

In the U.S. it is easy to focus on our native hyperscale companies (Google, Amazon, Facebook, etc.) and how they design and deploy infrastructure at scale.
But as our regular readers understand well, the equivalent to Google in China, Baidu, has been at the bleeding edge with chips, systems, and software to feed its own cloud-delivered and research operations.
We’ve written much over the last few years about the company’s emphasis on streamlining deep learning processing, most notably with GPUs, but Baidu has a new processor up its sleeve called the XPU. For now, the device has just been demonstrated in FPGA, but if it continues to prove useful for AI, analytics, cloud, and autonomous driving the search giant could push it into a full-bore ASIC.
The architecture they designed is aimed at this diversity with an emphasis on compute-intensive, rule-based workloads while maximizing efficiency, performance and flexibility, says Baidu researcher, Jian Ouyang. He unveiled the XPU today at the Hot Chips conference along with co-presenters from FPGA maker, Xilinx.
The XPU aims to strike a balance between performance/efficiency and an ability to tackle diverse workloads. FPGA accelerators alone are good for tackling specific workloads, but diversity is growing with big and smaller kernels meshing (consider a large convolution kernel and smaller ones like activations or element-wise operations, for instance).
“The FPGA is efficient and can be aimed at specific workloads but lacks programmability,” Ouyang explains. “Traditional CPUs are good for general workloads, especially those that are rule-based and they are very flexible. GPUs aim at massive parallelism and have high performance. The XPU is aimed at diverse workloads that are compute-intensive and rule-based with high efficiency and performance with the flexibility of a CPU,” Ouyang says. The part that is still lagging, as is always the case when FPGAs are involved, is the programmability aspect. As of now there is no compiler, but he says the team is working to develop one.
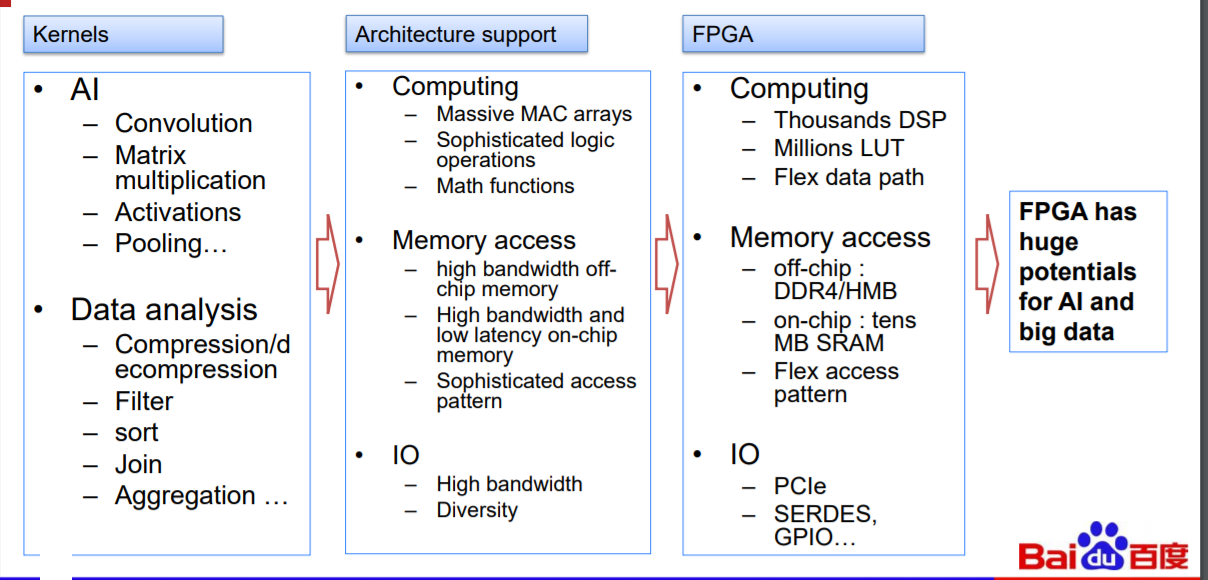
“To support matrix, convolutional, and other big and small kernels we need a massive math array with high bandwidth, low latency memory and with high bandwidth I/O,” Ouyang explains. “The XPU’s DSP units in the FPGA provide parallelism, the off-chip DDR4 and HBM interface push on the data movement side and the on-chip SRAM provide the memory characteristics required.”
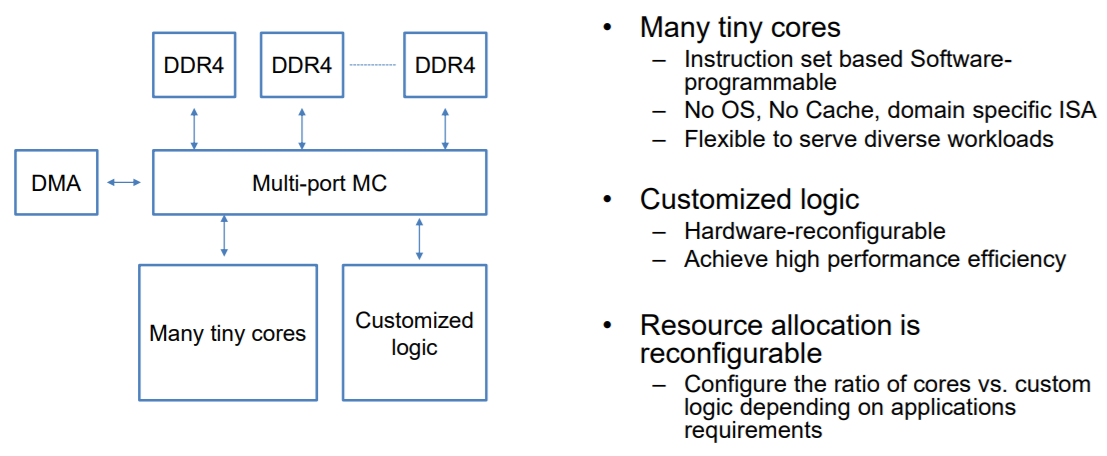
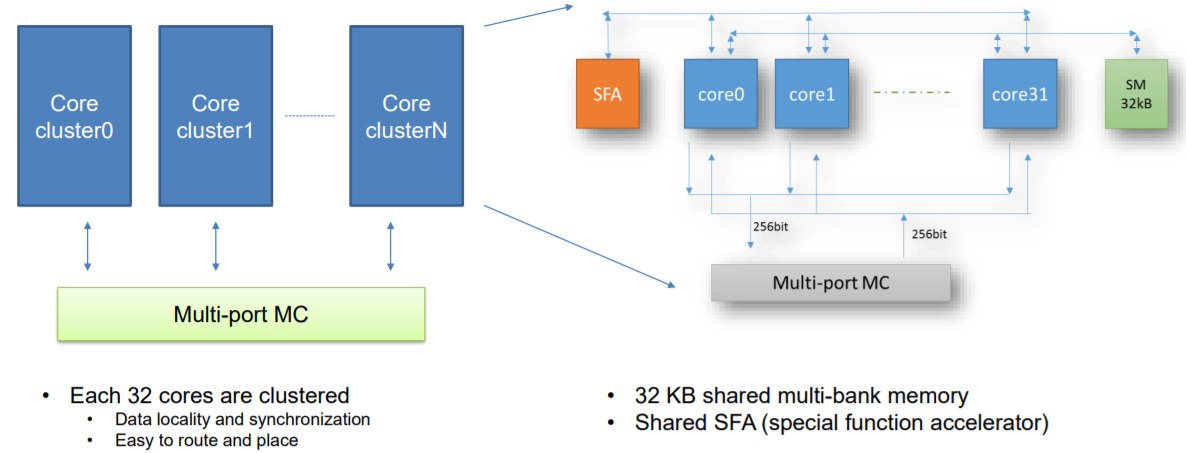
“The XPU has similar efficiency as an X86 core for compute-intensive and regular memory access workloads when tested on microbenchmarks. The scalability for XPU for workloads with data synchronization should be improved further, and the scalability of XPU for workloads without data synchronization is linear with the core number,” Ouyang adds.
Here’s the sticking point. As mentioned, there is still no compiler for this device. It is currently implemented on the FPGA and customized logic provides informative commands. The tiny cores are similar to CPUs in that one writes assembler code for these and all execution is controlled by the host. The pipeline consists of partitioning the workload, writing the XPU code and calling the dedicated logic functions so they can compile and run in Linux.
“We’ve been using FPGAs for many years already at Baidu,” Ouyang says. “We have thousands of them in our datacenters or cloud and autonomous driving and we know well their advantages and disadvantages and how to improve them. We are focused on diverse workloads with large kernels with the XPU.”
If some of what you’ve seen above looks familiar, remember how last year we profiled a SQL accelerator from the company based on Baidu’s SDA for deep learning. The SA architecture, which is data flow based is at the core of the memory bandwidth and latency advantages Ouyang described with the XPU.
He did present a few benchmarks this year but they were very roughly delivered (not much detail) and we feel more comfortable getting the data first and looking at those in more depth before sharing. Again, remember this is just a first look. We were only able to capture the details presented and questions were answered in what amounts to a short sentence. We’ll share the full paper when it emerges.




Now anyone still doubting why Intel acquired Altera will be silenced soon. AMD/Qualcomm would do good to go in an alliance with Xillinx.
And nVidia might be toast in the long run.
Should the 1st slides of Baidu be DDR4/HBM rather than DDR4/HMB?