

While much of the work at Baidu we have focused on this year has centered on the Chinese search giant’s deep learning initiatives, many other critical, albeit less bleeding edge applications present true big data challenges.
As Baidu’s Jian Ouyang detailed this week at the Hot Chips conference, Baidu sits on over an exabyte of data, processes around 100 petabytes per day, updates 10 billion webpages daily, and handles over a petabyte of log updates every 24 hours. These numbers are on par with Google and as one might imagine, it takes a Google-like approach to problem solving at scale to get around potential bottlenecks.
Just as we have described Google looking for any way possible to beat Moore’s Law, Baidu is on the same quest. While the exciting, sexy machine learning work is fascinating, acceleration of the core mission-critical elements of the business is as well—because it has to be. As Ouyang notes, there is a widening gap between the company’s need to deliver top-end services based on their data and what CPUs are capable of delivering.
As for Baidu’s exascale problems, on the receiving end of all of this data are a range of frameworks and platforms for data analysis; from the company’s massive knowledge graph, multimedia tools, natural language processing frameworks, recommendation engines, and click stream analytics. In short, the big problem of big data is neatly represented here—a diverse array of applications matched with overwhelming data volumes.
When it comes to acceleration for large-scale data analytics at Baidu, there are several challenges. Ouyang says it is difficult to abstract the computing kernels to find a comprehensive approach. “The diversity of big data applications and variable computing types makes this a challenge. It is also difficult to integrate all of this into a distributed system because there are also variable platforms and program models (MapReduce, Spark, streaming, user defined, and so on). Further there is more variance in data types and storage formats.”
Despite these barriers, Ouyang says teams looked for the common thread. And as it turns out, that string that ties together many of their data-intensive jobs is good old SQL. “Around 40% of our data analysis jobs are already written in SQL and rewriting others to match it can be done.” Further, he says they have the benefit of using existing SQL system that mesh with existing frameworks like Hive, Spark SQL, and Impala. The natural thing to do was to look for SQL acceleration—and Baidu found no better hardware than an FPGA.

These boards, called processing elements (PE on coming slides), automatically handle key SQL functions as they come in. With that said, a disclaimer note here about what we were able to glean from the presentation. Exactly what the FPGA is talking to is a bit of a mystery and so by design. If Baidu is getting the kinds of speedups shown below in their benchmarks, this is competitive information. Still, we will share what was described. At its simplest, the FPGAs are running in the database and when it sees SQL queries coming it, the software the team designed (and presented at Hot Chips two years ago related to DNNs) kicks into gear.
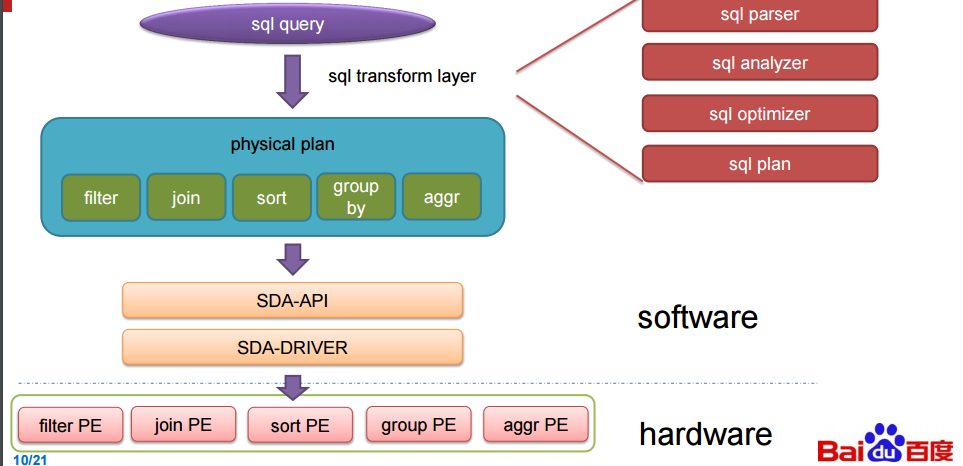
One thing Ouyang did note about the performance of their accelerator is that their performance could have been higher but they were bandwidth limited with the FPGA. In the evaluation below, Baidu setup with a 12-core 2.0 Ghz Intel E26230 X2 sporting 128 GB of memory. The SDA had five processing elements (the 300 MHzFPGA boards seen above) each of which handles core functions (filter, sort, aggregate, join and group by.).
To make the SQL accelerator, Baidu picked apart the TPC-DS benchmark and created special engines, called processing elements, that accelerate the five key functions in that benchmark test. These include filter, sort, aggregate, join, and group by SQL functions. (And no, we are not going to put these in all caps to shout as SQL really does.) The SDA setup employs an offload model, with the accelerator card having multiple processing elements of varying kinds shaped into the FPGA logic, with the type of SQL function and the number per card shaped by the specific workload. As these queries are being performed on Baidu’s systems, the data for the queries is pushed to the accelerator card in columnar format (which is blazingly fast for queries) and through a unified SDA API and driver, the SQL work is pushed to the right processing elements and the SQL operations are accelerated.
The SDA architecture uses a data flow model, and functions not supported by the processing elements are pushed back to the database systems and run natively there. More than any other factor, the performance of the SQL accelerator card developed by Baidu is limited by the memory bandwidth of the FPGA card. The accelerator works across clusters of machines, by the way, but the precise mechanism of how data and SQL operations are parsed out to multiple machines was not disclosed by Baidu.
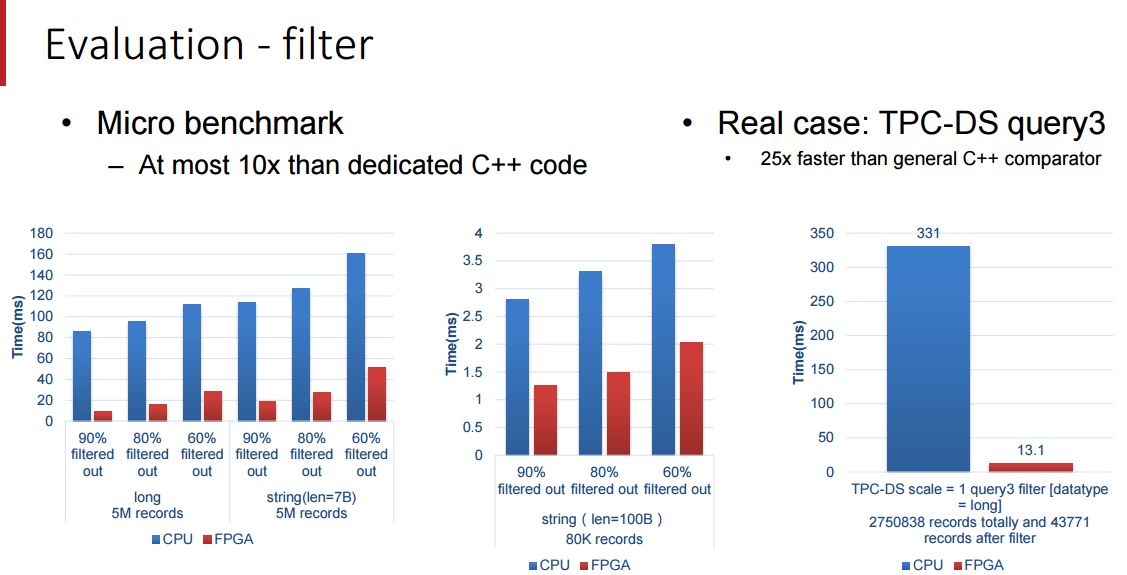
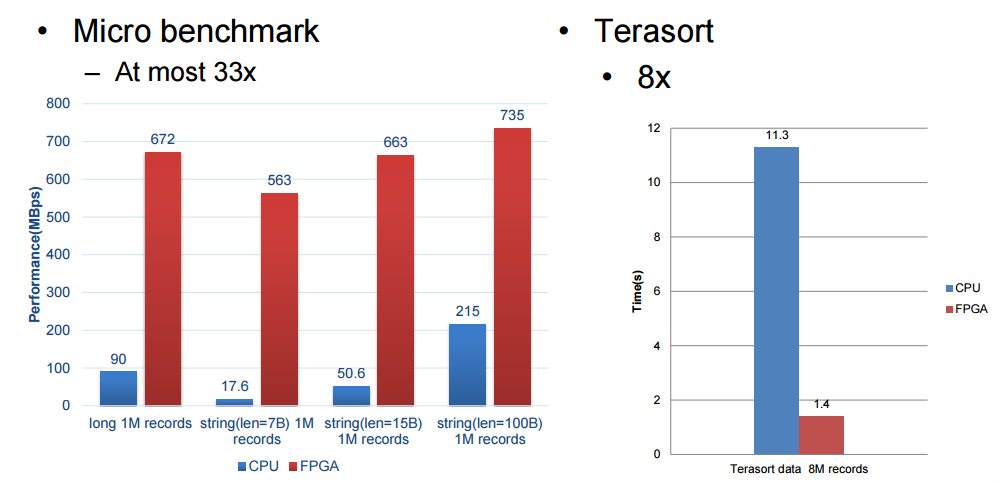
We’re limited in some of the details Baidu was willing to share but these benchmark results are quite impressive, particularly for Terasort. We will follow up with Baidu after Hot Chips to see if we can get more detail about how this is hooked together and how to get around the memory bandwidth bottlenecks.

Why Did Silver Lake Buy A Majority Stake In Intel’s Altera FPGA Business?
Beleaguered chip maker Intel has been looking for ways to capitalize on non-core, not large, but profitable parts of its business to raise funds for its ambitious plans to revitalize Intel Foundry and to also invest heavily in the Intel Products group. And only two weeks after taking the helm …

FPGA Inroads to Convolutional Neural Networks
At The Next FPGA Platform event in January there were several conversations about what roles reconfigurable hardware will play in the future of deep learning. While inference was definitely the target of most of what was discussed, there is ample opportunity across the spectrum for acceleration but that changes with …

The Killer Apps For FPGAs Could Be SmartNICs And Storage
If FPGAs are going to take off in the datacenter in their own right, they are going to need their own killer apps. Plural. At The Next FPGA Platform event that we hosted recently in San Jose, there was plenty of talk about how FPGAs have been embedded in all …
I’m wondering how that will work with a POWER8 or POWER9 CAPI enabled, which are much less limited by bandwidth…
On CPU side, the sql running on single core or distribued on all cores?