

Generally speaking, the world’s largest chip makers have been pretty secretive about the giant supercomputers they use to design and test their devices, although occasionally, Intel and AMD have provided some insight into their clusters.
We have no idea what kind of resources Nvidia has for its EDA systems – we are trying to get some insight into that – but we do know that it has just upgraded a very powerful supercomputer to advance the state of the art in artificial intelligence that is also doing double duty on some aspects of its chip design business.
As part of the SC17 supercomputing conference this month, Nvidia rolled out the next-generation of its “Saturn V” hybrid CPU-GPU cluster, which has substantially more performance – and a wider variety of it – thanks to its adoption of Nvidia’s own Volta” Tesla V100 GPU accelerators within its own DGX-1 server platform.
The original Saturn V system, which was rolled out at the SC16 conference last year, was based on the DGX-1 servers based on the “Pascal’ Tesla P100 GPU accelerators, which had less oomph and which did not have the Tensor Core dot product engines that make the Volta GPUs so useful for machine learning and, perhaps someday, various traditional HPC codes. That system, which we detailed last year, had 124 of the DGX-1P servers, each with two 20-core, 2.2 GHz “Broadwell” Xeon E5 processors, 512 GB of CPU memory, and eight of the P100 accelerators in the SXM2 form factor that lets them plug directly into the motherboard and implements the NVLink 1.0 interconnect. The Tesla P100 accelerators each have 16 GB of HBM2 stacked memory and are linked in a hybrid cube mesh network to each other.

Using half-precision FP16 data storage in the GPU memory, the eight Pascal GPUs can deliver 170 teraflops of aggregate performance for deep learning algorithms and 42.5 teraflops total for double precision work. The planar on the DGX-1P system has a PCI-Express switch on it to link the GPUs to a pair of two-port 100 Gb/sec InfiniBand adapters from Mellanox Technologies and a pair of 10 Gb/sec Ethernet ports that come off the Xeon chips. The system has four 1.92 TB flash SSDs for high bandwidth storage, which is necessary to keep the CPUs and GPUs fed and importantly is the fast cache for machine learning algorithms. The DGX-1P fits in a 3U enclosure and burns 3,200 watts across all of its components.
Across those 124 DGX-1P nodes, the original Saturn V system had 4.9 petaflops of peak double precision floating point performance and, running the Linpack Fortran matrix math test was able to deliver 67.5 percent computational efficiency at 3.31 petaflops, giving it the number 28 position on the November 2016 Top 500 list of “supercomputers.” At a total of 350 kilowatts for the whole shebang, that works out to 9.46 gigaflops per watt, which was the most energy efficient Linpack machine tested a year ago. The DGX-1P servers cost $129,000 a pop a list price, and taking out the value of the AI software stack and its support and adding in an InfiniBand network capable of lashing together all of the servers in a two-tiered fat tree EDR InfiniBand network, we think the original Saturn V cost around $18 million at list price, or about $3,750 per teraflops peak. This machine might be discounted in a real-world setting, but given its scarcity and high demand, maybe not.
If Intel had NVLink ports on the Xeons, performance would no doubt be better, and there is a compelling reason for Nvidia to contemplate create a Power9 variant of the DGX-1. You could, for instance, call it the DGP-1V, meaning the combination of Power9 processor, NVLink 2.0 interconnects, and Volta accelerators. With those NVLink ports on the CPUs and cache coherency across the CPU and GPU memories, performance efficiency should improve dramatically.
That brings us to the new iteration of the Saturn V system, which is based on upgraded DGX-1V systems packing the Volta GPUs. As far as we know, the DGX-1V systems have not been upgraded to the “Skylake” Xeon SP processors from Intel, and there is no compelling reason to do so considering that they cost more money than the prior generation of Broadwell Xeons for this kind of work.

The new Saturn V machine will be much more of a beast, at 660 nodes, and it will employ the Tesla V100 accelerators, which have a lot more oomph obviously. The second-gen Saturn V system has the same eight GPU accelerators per node, but this time is using the faster NVLink 2.0 interconnect to link up the GPUs to share memory and work. The cluster has a total of 5,280 Volta GPU accelerators, which yield 80 petaflops of peak performance at single precision and 40 petaflops peak at double precision, which in theory would make it among the top ten systems in the world even at double precision floating point. Thanks to the Tensor Core dot product engines, the system will have effective performance on machine learning workloads of 660 petaflops (that is a mix of FP32 and FP16).
For the Green 500 and Top 500 rankings in November, Nvidia only tested a 33 node portion of the next-gen Saturn V machine. This particular system had a theoretical peak performance of 1.82 petaflops at double precision, and yielded 1.07 petaflops on the Linpack test, for a computational efficiency of 58.8 percent. While that computational efficiency was considerably lower than on the original Saturn V, the system only burned 97 kilowatts and that worked out to nonetheless stunning 15.1 gigaflops per watt on Linpack. With a bunch of tuning, the performance could rise and the efficiency go even higher.
Nvidia did not provide pricing on its upgrade plan for the next-gen Saturn V, but the DGX-1V has a list price of $149,000 a pop, loaded up. The InfiniBand network is a bit more complex this time around, and we think more expensive, and estimate that, depending on how that network is priced (and not including an external Lustre or GPFS file system), this new Saturn V might cost somewhere around $100 million to $110 million at list price with the full AI stack support taken out, no external storage, and a pretty heft EDR InfiniBand network. If the Linpack ratios held – and there is no reason to believe it would not – across the entire 660 nodes, which have yet to be built, then sometime next year Nvidia should have a rating of around 22.3 petaflops on the full next-gen Saturn V on the Linpack test, which would make it the third highest performing system tested for the Top 500 and clearly among the top supercomputers in the world (including those that have not run Linpack and submitted them to the Top 500). And at maybe $90 million, the next-gen Saturn V machine would deliver its DP floating point Linpack at a cost of around $40,300 per teraflops – a bit more than the Pascal-based Saturn V – but yield a tremendous price/performance boost on machine learning workloads. The DGX-1P has 170 teraflops of machine learning performance at FP16, but the DGX-1V has 960 teraflops using the Tensor Cores, or a factor of 5.6X. Even if the second-generation Saturn V system cost a lot more, the bang for the buck on these machine learning training and inference jobs would be a lot better. It will be interesting to see how the street really prices these and other hybrid systems using Volta GPU accelerators. It will be tricky, indeed.
Whatever the next-gen Saturn V machine costs Nvidia to build and then sell to itself, this represents a pretty big investment for any company. People probably think Nvidia is selling the machine to itself at cost, but not so fast on that. Nvidia could have a division or multiple divisions that are using it buy it from the Tesla datacenter group for the full price and boost its reported revenues significantly in that Tesla unit. We think the company will split the difference. But it will not be anywhere near as low as what the US Department of Energy is paying for the “Summit” and “Sierra” systems for Oak Ridge National Laboratory and Lawrence Livermore National Laboratory. They are getting two machines with a combined 325 petaflops peak for a cost $325 million. If two-thirds of the flops actually can run Linpack in these machines, this is around $15,000 per teraflops. The US government is getting quite a deal, indeed. Then again, Uncle Sam has paid for the invention of this technology, so there is that.
Aside from the feeds and speeds and potential costs of the next-gen Saturn V system, there are system and network architecture considerations to think of when building such a system. Phil Rogers, a computer server architect at Nvidia, described at a session at SC17 how the new Saturn V machine is structured.
The fundamental building block is a twelve-node cluster that looks like this:
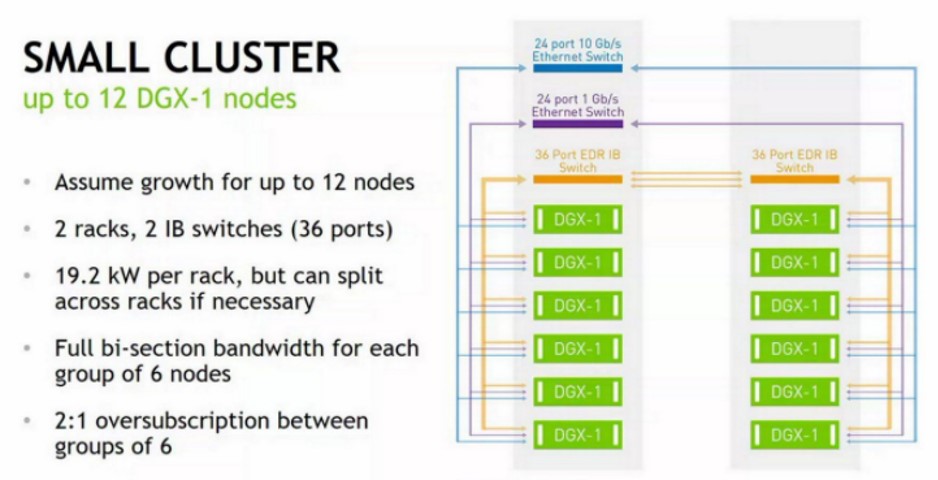
The first thing you note from the two Saturn V pictures is that you cannot, at these power densities, overstuff the racks and still use air cooling. So Nvidia is only putting six DGX-1P nodes into a rack. There is a 36-port EDR InfiniBand switch from Mellanox Technologies at the top of each rack to link the nodes to each other within the rack and across the racks. There is a 24-port 10 Gb/sec Ethernet switch for linking the nodes out to external storage and to the users of the system, and a 24 port 1 Gb/sec switch that is used to manage the DGX-1P nodes in this cluster.
The next level up, three of these small clusters are organized into a medium sized cluster, which Nvidia calls a pod, like this:
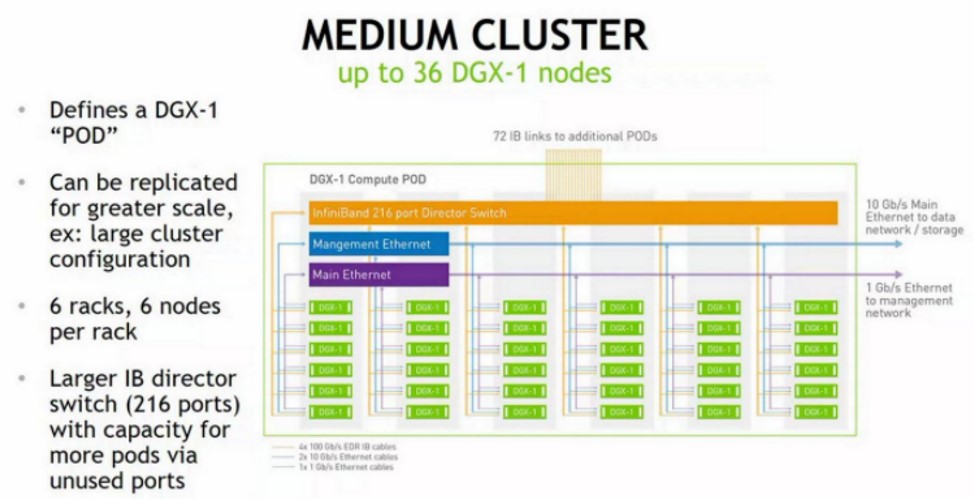
To make the pod, a 216 port EDR InfiniBand director switch is used to make another tier in the fat tree network and to cross-couple the three sets of racks to each other.
These pods are then replicated and linked by much larger modular switches in the third tier of the fat tree network, in this case using a 324-port EDR InfiniBand director switch, like this:
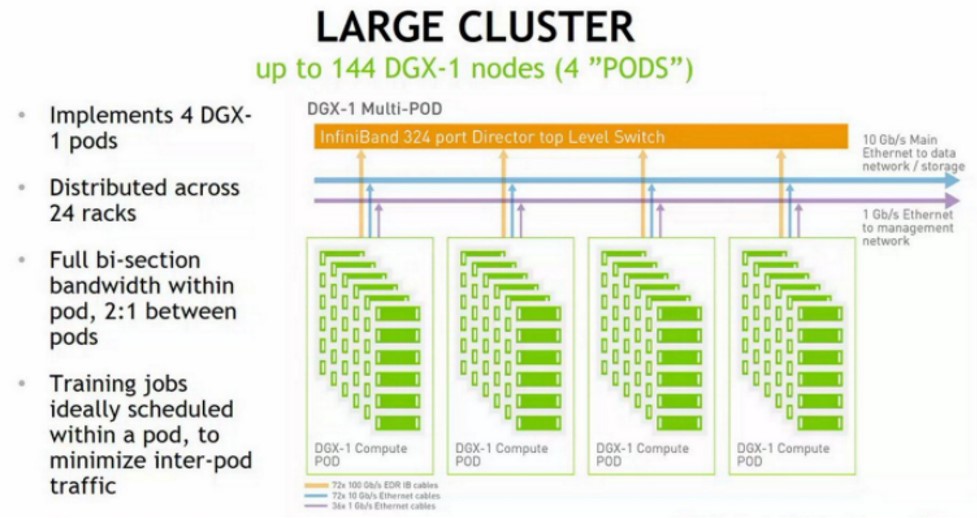
The picture above of the next-gen Saturn V shows four rows of 22 racks each with a total of 528 systems, and this picture does not map well physically to what is talked about in the Nvidia presentation unless the pods are created across six rows (meaning we cannot see them all), not side by side within rows where there are clearly 11 racks in a half row. Something is funky, and we are not sure what. We suspect that since the Saturn V upgrade is not yet fully installed, this is an error by a graphic artist, who mean to put 24 racks in a row and 12 racks in a half row. Then it all works as it should.
Rogers explained some of the “a-ha” moments in building the Saturn V systems at Nvidia. While HPC expertise can help, even with this, the similarities are limited. You pod things differently for AI workloads based on the scalability of the machine learning frameworks. If you want to drive optimal performance, then the power density cannot be too high, at least not for the air-cooled datacenter that Nvidia appears to be using. Moreover, for machine learning workloads at Nvidia, the datasets are anywhere from tens of thousands to millions of objects, which adds up to terabytes of storage on the Saturn V machines, and the read cache that those flash drives gives to nodes is particularly important for machine learning performance even if it makes no difference for Linpack.




I cannot understand why Nvidia build their supercomputer with Xeon CPUs because if they take Power CPU, they will have a better bandwidth between CPU and GPU?