
UPDATED: It is funny what courses were the most fun and most useful when we look back at college. Both microeconomics and macroeconomics stand out, as does poetry writing, philosophy, and religious studies despite the focus on engineering and American literature.
The laws of supply and demand rule our lives as much as the laws of electromagnetic radiation and gravity, and plotting out those pricing curves and seeing the effects of supply shortages and demand collapse, and the phenomenon of diminished marginal returns, was fascinating.
But when we started in the IT industry, the real illustration of supply and demand came from creating quarterly pricing guides for new and secondhand mainframe and minicomputer systems. And what we learned from this, among many things, is the concept that the price of a thing is what the market will bear. And sometimes, customers buying expensive and vital systems just have to grin and bear it because there is not perfect elasticity of demand and supply that makes all those curves as smooth as they looked in the textbooks. It gets jaggy, and sometimes, vendors are opportunistic and they charge a premium for capacity just because they can.
What was true of mainframes in the late 1980s and early 1990s – good heavens, is this stuff expensive – is true of GPU-accelerated systems, which are creating the gravity at the core of the AI galaxy. The cost of AI hardware, whether you buy it or rent it, is the dominant expense of AI startups the world over, and at this point somewhere around 80 percent to 85 percent of the money in these systems is going to Nvidia for GPUs, system boards, and networking. But the cloud providers like Microsoft, Google, and Amazon Web Services are trying to get their pieces of this AI training action, and it is with this in mind that we took our trusty Excel spreadsheet out and analyzed the heck out of the P5 GPU instances from AWS, which are based on Nvidia’s “Hopper” H100 GPU accelerators.
The P5 instances are the fourth generation of GPU-based compute nodes that AWS has fielded for HPC simulation and modeling and now AI training workloads – there is P2 through P5, but you can’t have P1 – and across these, there have been six generations of GPU nodes based on various Intel and AMD processors and Nvidia accelerators. It is interesting to be reminded that AWS skipped the “Pascal” P100 generation in these P-class instances; that had somehow escaped us. AWS tested the HPC waters with Nvidia “Kepler” K80 accelerators back in 2016 and jumped straight to the “Volta” V100s a year later, and has put out two variations of these Volta instances – the first based on Intel’s “Broadwell” Xeon E5 CPUs, and the other used a fatter “Skylake” Xeon SP processor – and two variations based on the “Ampere” A100 GPUs – one using A100s with 40 GB of memory and the other using A100s with 80 GB of memory.
The P5 instances come in one size – 48 Extra Large – and have eight H100s and NVSwitch interconnects linking them all. These GPUs are married to a node with a pair of 48-core AMD “Milan” Epyc processors that have 2 TB of memory, 30 TB of NVM-Express flash for local storage, and eight network cards running at 400 Gb/sec with RDMA (for a total of 3.2 Tb/sec of aggregate bandwidth) that we presume is Ethernet (not InfiniBand) plus 80 Gb/sec of Ethernet bandwidth coming out of a Nitro DPU and into the Elastic Block Storage service running on AWS. The H100 GPUs have 80 GB of HBM memory with 3 TB/sec of bandwidth each. This is essentially a variant of Nvidia’s DGX H100 design.
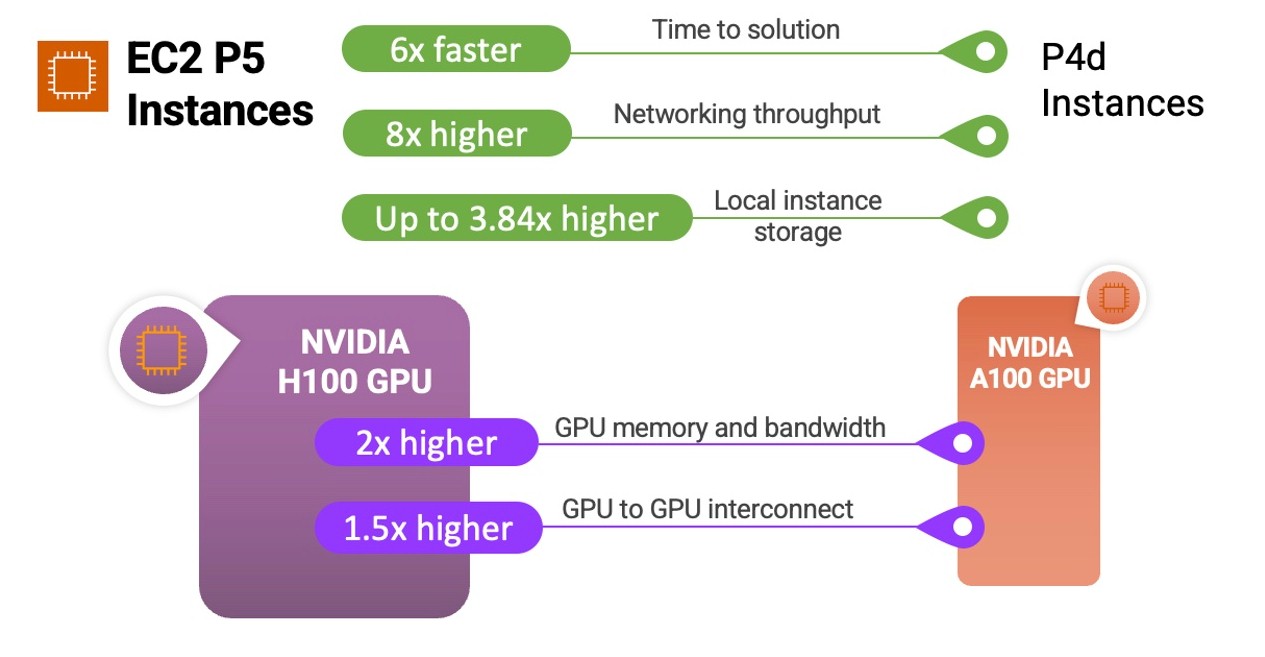
In its announcement, AWS said that the new P5 instances will reduce the training time for large language models by a factor of six and reduce the cost of training a model by 40 percent compared to the prior P4 instances. Part of the reason this is true is that AWS charged a premium for its A100 GPU
We like a longer trendline than two generations here at The Next Platform, which is why we built a salient characteristics table that brings together the P2, P3, P4, and P5 instances, what it costs to rent them on demand or with one-year or three-year reserved instances. And, because we are insane, we tried to figure out what it has cost AWS to build each of these instances, what it costs AWS to house, power, and cool these instances, and how the operating margins for these P-class GPU instances might compare to overall AWS operating margins over time. Take a look:
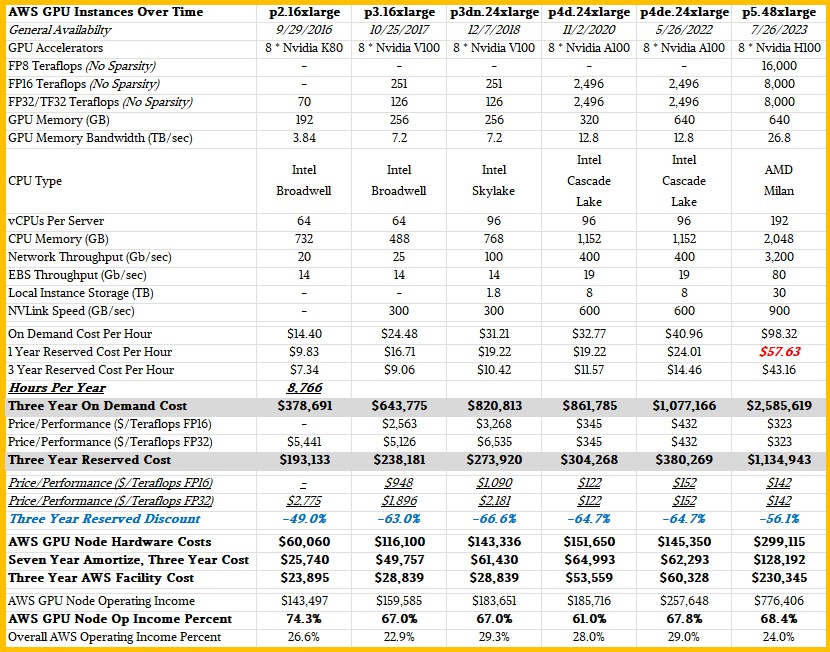
The on demand and reserved pricing for all of these instances, excepting the one-year reserved for the P5, are real, and we think that the three-year reserved is a good way basis on which to try to figure out what profits AWS is extracting from these machines and to find a away to compare AWS UltraClusters with 20,000 H100 GPUs – which AWS says it can build for customers using the P5 instances – to other monstrous clusters that others have built, are building, or are rumored to be building to run LLMs at trillion parameter and trillion token scales.
If you use FP32 single-precision floating point math – the K80s did not have FP16 support – the performance of the GPU nodes offered by AWS from the P2 to the P5 has increased by a factor of 115X, but the price to rent it for three years has increased by 6.8X, which means the price/performance has improved by a factor of 16.8X Power consumption per node has risen by about 8.1X over that same time, from 2016 through 2023.
To figure out an operating profit for the P-class GPU nodes in the table above, we assumed peak power usage, which we realize is a worst case scenario. We calculated the electricity use of the nodes, and then added on more power consumption to cover the cooling of the machines. (In general, about 40 percent of the total electric bill for gear in the datacenter is for cooling and the other 60 percent is for running it.) We also calculated the 30 year cost of datacenter space (which runs at between $7 to $12 per watt and which we took the midpoint at $9.50 per watt), and added three years of cost on that. This is the AWS Facility cost in the chart above. We also estimated the cost of buying a node and its share of the network cost, which is what the AWS GPU Node Hardware Cost represents.
Here is the update: In the original story, we amortized the cost of the server and networking hardware over three years by accident when we meant to do it over seven years and then allocate only three years of the hardware cost. We think these instances will be useful for this long — as long as there is more demand for AI processing than there is supply. Nvidia A100s will also have such a long life, too. We applied the same rules to the machines back in time, too, and that is probably being a bit generous.
Assume the best-case scenario where all of these P-class instances are reserved for three years – which is the least costly way to consume capacity on the AWS cloud – you can back out the estimated hardware and facility costs and get an operating income of sorts. We show that as well as the overall AWS operating income in the quarter closest to the one where these instances launched. (We don’t have Q2 2023 numbers from AWS yet, so we had to use Q1 data to compare to the P5 instances.)
As you can see, renting a P5 instance – and in particular, the only instance available is the p5.48xlarge, which is the whole server node –for three years reserved would cost you $1.13 million, which is a heck of a lot lower – well, 56.1 percent lower – than renting such capacity on demand, which would cost $2.58 million. No one is going to do on demand for three years, but this math shows the relative price per unit of compute depending on the acquisition strategy, and that is important. If you make your demand known, then AWS can put you on the supply curve and give you a discount for being predictable, which is another axis on the supply demand curve.
As you can see, assuming our math is in the right ballpark, even with all of these costs in there, AWS is going to make a pretty good operating profit on these P5 instances. Just as it has done with prior P-class generations. And assuming that there is a mix of on demand capacity mixed in with the reserved instances – 60 percent reserved versus 40 percent on demand – doubles the aggregate operating income over three years for a P5 instance.
And funnily enough, the operating income that AWS extracts from GPU-based instances will give it the cash it needs to invest in its homegrown Trainium compute engines for AI training and its Inferentia compute engines for AI inference. And AWS can do with AI engines that it has done with homegrown Graviton Arm server chips compared to X86 processors from Intel and AMD: Offer better bang for the buck on a hardware stack that it completely owns.
It’s a brilliant strategy, really, especially when the profits from AWS mean that Amazon itself is getting its massive IT operation for supporting its various and growing number of business units for free.
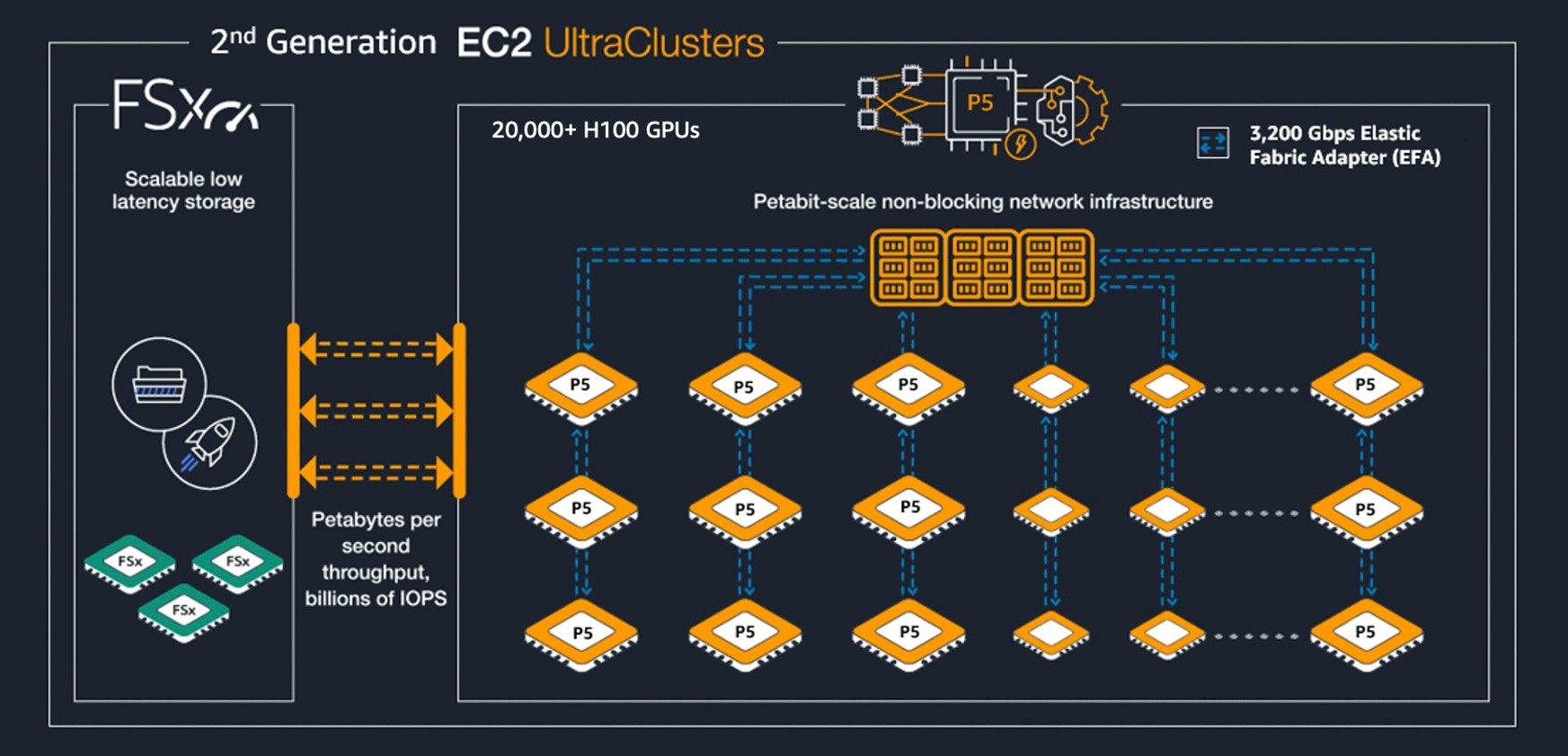
Amazon says that it can gang up more than 20,000 H100 GPUs into an EC2 UltraCluster configuration and deliver 20 exaflops of aggregate peak computing performance based on its P5 instances. Those EC2 UltraClusters have local storage in the P5 nodes and access to the FSx implementation of the Lustre parallel file system, which is running on AWS storage and which can deliver “petabytes per second throughput, billions of IOPs,” as AWS put it.
Just for fun, given the cost and rental data we ginned up above, we put an AWS EC2 UltraCluster with 20,000 H100s up against some of the big AI systems that we know are being built either in the clouds or in HPC centers in the United States. This table just keeps getting more and more interesting as we add vendors. Take a gander:
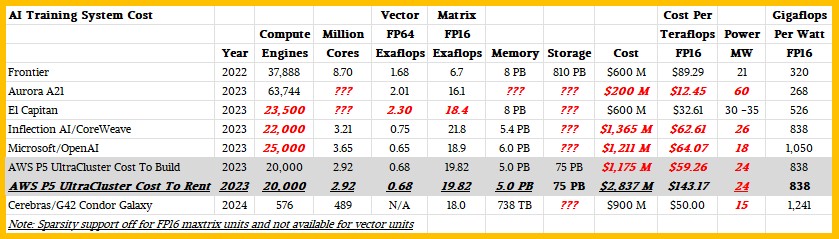
As close as we can make it, the prices of these AI systems do not include non-recurring engineering costs or power and cooling. The P5 cluster rental from AWS, of course, does, which we wanted to do to show the spread between the cost to own and the cost to rent. The Frontier, Aurora A21, and El Capitan machines at three US Department of Energy laboratories are designed predominantly for HPC workloads, but they are absolutely going to be formidable AI machines based on their peak aggregate FP16 performance ratings. The Inflection AI machine is being built by Nvidia and CoreWeave and the Microsoft/OpenAI machine is rumored to be constructed by Microsoft Azure so OpenAI can run even larger models, most likely GPT5.
The Aurora 21 price has been lowered by a $300 million writeoff that Intel took last year in its Intel Federal unit, which we think covered the cost for delays in this machine at Argonne National Laboratory. If this indeed happened, then Argonne is getting one hell of a deal – and deserves it, too. This will be a very hot machine, consuming lots of power, though, if the expected 60 megawatt power bill comes in.
Given all of these prices, and how competitive the Condor Galaxy cluster that Cerebras Systems is building for AI researcher and cloud operator Group 42 (G42), you can see now why AWS is very committed to its homegrown Trainium AI training compute engine, and also why Meta Platforms will etch its own training chips, too. At these prices, you might as well.


Even The World’s Largest Multiuser System Has Its Financial Limits
Watching Amazon Web Services explode on the scene and grow to ginormous size has been a thing to behold. While we believe that a return to utility computing was inevitable because of the economics of large scale computing – and we believed that a long time before AWS was launched …
Move Over X86, Amazon’s Arm HPC instances Are Live
When it comes to deploying Arm in the cloud, a lot of the talk of late has centered on things like efficiency, core density, or predictability of performance. However, Amazon Web Services believes that its Arm chips can compete on performance and price/performance, and in the very picky HPC market …

GPU Shortages Will Prop Up The Clouds In More Ways Than One
For the last two quarters at least, the generic infrastructure server market – the one running databases, application servers, various web layers, and print and file serving workloads the world over – has been in a recession. Companies are not buying as many servers as they might have otherwise, and …
Auroxo hybrid xvd platform
Amnenegeziana 2
WhiTch hetch
Fyi
Laah
Don’t forget how difficult it is to get AWS to just rent you a single big machine. You can’t just ask for quota sufficient to run a single H100 machine: you have to spend some real money renting lesser systems until AWS thinks you are credible enough to use an H100 system.
>>you can see now why AWS is very committed to its homegrown Trainium AI training compute engine, and also why Meta Platforms will etch its own training chips, too. At these prices, you might as well.<<
Two factors to consider, SW Ecosystem, CUDA is default, and cost to develop and deploy.
H100 is already pretty formidable. Then add Grace CPU as a mid-life-kicker to raise the bar another notch. Nobody wants to be beholden to a single vendor. But this is exactly the way Nvidia destroyed 3DFX and every other 3D chip guy in early 2000s: "the relentless pace of new products," if I recall Scott Sellers, 3DFX founder's, quote correctly.
How can an AMD Milan server with 8 NVMe drives and NVSwitch possibly have 3200Gb of nw bandwidth (unless it means 1600Gb in each direction) given that out of 160 PCIe 4.0 lanes 32 lanes are used by NVMe drives and at least 32 for CPU interfaces to NVSwitch – and remaining 96 lanes (or less) i.e. 6 x16 slots can’t provide enough bandwidth (unless it’s 2×1600 Gbs). Am I missing something?
There’s no way hw cost for this AWS instance is almost 470K$ listed above because retail cost (qty 1) for a more modern and faster platform ( AMD Genoa or Intel 4th Gen) with the same config (2x48core CPUs / 8 H100 SXM5 / 2TB RAM RAM / 8×3.84TB NVMe /8 dual port 200GbE) is between 310K$ and 340K$ (or less) so in my view it’s highly unlikely that AWS (given their purchase volumes) is paying more than 250K$ per server.