

The Global Scientific Information and Computing Center at the Tokyo Institute of Technology has been at the forefront of accelerated computing, and well before GPUs came along and made acceleration not only cool but affordable and normal. But its latest system, Tsubame 3.0, being installed later this year, the Japanese supercomputing center is going to lay the hardware foundation for a new kind of HPC application that brings together simulation and modeling and machine learning workloads.
The hot new idea in HPC circles is not just being able to run machine learning workloads side by side with simulations, but to use machine learning to further accelerate the simulation, and we have a future feature story underway, based on conversations with researchers at TiTech and at Oak Ridge National Laboratory, where the “Summit” hybrid CPU-GPU system is being built for the US Department of Energy, about this very topic. Suffice it to say, the idea is to integrate machine learning into the simulation, to do some of the computationally intensive stuff in a new way. So, as part of a climate model, you teach the system using machine learning to predict the weather by watching movies of the weather, or in astronomy, you use machine learning to remove the noise from the signal to find the interesting bits of a star field.
To do such work, you can’t really have two separate machines, and ideally, you would use a single system to do simulation, machine learning, and visualization because in this way, you don’t have to move massive amounts of data from one cluster to another to perform these tasks. (Historically, visualization and computation have often been done by different clusters in supercomputing centers.)
Obviously, for such an integrated AI-HPC workflow, you need to build what Nvidia and IBM have been calling an “AI supercomputer,” and these days, when it comes to machine learning, the GPU accelerator is by far the computational engine of choice. It is equally obvious that the GPU has found its place as an accelerator for traditional HPC simulations and models, too, as evidenced by the latest Top 500 supercomputer rankings. The Tsubame 3.0 system that TiTech is building aims to be such a hybrid machine.
One of the main themes of The Next Platform is that HPC innovators monkey around with new technologies, and those that work and that are appropriate for the enterprise eventually jump sideways into hyperscale and cloud environments or trickle down into the enterprise. The hybrid AI supercomputer is more of a collision between traditional simulation workloads at HPC centers and the deep learning workloads perfected at hyperscalers, and it is the HPC folks who are learning from the hyperscaler folks. And there is absolutely nothing wrong with that.
Acceleration Is A Long And Winding Road
TiTech was way out in front of the HPC community when it built the Tsubame 1.0 supercomputer using a mix of Opteron-based “Constellation” systems from Sun Microsystems, with InfiniBand interconnect and floating point accelerators from ClearSpeed Technologies, way back in 2006. (Japanese supercomputer maker NEC was the prime contractor on the deal and Sun supplied the hardware.)
That Tsubame 1.0 machine was comprised of 655 of Sun’s eight-socket Galaxy 4 server nodes equipped with two-core Opteron processors with a then-massive 21.4 TB of aggregate main memory and a peak theoretical performance of 50.4 teraflops at double precision. Then, 360 of these Tsubame 1.0 nodes were equipped with ClearSpeed CX600 SIMD acceleration cards, which provided an additional 35 teraflops of double-precision. The nodes were lashed together with 10 Gb/sec InfiniBand switches from Voltaire (now part of Mellanox Technologies), with two ports per server for redundant rails, as they say in the HPC lingo. That network provided 13.5 TB/sec of aggregate bandwidth and 3 Tb/sec of bi-sectional bandwidth, and was linked to a 1 PB Lustre array based on Sun’s “Thumper” storage and providing 50 GB/sec of storage I/O bandwidth. When the Linpack Fortran benchmark test was run on Tsubame 1.0, it had a sustained performance of 38.2 teraflops. It took up 76 racks and burned 1.2 megawatts.
There was an interim upgrade to Tsubame 1.1 and 1.2 with fatter memory nodes, some faster Opterons and ClearSpeed accelerators and a few Tesla GPU accelerators through 2008, but the next big jump at TiTech was with Tsubame 2.0, which was unveiled in May 2010. This machine was built through a partnership with NEC and Hewlett Packard Enterprise, with NEC as the primary contractor again and HPE supplying the super-dense ProLiant SL series enclosures that were designed explicitly to pack a lot of Nvidia Tesla GPU accelerators into a two-socket Intel Xeon server node.
The ProLiant SL390G7 nodes had two custom “Westmere-EP” Xeon X5670 processors with six cores running at 2.93 GHz with 96 GB of memory, with two 60 GB SSDs and two 120 GB SSDs in each node. The nodes had three of Nvidia’s Tesla M2050 accelerators, based on its “Fermi” generation of GPUs, and each node provided at total of 1.6 teraflops of compute, 400 GB/sec of memory bandwidth, and 80 Gb/sec of network bandwidth. The 1,408 nodes in the Tsubame 2.0 system were linked together using 40 Gb/sec InfiniBand switches, with the fat tree configuration providing around 220 Tb/sec of bisection bandwidth. Tsubame 2.0 had Lustre file systems built by DataDirect Networks, linked by 40 Gb/sec InfiniBand and with a total capacity of 11 PB. The whole shebang was rated at around 2.4 petaflops peak with 100 TB of main memory and 200 TB of SSD capacity, and amazingly it fit into only 42 racks and burned only 1.4 megawatts.
With the Tsubame 2.5 upgrade, the Xeon nodes remained the same and TiTech switched out the Tesla M2050s for Tesla K20X GPUs powered by “Kepler” family GPUs. Each Kepler K20X GOU had 1.31 teraflops of double precision and 3.95 teraflops of single precision floating point oomph and the GPUs had 6 GB of GDDR5 memory, double that of the Tesla M2050s. The node performance was more than double at double precision and more than quadrupled at single precision, with Tsubame 2.5 hitting a peak 5.76 petaflops double precision, all in the same 42 racks and now back down to 1.2 megawatts of power.

The Tsubame 3.0 machine unveiled this week in Japan was developed in conjunction with SGI, now part of HPE after the acquisition last year, and is a co-design project between TiTech and SGI with a modified version of its ICE XA systems tailored specifically to the needs of the Japanese supercomputing center.
The details are a little thin right now on Tsubame 3.0, but here is what we know. The Tsubame nodes are based on the latest generation of “Pascal” Tesla P100 accelerators from Nvidia, and from the picture below it looks like it has two CPUs and four Tesla P100s, all water cooled.

What we know from the statement put out by TiTech is that Tsubame 3.0 will have 2,160 GPUs in total, which means that if those four elements to the right of the image are GPUs, then the whole system will have 540 blades. You might presume, because the machine is being installed this summer, that Tsubame 3.0 will be using Intel’s forthcoming “Skylake” Xeon processors, which are due around the middle of this year. The two compute elements on the right of the blade are the processors, and it would be funny if they were Power9 chips from IBM, which have native NVLink ports for lashing GPUs tightly to CPUs. As it turns out, it TiTech is using neither Skylake Xeons or Power9s, but rather “Broadwell” Xeon E5-2680 v4 processors, which have 14 cores spinning at 2.4 GHz and which fit in a 120 watt thermal envelope.
That low thermal envelope plus the water cooling is how HPE/SGI is able to cram all of this compute into a space that is less than 1U tall in the rack.
We wonder if the Tsubame 3.0 blade design will allow an upgrade to future “Volta” Tesla V100 GPU accelerators, which are expected to be unveiled later this year at the GPU Technical Conference and which will debut, we think, in the Summit machine going into Oak Ridge.
With all of those CPUs and GPUs, Tsubame 3.0 will have 12.15 petaflops of peak double precision performance, and is rated at 24.3 petaflops single precision and, importantly, is rated at 47.2 petaflops at the half precision that is important for neural networks employed in deep learning applications. When added to the existing Tsubame 2.5 machine and the experimental immersion-cooled Tsubame-KFC system, TiTech will have a total of 6,720 GPUs to bring to bear on workloads, adding up to a total of 64.3 aggregate petaflops at half precision. (This is interesting to us because that means Nvidia has worked with TiTech to get half precision working on Kepler GPUs, which did not formally support half precision.)
As with past Tsubame machines, the Tsubame 3.0 nodes are being equipped with fast, non-volatile storage, and in this case, each node has 1.08 PB of such storage. We do not know if it is NAND flash or 3D XPoint memory, but it could be either. Each node also has 256 GB of main memory.
TiTech has chosen Intel’s Omni-Path interconnect to lash the nodes together in the Tsubame 3.0 machine, and this is at the current 100 Gb/sec speed, not the future 200 Gb/sec speed that is not expected until 2018 or so from Intel. Each node has four Omni-Path ports. NVLink is being used to hook the four GPUs on each Tsubame 3.0 blade to each other, but as Broadwell Xeons do not have native NVLink ports, the GPUs are linking to the CPUs over slower PCI-Express lanes. It is not clear if this is done directly or using a PCI-Express switch between the compute elements.
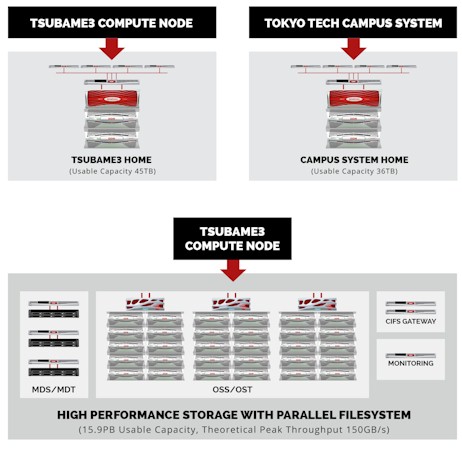
For external storage on Tsubame 3.0, TiTech has once again tapped DDN. In this case, Tsubame 3.0 will store data external to the in-node working storage on three ES14KX Lustre appliances, which will have an aggregate capacity of 15.9 PB and have a peak theoretical throughput of 150 GB/sec.
We will be following up on the hardware and software stacks on this system, so stay tuned.



Be the first to comment