
Since its inception, the OpenStack cloud controller co-created by NASA and Rackspace Hosting, with these respective organizations supplying the core Nova compute and Swift object storage foundations, has been focused on the datacenter. But as the “Queens” release of OpenStack is being made available, the open source community that controls that cloud controller is being pulled out of the datacenter and out to the edge, where a minimalist variant of the software is expected to have a major presence in managing edge computing devices.
The Queens release of OpenStack is the 17th drop of software since NASA and Rackspace first got together back in July 2010. It also includes significant enhancements for managing accelerators, such as GPUs and FPGAs, that are increasingly being added to the compute nodes in OpenStack clusters. This much-needed feature will be a boon for shops running HPC and AI workloads where acceleration is the norm and are made available on shared clusters with multiple workloads that benefit from being managed in a dynamic way using OpenStack. It will also, as it turns out, be important for edge computing devices, which often have acceleration – again, usually GPUs and FPGAs – to help them efficiently process data very close to end users (meaning people) or endpoints (meaning devices and engaged in machine-to-machine data transfer as well as local processing of telemetry or other kinds of information from endpoints) on the broader computing and storage network.
We have recently come to the conclusion, like the OpenStack Foundation, that we cannot ignore the edge, and will be expanding our coverage in this area. As usual, we are interested in platforms that store and process data, not the gadgetry – consumer or commercial – that is generating it. This month, the OpenStack Foundation started up an edge computing working group, which put out an initial manifesto on how they see edge computing evolving in the coming years. (You can download that paper here.) The wireless carriers are leading this effort, with Verizon, AT&T, and SK Telecom, who are big users of OpenStack, at the forefront, with systems architects from Red Hat, Hewlett Packard Enterprise, Cisco Systems, and Inmarsat helping out as well as telco equipment provider Ericsson and, believe it or not, the Walmart Labs research and development arm of the giant retailer.
Since edge is just the next logical step in distributed computing, it is no surprise that these companies are all trying to define how OpenStack will play here. Manufacturers, financial services firms, transportation companies, and others who represent the rest of the economy will follow suit.
Many companies will end up with hundreds, thousands, or even tens of thousands of baby clouds on the edges of their datacenter networks, creating a kind of hyperdistributed architecture that is, in many ways, the exact opposite of the kind of hyperscale datacenters with a 100,000 servers in a massively dense datacenter and multiple datacenters in a geographical region that is common among the Super 8 – that’s Google, Amazon, Microsoft, Facebook, Baidu, Tencent, Alibaba, and China Mobile. Or, for another analogy, we have massively parallel computing across nodes and, with devices like GPUs and many-core CPUs, within nodes, and now we will have massively distributed clouds.
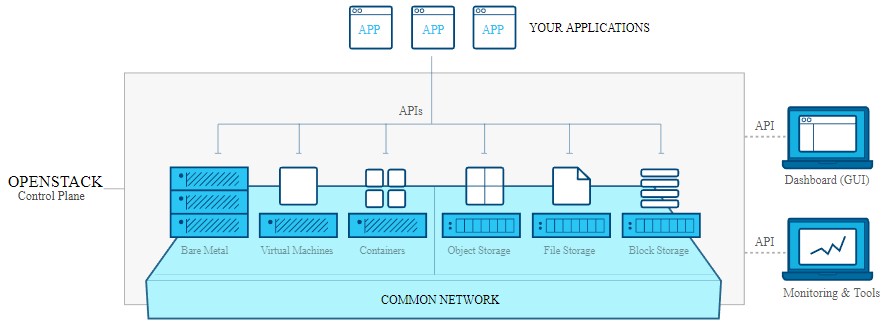
“There have been a lot of big moves in the Queens release to make this whole OpenStack thing easier to operate,” Mark Collier, chief operating officer at the OpenStack Foundation, tells The Next Platform. “These companies want to run a tremendous number of OpenStack cloudlets at the edge, and the tooling needed to do that has to be a lot more automated.”
To that end, the Helm project was started, which integrates the Kubernetes container management system and its Helm charts into operating a containerized version of OpenStack itself. But it will take more than this. Just like edge computing requires very specific processors and accelerators tuned to their workloads, OpenStack has to be trimmed and hardened so it can operate out on the edge and coordinate back with centralized datacenters, and do so seamlessly so it all looked like one, big federated OpenStack cloud. So, in the end, rather than scale a single OpenStack controller to 60 million VMs on 1 million servers in maybe a few datacenters, as was the original design goal that NASA and Rackspace Hosting had eight years ago, it may be that you end up with 60 million VMs, containers, and bare metal instances on several million edge servers in many thousands or even tens of thousands of locations. And by the way, that latter scenario is harder to operate at scale.
This is precisely what the first working group in OpenStack focused on edge computing, which met back in September, talked about. “We were pleasantly surprised to agree that OpenStack can play at the edge even down to very slimmed down devices,” says Collier.
His compatriot from Rackspace, Jonathan Bryce, who has been executive director of the OpenStack Foundation from the beginning, has been heading up the edge computing work in the OpenStack community. “In a lot of cases, whether you are talking about 5G wireless, self-driving cars, augmented or virtual reality, what have you, the proximity of the computing environment is really important just because of the performance and latency requirements of these applications,” says Bryce. “That is where we are seeing organizations building out clouds in hundreds to thousands of locations in the next few years.”
AT&T and SK Telecom worked together on Helm, and have also partnered to create another relevant project, called LOCI, which bundles OpenStack components into containers that are compliant with the Open Container Initiative format that is the result of the merger of Docker and rkt containers, working atop Kubernetes. The trick here with LOCI is not just that it is another container implementation that mirrors Helm, but rather it containerizes lightweight versions of the OpenStack services and then puts them under the direction of Helm. You can start out small, with just the Keystone identity manager and the Ironic bare metal deployment module, and manage a set of physical servers that are far from the core datacenter but still connected. Or, companies could add in Nova using Helm and LOCI, and have the ability to run virtual machines on that edgy iron.
“The issue is not just about shrinking down the OpenStack footprint to match the capabilities,” explains Bryce. “There has to be a high degree of automation. When you are running this infrastructure all over the planet, you don’t necessarily have an engineer that can physically touch the environment. And Helm and Kubernetes offer a high level of resiliency and availability for whatever services are running out there on the edge. We are seeing some of the technology come together, but we have a lot more to do. The retail and manufacturing use cases for OpenStack at the edge share some requirements with the telcos, but they also have different needs. One of the interesting challenges, if you think about AT&T and Walmart, is that they have hundreds of thousands of locations. When people talk about multicloud right now, they are talking about using two clouds – maybe OpenStack mixed with AWS – with maybe two or three regions. The game is a little different with many orders of magnitude more locations. How do you keep consistency in security and identity and capacity across all of these locations?”
One thing that will help is Ironic Rescue Mode, which allows for instance repair on bare metal machines when something goes haywire; such rescue capability has been available for virtual machines running atop hypervisors like KVM and Xen and in conjunction with the Nova compute controller for a long time. In the past year, Ironic has gone from nowhere to being deployed on 20 percent of OpenStack instances, and we think it will continue to grow, particularly as containers, which run on bare metal, take off in infrastructure.
On the accelerator front, there are two developments that are relevant that are coming out with the Queens release of OpenStack. First, the Nova compute controller can now deploy work to virtualized GPUs from Nvidia and Intel (we presume AMD GPUs are in the works). This is not just important for when the GPU is being used to do graphics processing, as with virtual desktops and workstations, but also when the GPUs on a cluster are being carved up to run HPC or AI workloads.
On a broader front, the Cyborg project, formerly known as Nomad, is coming out with the Queens release, and it is a management framework for all kinds of accelerators, including GPUs, FPGAs, DSPs, and cryptographic processors on the compute side and NVM-Express flash drives on the storage side. Cyborg can provision and deprovision these devices either through the Nova compute controller or the Ironic bare metal controller.
According to Bryce, accelerated computing is much more prevalent at the edge than in the datacenter, and so this again will bolster the position of OpenStack at the edge. The telecom vendors have been pushing from the edge, and the HPC customers have been pushing from on high in supercomputing datacenters for something like Cyborg, and now they have got it.


Rethinking The Edge In A Multicloud World
For the past decade or so, unless enterprises wanted to build more of their own datacenters, the cloud providers were the only game in town to tackle new workloads at massive scale. That capacity was available under a pay-as-you-go consumption model, which was great, until the bill arrived. In many …
Hybrid Computing Sharpens Its Edge
Computing has become more complex as the digital age has progressed. In the early days, companies had a central machine or a collection of them doing all of their processing, and then clients like PCs and then smartphones got smart and some of the work of these central processors was …

Dell Ties Storage To Kubernetes, Sharpens Edge Strategy
Dell Technologies, since its founding 37 years ago, has been about infrastructure — from the servers, networking systems and storage appliances that populate enterprise datacenters to the corporate clients that are designed to make employees more productive. Infrastructure is what has driven Dell to become a multinational IT giant that …
Be the first to comment