom’s acquisition of Dune Networks for $178 million back in 2009. The Jericho chips were used to create modular switches (rather than fixed port devices) with switch blades that can allow an enclosure to run multiple speeds and port counts and to make high-scale fabrics that link line cards within the chassis. These Dune devices are slower and deeper, rather than being more fast and furious like the Tomahawks and Tridents. The Jericho chips were last updated in late 2016, and are also due for an upgrade it looks like.
The Tomahawk-3 chips are aimed right at the bandwidth and latency needs of the hyperscalers and cloud builders, Rochan Sankar, senior director of the core switch group at Broadcom, tells The Next Platform. This includes the massive amount of stateless servers these companies deploy, which have a huge amount of chatter between servers that can be spread across a datacenter with 100,000 machines (the so-called east-west traffic) as well as for deep learning networks and disaggregated flash storage, both of which also require a high radix switch (a fancy way of saying it has a lot of ports per ASIC) that in turn creates a flatter and cheaper network that has lower end-to-end latency between components of a distributed application.
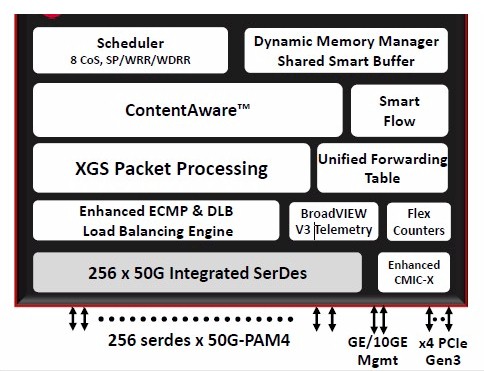
We will get into the economics in a moment. But for now, let’s talk about the feeds and speeds of the Tomahawk-3 chip. First of all, it is implemented in the same 16 nanometer processes from Taiwan Semiconductor Manufacturing Corp that is used on the prior Trident-3 and Tomhawk-2 chips, meaning that the process is mature and, in one sense, cheaper to deal with. Switch chip vendors never give out transistor counts or anything but the basic design elements, but it looks like the Tomahawk-3 will be considerably larger than the Tomahawk-2 that it replaces, with 256 serializer/deserializer (SerDes) circuits running at 50 Gb/sec to yield that aggregate of 12.8 Tb/sec of bandwidth across the chip. The key factor in this big jump in bandwidth, which as we have pointed out is getting networking back to where it should have been, is called PAM-4 signaling, which is short for four channel pulse amplitude modulation. The feeds and speeds chart for the Tomahawk-3 chip has some pretty pictures that show how it works:

With the non-return to zero modulation (NRZ) used with Ethernet switching hardware, cabling, and server adapters in the past, one bit can be encoded on a signal. In the case of the Tomahawk-2 chip, there are two levels of encoding running at 12.5 Gb/sec (after encoding, shown in the blue on the left of the chart), and together they yield 25 Gb/sec signaling per SerDes; you gang up four of these 25 Gb/sec lanes and you get 100 Gb/sec ports. On the right, shown in the orange and pink, is PAM signaling, which allows for multiple levels of signal encoding, thus increasing the baud rate of that signal. With PAM-4, there are four levels of signaling, and that allows for two bits of data to be encoded at the same time on the signal, which doubles the effective bandwidth of a signal without increasing the clock rate. You can, in theory, stuff even more bits in the wire using higher levels of PAM, with maybe three bits per signal with PAM-8 encoding and four bits per signal with PAM-16 encoding. That is a good way to try to get to higher bandwidths, and so is moving to 25 Gb/sec signaling per level and 50 Gb/sec per lane. In any event, the SerDes in the Tomahawk-3 have eight lanes running at an effective 50 Gb/sec to reach 400 Gb/sec per port. The Tomahawk-3 ASIC can carve down those lanes to yield ports running natively at 50 Gb/sec, 100 Gb/sec, 200 Gb/sec, or 400 Gb/sec, or use cable splitters to chop the 400 Gb/sec ports down to two running at 200 Gb/sec or four running at 100 Gb/sec. There is a lot of flexibility here.
With each process shrink and now with the change in modulation, Broadcom has been able to move down the amount of power to deliver a level of bandwidth, and even with keeping the process at 16 nanometers with the Tomahawk-3, the power consumption per port is going to drop by about 40 percent compared to the Tomahawk-2. This is one reason why switch makers relying on Broadcom parts will be able to cram lots of ports onto their devices, because the power density is going to go down. Based on the data we have seen (which shows relative power draw versus absolute wattage figures for 100 Gb/sec ports), the Tomahawk-3 draws a little more than half the power of the port on a Tomahawk-1, and it is about a quarter of the power draw of the Trident+ chip from 2010, which could do 640 Gb/sec aggregate or only a twentieth of the bandwidth, with ten 10 Gb/sec ports aggregated. This is a big improvement in watts per gigabits per second.
Because of the high radix nature of the Tomahawk-3, Sankar says that the cost to deliver a 100 Gb/sec Ethernet port will drop by 75 percent compared to the Tomahawk-2, and that is a huge drop and one that hyperscalers and cloud builders are pushing for. Because of the limitations in terms of bandwidth and port count on switch chips in the last decade, it takes a lot of chips to make a Clos network that can span datacenters with tens to hundreds of thousands of servers, and this has been driving up networking costs relative to other costs to the point where networking has pushed above 20 percent of the total capital outlay for iron in the datacenter and was kissing 25 percent in some instances. With higher port counts on each chip, it takes fewer chips to interlink all of the devices in a hyperscale datacenter. Facebook’s “Backpack” modular switch is a good example of being able to cut down the switch chips and therefore the costs:
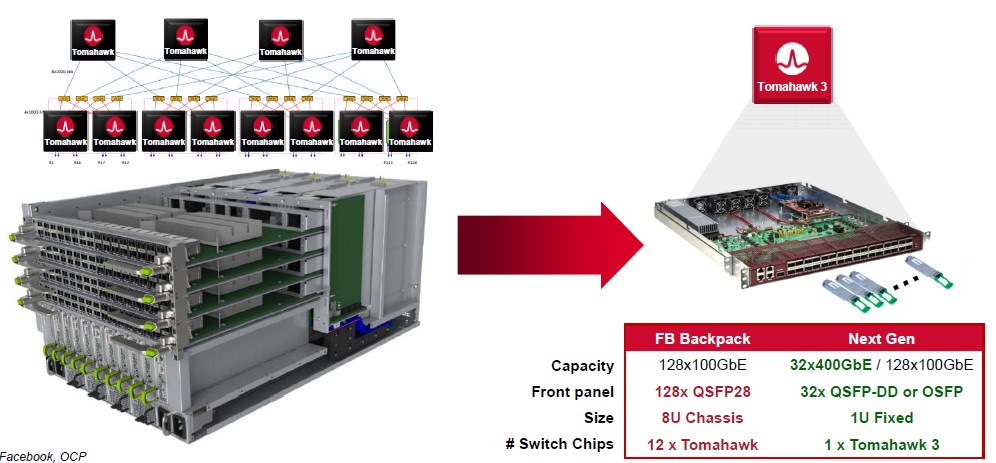
The Backpack switch was designed to deliver 128 ports running at 100 Gb/sec, and it had to go modular to do so because no one chip had that many ports. In fact, as you can see, this modular switch had eight Tomahawk-1 chips, two per card, acting as leaf switches and another four Tomahawk-1 chips acting as the interconnect for those switch blades. (This modular switch is, in effect, a self-contained spine-leaf network in a can.) Now, those dozen Tomahawk-1 chips running in an 8U modular server can be replaced with a single 1U fixed port switch using a single Tomahawk-3 chip, which cuts the cost by 85 percent and the power consumption by 75 percent.
The higher radix switch doesn’t just cut costs for delivering 100 Gb/sec ports while also enabling bigger 200 Gb/sec and 400 Gb/sec ports, but it eliminates layers of the n-tier network and therefore improves end-to-end latencies for applications. Sankar gave NVM-Express storage as an example. In a flash cluster array with four leaf switches with 64 ports running at 100 Gb/sec in the first tier and two spine switches based on the same hardware in the second tier, it takes three hops for any server to reach any NVM-Express array in the network and one to several microseconds to cross the network with the data. With a single Tomahawk-3 fixed point switch, the data is accessible in a single hop that takes around 400 nanoseconds.
As you might imagine, this means hyperscalers are going to be able to build flatter – and cheaper – networks. And when we hear how hyperscalers need petabit networking, it was never about having ports that run at 400 Gb/sec, 800 Gb/sec, or even 1.2 Tb/sec, but rather a lot more ports running at 100 Gb/sec. That is still 10X faster than the average server port in the enterprise, and considerably faster than the 10 Gb/sec or 40 Gb/sec ports in use at hyperscalers and cloud builders. (To be sure, 25 Gb/sec ports are more common, and 50 Gb/sec ports are getting there.)
By the way, Sankar says that 100 Gb/sec PAM-4 is the next step to get to 800 Gb/sec on each port, doubling up the signaling from 14 GHz (12.5 GHz effective after encoding) to 28 GHz (25 GHz effective after encoding), but Broadcom is making no promises on what it will do for Tomahawk-4. But that could be what happens with Tomahawk-4, and then a move to PAM-8 modulation (three bits encoded per signal) with Tomahawk-5 would put us at 1.2 Tb/sec per port and PAM-16 modulation (four bits encoded per signal) with the same 50 GHz effective speed would put us at 1.6 Tb/sec per port.
One big change with the Tomahawk-3 chip that is seeking to even out the performance of the network is a shared buffer architecture, which looks a lot like the shared L3 cache architectures on server processors for the past decade.
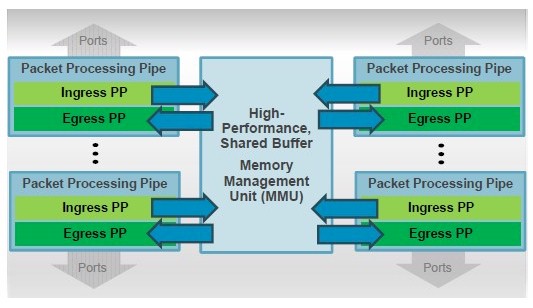
The packet processing pipeline sits behind the ports, implementing ingress and egress packet processing, and because the buffer is shared, it can hold a lot of data if a port that is the destination becomes clogged and wait out the traffic jam without dropping packets and forcing a resend. The buffer architecture has support for RoCEv2 remote direct memory access and congestion control, and also has what Broadcom calls flow-aware traffic scheduling, which is a key for hyperscalers and cloud builders and more than a few HPC and AI shops, too.
“Companies are not running monolithic workloads,” explains Sankar. “They run many different applications, running in parallel, as they go through the switches. In that case, you have elephants and mice, the former of which causes queueing delays that affect different flows in different ways. So in real time, we can see those bandwidth-consuming elephants and reprioritize them versus the mice to ensure that both classes of traffic are experiencing the least amount of queueing delay. This new architecture for buffering ultimately eliminates drops and has 3X to 5X greater incast absorption and lossless capacity versus alternatives, and in the process it drives down tail latency.”
For any multi-node job, whether it is data analytics cluster running Hadoop or an HPC cluster running a simulation or an AI training cluster running machine learning training algorithms, it is the outliers in latency or the drops that can really slow down the overall application. You have to sweat the tail latencies.
Broadcom is not yet releasing the size, speed, or precise architecture of the shared buffer on the Tomahawk-3 chip, and it may never do so. The company has divulged that it is bringing two variants of the Tomahawk-3 to market. The first has the full-tilt-boogie 12.8 Tb/sec with all 256 SerDes fired up, which is expected to be used in hyperscale spine switches as well as in one-tier machine learning clusters and middle-of-row aggregation switches. This one will support 32 ports at 400 Gb/sec, 64 ports at 200 Gb/sec, and 128 ports at 100 Gb/sec. The second variant of the Tomahawk-3 will have only 160 of the 256 SerDes fired up and delivers only 8 Tb/sec of aggregate bandwidth, which can be carved up into a bunch of different configurations of top of rack switches. Broadcom is suggesting 80 ports at 100 Gb/sec; or 48 ports at 100 Gb/sec plus either 8 ports at 400 Gb/sec or 16 ports at 200 Gb/sec; or 96 ports at 50 Gb/sec plus either 8 ports at 400 Gb/sec or 16 ports at 200 Gb/sec.

Cloud Foundation Updates Reflect The New VMware By Broadcom
Broadcom’s $69 billion acquisition of virtualization stalwart VMware was not an easy proposition. Regulators around the world worried about the effect the deal would have on the IT industry and Broadcom had to make some promises – such as to the European Union, which demanded concessions from the semiconductor giant …
How Long Until The ODMs Take Over Ethernet Switching?
For more than a year now, we have been talking about how investments in AI servers have put a damper on budgets for servers used to support other corporate applications. And we may be seeing enterprises pulling back on campus switching so they can invest more in datacenter switching to …
After The 2022 Bump, Arista Is Back To The Grind In 2023
For Arista Networks, the poster-child of hyperscaler and cloud build networking that, more than any other vendor, has championed merchant silicon and Linux as the basis of a modular network operating system, 2022 was a bumper crop year. This year, there are many new things going on, but the compares …
PAM-4 stands for 4-level pulse-amplitude modulation, not 4-channel.
And “bugger” and “buffer” are not the same thing at all. 🙂
No, I suppose they are not…
Thanks for this informative writing.
Where it says, “…use cable splitters to chop the 400 Gb/sec ports down to two running at 200 Gb/sec or four running at 400 Gb/sec”, should this read 100 Gb/sec?
Yes. Thank you.