

The key to creating more efficient neural network models is rooted in trimming and refining the many parameters in deep learning models without losing accuracy. Much of this work is happening on the software side, but devices like FPGAs that can be tuned for trimmed parameters are offering promising early results for implementation.
A team from UC San Diego has created a reconfigurable clustering approach to deep neural networks that encodes the parameters the network according the accuracy requirements and limitations of the platform—which are often bound by memory access bandwidth. Encoding the trimmed parameters in an FPGA resulted in a 9X reduction in memory footprint and a 15X boost in throughput while maintaining accuracy.
“Neural networks are inherently approximate models and can often be simplified. There is a significant redundancy among neural network parameters, offering alternative models that can deliver the same accuracy with less computation or storage requirement.”
Much of the work on FPGAs for deep learning has focused on the implementation of existing models rather than modifying the models to tailor them for FPGA platforms. This work focuses on some of the key challenges of using FPGAs for deep learning, including the lack of memory on-chip to handle fully connect neural network layers and the high computational complexity (and compute time) that comes with these layers.
The team addresses the memory bandwidth problem by encoding the parameters based on the available memory and the least permissible accuracy while tackling compute time with a factorized version of matrix-vector multiplication (rather than non-factorized, as is standard). This replaces many of the MAC operations with additions, which allows for a more power-in-numbers benefit from the FPGA. This work was condensed into a systematic design flow to optimally schedule the neural network on the hardware, which in this case was a Xilinx Zynq-ZC706 (an eval board for the Zynq-7000 SoC).
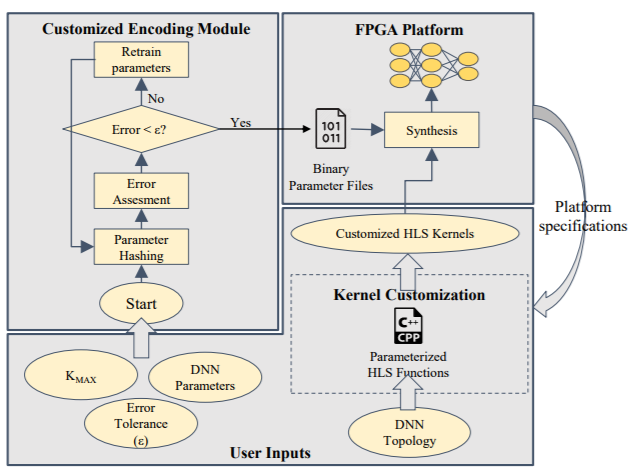
“One observation is that the numerical precision can be customized in accordance with different applications,” the researchers note. “The design process of reconfigurable accelerators with variable numerical precision can be troublesome. Additionally, the use of fixed-point parameters is application-specific and does not provide a generic solution for applications that require higher numerical precision. The answer for this approach is to use assume higher-precision and use a parameter hashing-inspired approach.
“Random hashing requires large dictionaries to ensure DNN accuracy hence the encoded parameters incur high memory overhead, resulting in inefficient FPGA designs in practice. This clustering-based approach retains the desired classification accuracy with significantly smaller dictionaries (K=8) in these experiments, 3-bits per encoded weight) since it explicitly leverages the structure of the parameter space.” The end result is that their approach can scale the memory footprint of those parameters along with the memory constrains.

AI Is A Modest – But Important – Slice Of TSMC’s Business
Given the exorbitant demand for compute and networking for running Ai workloads and the dominance of Taiwan Semiconductor Manufacturing Co in making the compute engine chips and providing the complex packaging for them, you would think that the world’s largest foundry would be making money hands over fist in the …
What Will AMD Do With Programmable Logic And Other Xilinx IP?
AMD has finished its acquisition of Xilinx, which ended up costing close to $49 billion instead of the original $35 billion projected when the deal was announced in October 2020 thanks to the rise of AMD’s shares over the past year and a half. And now, with AMD getting the …

The Killer Apps For FPGAs Could Be SmartNICs And Storage
If FPGAs are going to take off in the datacenter in their own right, they are going to need their own killer apps. Plural. At The Next FPGA Platform event that we hosted recently in San Jose, there was plenty of talk about how FPGAs have been embedded in all …
*On MNIST.
Remember, even logistic regression works okay on MNIST.