
The hyperscalers of the world have to deal with dataset sizes – both streaming and at rest – and real-time processing requirements that put them into an entirely different class of computing.
They are constantly inventing and reinventing what they do in compute, storage, and networking not just because they enjoy the intellectual challenge, but because they have swelling customer bases that hammer on their systems so hard they can break them.
This is one of the reasons why an upstart called Streamlio has created a new event-driven platform that is based the work of software engineers at Twitter, Yahoo, and Google and that stitches together a number of Apache open source projects into a coherent whole that, Streamlio’s founders say, results in a modern platform that outperforms other options and positions the company for modern, data-heavy streaming applications running in both the datacenter and out on the edge.
As we have been talking about in recent weeks, the walls of the datacenter are coming down and computing is getting more distributed, which is why you see the OpenStack community putting together a baby cloud controller, for instance. The Streamlio platform is not just about replacing Kafka, the popular data streaming protocol that was created by LinkedIn and has often front-ended data analytics clusters running Hadoop batch or Spark in-memory processing. Kafka became an Apache project, was subsequently commercialized by Confluent, and that has gotten a native database layer, called KSQL, that turns it into a platform in its own right. Streamlio, says company CEO Lewis Kaneshiro, is positioning itself for the tremendous amount of processing that will be done at the edge because the cost and latency of moving data from myriad devices through various wireless and wired networks is too high to be useful in real time.
The common theme, whether this is being done by hyperscalers or by large enterprises that want to mimic them, is that they want to be able to react to data instantly, and without human intervention. People are just too slow for a lot of processes, with the exception of online transaction processing, which may seem fast until you look at data streaming out of edge devices or applications that require extremely fast processing of data streams, such as anomaly and fraud detection or dynamic pricing algorithms.
“Enterprises are looking to monetize fast data,” Kaneshiro explains, and as a data scientist working at Shazam, famous for its music recognition algorithms, and at the Falcon Investment Group hedge fund that is part of Goldman Sachs, it was Kaneshiro’s job do this. And as such, he knows a thing or two about the difficulties of getting systems that are cobbled together from a bunch of open source projects to provide real time analytics against data streams. “There is a true business need to increase the value of data by delivering new experiences back to end users in real time. We have been thinking of this as providing real time action, as opposed to having a human in the loop as you do with business intelligence that is really nightly batch processes running off of old data sitting in data lakes. We are really adapting to the era of machine learning, and we look at events that are coming in, transform that data and join it with multiple different data sources, perhaps make a prediction based on that data through machine learning models, and then have an automated action that has no human in the loop. We are not looking to speed up batch processing, but rather doing event-driven processing in real time.”
Just like the Hadoop distributors – Cloudera, MapR Technologies, and Hortonworks are the big ones – cobbled together the core MapReduce framework for batch processing against large amounts of data stored in the Hadoop Distributed File System – all inspired by work at Google and created by Yahoo – Streamlio is welding together three different Apache projects to create an integrated platform designed for stream processing, particularly with hooks for machine learning frameworks such as TensorFlow, Caffe2, Cognitive Toolkit, and others.
This is the new world of application programming. Large datasets moving fast not only makes machine learning possible, but the reaction times for serving billions of users requires a different approach than human beings analyzing data and coming up with algorithms manually.
Streamlio was founded in April 2017 by architects from Twitter, Yahoo, and Google, and the company dropped out of stealth mode relatively quickly in August 2017, when it announced $7.5 million in Series A funding from Lightspeed Ventures.
The core products that make up the Streamlio platform include Apache Heron, a real-time streaming system that was created by Twitter in 2014 because its Apache Storm system could not handle the load. Twitter created and open sourced Storm, too, and Heron can be thought of as a major reworking to improve scalability and response times and, significantly, allow for other job schedulers to be plugged into it. At the same time as Twitter was updating its stream processing stack, Yahoo was rolling out a new pub-sub messaging software, called Pulsar, and a related durable storage system for the message system, called BookKeeper. All three projects were released under Apache 2.0 licenses in 2016, and the co-creators of the code – Karthik Ramasamy and Sanjeev Kulkarni for Heron, Matteo Merli for Pulsar, and Sijie Guo for BookKeeper – are all co-founders of Streamlio.
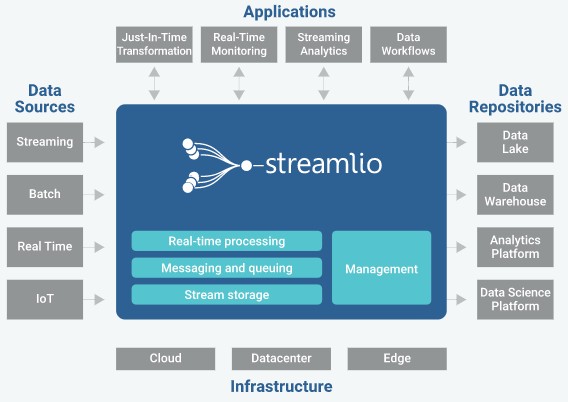
The architecture of the Streamlio stack demonstrates the philosophy that these experts from Twitter and Yahoo (and some others from Google) have with regard to real time applications. You basically need three different parts of the stack to make it all work. The compute layer is Apache Heron, which has been running applications created by over 50 teams at Twitter for the past three years and is processing 2 trillion – that’s with a “T” – events and over 20 petabytes of data per day. Apache Pulsar, which Yahoo created after LinkedIn did Kafka, is the messaging and queuing layer of the stack, and it has also been in production there for over three years, and now handles over 2 million topics and processes more than 100 billion messages a day. The streams eventually have to land somewhere after they have initially been acted upon and before they are pushed out into a data lake for more traditional batch processing for complex queries, and that is where Apache BookKeeper comes in. BookKeeper has been used in production concurrent with Pulsar at Twitter and Yahoo, and is also used by Salesforce.com. At Yahoo, it now lands more than 1.5 trillion records and more than 15 PB of data each day.
This is hyperscale, for sure, and something that Kaneshiro says enterprises that don’t need hyperscale will nonetheless take note of when they are shopping for a streaming platform for making use of machine learning or doing any other kind of event processing. Those that are pushing the scale limits will pay attention to these figures, too.
The combination of Apache Pulsar and BookKeeper is an important one for enterprises in particular. Pulsar was not only made to be fast, but also to have durability – which in the strict definition of systems means that no data is lost, it is all eventually landed somewhere and does not evaporate from the stream. Pulsar was also created with multitenancy in mind from the get-go, which means it has a concept of isolating streams and back-end repositories of them so access to them is restricted. (A necessary condition for financial services firms, for sure.) This is done by having multiple namespaces inside of Pulsar and BookKeeper. The Pulsar-BookKeeper combo also has multiple-way geo replication built into the foundation, and it has been battle tested with Yahoo running it across eight datacenters in a full mesh, active-active configuration, spreading the streams and repositories around automagically. This is not for disaster recovery purposes so much as for disaster avoidance, and the multitenancy is aware of the geo replication and that carries through multiple datacenters, not just within one cluster in a single datacenter.
While Storm had its own scheduler embedded inside of it, Pulsar was designed so the scheduler could be changed as conditions dictated. Microsoft ported the second-generation Hadoop scheduler, YARN, to Pulsar, and HashiCorp, which has a platform in its own right, has ported its Nomad scheduler to Pulsar. The combination of Mesos and Aurora is another option, as is the SLURM job scheduler from the HPC realm and the Kubernetes container controller that came out of Google and that was inspired by its Borg/Omega cluster and container scheduler. Kaneshiro says that Streamlio made a big bet early on with Kubernetes, but the Streamlio stack architecture is open so companies can do as they choose.
The new thing that is coming out this week for Streamlio at the Strata infrastructure conference in San Jose is called Pulsar functions, which is a lightweight deployment of the Pulsar/BookKeeper stack that can operate in a standalone mode from the main cluster and, as a result, is suitable for edge cases, such as filtering data before sending it back to the datacenter or for a real-time alerting system, or interpolating from the data at the edge to do some action, or scoring of machine learning models against new data at the edge. The Pulsar functions can be called from normal Java and Python code, and they are done locally in the absence of a scheduler.
“It is the simplest way, using native Java and Python, and we have provided the simplest possible compute framework for models to be deployed in the stream itself,” says Kaneshiro. “So Pulsar functions can be used to do just-in-time transformation along with model scoring and then the prediction can be written into back into a Pulsar topic and stored in the stream. We think that around 80 percent of use cases we see simply require messaging – meaning moving data with lightweight compute and stream storage. And with heavier compute and a much more complex algorithm, we have Heron in the platform as well.”
The Streamlio stack has an open core licensing model, which is a given based on the fact that the three components are under Apache licenses. Pricing is a bit in flux, considering how new Streamlio is, but it will have a per-node price and it will scale in some fashion based on whether it is in a datacenter or on the edge. What it will not have, Kaneshiro assures us, is some kind of tax on data flow – something that users dislike on public clouds. (But, if they run Streamlio on a public cloud and move their data around between regions, that is the customer’s problem.)
In addition to the formal rollout, Streamlio is also taking aim at Confluent’s Kafka stack, its main competitor at this point. The company ran some benchmarks on the AWS cloud, pitting Streamlio against Kafka for some admittedly simple stream processing and messaging workloads. Here is the result:
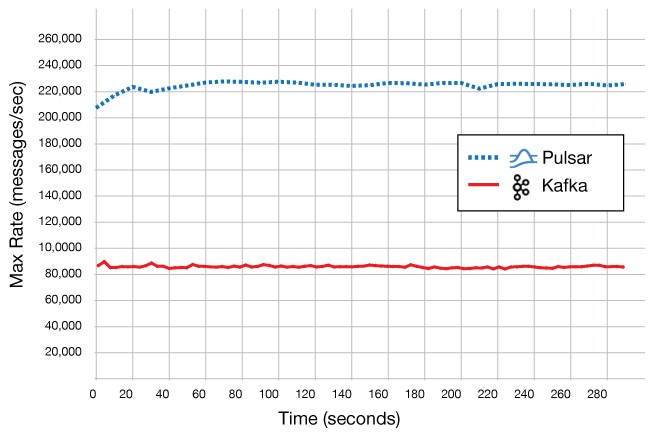
In this test, Kafka and Pulsar were running on three i3.4xlarge instances on AWS, with three Zookeeper nodes running on t2.small instances and a single c4.8xlarge instance used as a client driver. This is not exactly a massively scaled test, and it will be interesting to see how this plays out at scale. It is representative, perhaps, of an edge use case, and 2.5X better throughput and 60 percent lower latency is nothing to shake a stick at.

Gordon Bell Prize Winners Leverage Machine Learning For Molecular Dynamics
For more than three decades, researchers have used a particular simulation method for molecular dynamics called Ab initio molecular dynamics, or AIMD, which has proven itself to be the method most accurate for analyzing how atoms and molecules move and interact over a fixed time period. In this time of …

Feeding The Datacenter Inference Beast A Heavy Diet Of FPGAs
Any workload that has a complex dataflow with intricate data needs and a requirement for low latency should probably at least consider an FPGA for the job. FPGAs have, of course, been operating in the datacenter for three decades, usually under the skins of some appliance, but FPGAs are coming …
Inside Tesla’s Innovative And Homegrown “Dojo” AI Supercomputer
How expensive and difficult does hyperscale-class AI training have to be for a maker of self-driving electric cars to take a side excursion to spend how many hundreds of millions of dollars to go off and create its own AI supercomputer from scratch? And how egotistical and sure would the …
Be the first to comment