
Sometimes a database is like a collection of wax tablets that you can stack and sort through to update, and these days, sometimes it is more like a river that has a shape defined by its geography but it is constantly changing and flowing and that flow, more than anything else, defines the information that drives the business. There is no time to persist it, organize it, and then query it.
In this case, embedding a database right in that stream makes good sense, and that is precisely what Confluent, the company that has commercialized Apache Kafka, which is a distributed message queuing stack that was created by business social networker LinkedIn and open sourced in early 2011. Kafka was initially best known as a streaming service to pipe data into systems such as Hadoop, but it is gradually becoming a platform in its own right. In fact, the KSQL streaming database is the missing element to transform Kafka into a proper platform, and it is something that Confluent co-founder Neha Narkhede, who helped create Kafka and its related Samza stream processing framework that mashes up Kafka and Hadoop at LinkedIn, has wanted to do for a long time.
We live in a topsy-turvy world where databases are trying to add streaming features and streaming servers are becoming databases. Many modern applications, particularly those that need high performance for millions, tens of millions, and even billions of users, are messaging centric (like financial services applications have been for decades) and then streaming and database services hang off of these.
The KSQL overlay onto Kafka makes sense, but that doesn’t mean it has been easy to convert a firehose stream of data into something that looks and feels like a traditional SQL-driven relational database. The main purpose of the SQL interface, Narkhede tells The Next Platform, is to lower the barrier to entry to using streaming services based on Kafka, much as SQL overlays on top of Hadoop are meant to make it easier for regular SQL users to make use of the data lakes running on Hadoop that have had to write MapReduce scripts in the past to ask it questions.
Kafka itself is written in a mix of Scala and Java, and the Kafka Streams streaming processor, which is analogous to Spark Streaming, Flink, and similar systems, stores its tabular overlay in a distributed RocksDB datastore. (RocksDB is the low-level storage engine that is at the heart of the CockroachDB clone of Google’s Spanner datastore, and is itself derived from the LevelDB key/value storage engine that Google open sourced and that was inspired by its BigTable and Spanner database service.) The RocksDB datastores are sharded and distributed across a cluster of servers, and this is what gives Kafka its bandwidth and resilience. Samza mashes up the YARN job scheduler and data replication features of Hadoop with Kafka – and therefore now KSQL – into an application framework.
Editor’s Note: It would have been far funnier, of course, if Kafka woke up one morning and had been turned into CockroachDB.
KSQL, which is written entirely in Java, is a distributed, real-time SQL engine that Confluent created from scratch and that the company is open sourcing under the Apache 2.0 license just as LinkedIn did with Kafka. The KSQL overlay supports a variety of streaming functions, such as windowed aggregations to stream table joins, and it is currently in developer preview. Narkhede says that Confluent wants to spend the next four to six months getting feedback from the Kafka community to see how best to tweak it and then commercialize it for production works. It is not ready for primetime yet.
The obvious question for those who are new to streaming is why put a database into the streaming layer.
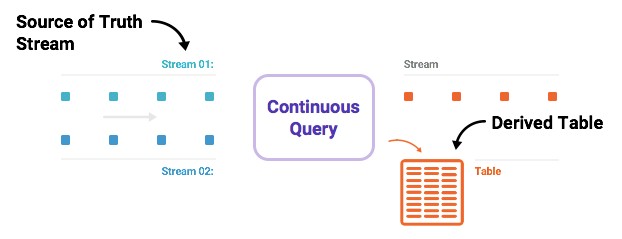
“Most relational databases are used for doing on demand lookups and modifications to data that is stored,” explains Narkhede. “KSQL is not meant to do lookups yet – it will support that very soon – but it is meant to do continuous querying, and it is in some sense turning the database inside out. The relational database has a transaction log, which is the source of truth for the system, and it has tables that are derived from this log that are the first order construct. With Kafka and KSQL, the log is a first order construct and tables are derived views and stored in RocksDB, and updates to these tables can be modeled as streams. KSQL is just an interface that sits on top of the Kafka streaming table, and you can read data as either a stream, where every update is independent of all others, or as a table, where every update is probably an update to a previous update into the stream. Once you have streaming tables, you can join them together or do aggregations on them or at some point in the near future query these tables. The beauty of this is that the table is actually quite different from the table you have in a traditional database in a sense that it is kept continuously updated as new events arrive on the stream. As streams come in, the queries either produce more events or update the tables.”
Relational databases have a similar concept called materialized views, which automatically updates the derived tables that come from the joining and aggregation of many database tables as they are have their information changed. A constantly running query runs as the data in the source tables is updated, but this data and the derived tables have to constantly be written to the disk storage underlying the database. KSQL is designed for data that is changing all the time, rather than infrequently, and keeps streaming materialized views that can be queried on the fly.
Confluent is not alone is adding an SQL layer on top of its streaming engine. The competitive Apache Flink stream processing framework, which came out of the Stratosphere project at Technical University Berlin, Humboldt-Universität zu Berlin, and Hasso-Plattner-Institut Potsdam and which we talked about here, has an SQL engine based on the Apache Calcite project. PipelineDB is a streaming database layer that runs as an extension to PostgreSQL and Vertica databases. Spark Streaming, the streams layer of the Spark in-memory database, has its own DataFrame and SQL layer to allow for querying of streams.
Strictly speaking, the KSQL database layer for Kafka will not be ANSI SQL compliant, and that is mostly because the streaming functions that are required by a streaming platform are not part of those database standards. Relational databases are table centric, and Kafka and KSQL are stream centric with the KSAL database really just being derived from the stream. (Just like the HBase database overlay created by Facebook is really derived from the Hadoop Distributed File System.) The SQL windowing functions common on relational databases needed to be heavily modified to support streams, says Narkhede, adding that this is true of all SQL layers on top of streaming systems.
The Kafka Streams and KSQL do not require very big iron. A standard X86 server with somewhere between 16 and 24 cores across two sockets, plus a reasonable amount of memory and disk and maybe some flash if the I/O requirements dictate it, will do the trick. For most customers, a 10 Gb/sec Ethernet fabric between the Kafka nodes in a cluster will suffice. It all depends on the nature of the data and the application making use of it. Where latency is important, more DRAM and flash and faster networks, and maybe even more compute or at least faster compute, may be required. If you need more streaming capacity, you just add more nodes to the Kafka cluster.
Packaging and pricing details for the commercial-grade KSQL were not divulged, and it is unlikely that pricing will be.

Everybody Has Big Data – How To Cope With It
Enterprises are awash in data, and though many are tempted to save it all for later analysis – after all it worked for Google for many years – the store then analyze approach is poorly suited to environments with data sources that never stop. Storing all data is costly if …
Vast Data Builds Out Data Platform With Block Storage And Kafka Streams
If you are going to be audacious enough to call the thing you are creating Universal Storage, then by definition it has to do everything – meaning support every kind of data format and access protocol, and do so with good performance on all fronts. And that has been the …

Refreshing Approaches to Workflow Automation
Workflow automation has been born of necessity and has evolved an increasingly sophisticated set of tools to manage the growing complexity of the automation itself. The same theme keeps emerging across the broader spectrum of enterprise and research IT. For instance, we spoke recently about the need to profile software …
“that is at the heart of the CockrockDB clone of Google’s Spanner datastore”. I think you meant CockroachDB here. 🙂
Er, yes indeed.