
High performance computing in its various guises is not just determined by the kind and amount of computing that is made available at scale to applications. More and more, the choice of network adapters and switches as well as the software stack that links the network to applications plays an increasingly important role. And moreover, networks are comprising a larger and larger portion of the cluster budget, too.
So picking the network that lashes servers to each other and to their shared storage is important. And equally important is having a roadmap for the technology that is going to provide bandwidth headroom, latency shrinks, and scalability improvements. InfiniBand has had an edge over many high performance networks since it emerged in the supercomputing arena a decade and a half ago, and the plan, according to the InfiniBand Trade Association that steers its development, is to keep it that way. But at the same time, the juggernaut of the datacenter network, Ethernet, continues to steal some of the best ideas from InfiniBand and recast them, particularly the Remote Direct Memory Access (RDMA) protocol that gave InfiniBand its original latency edge and made it a favorite of the HPC set in the first place.
“We are driving to do more and better,” Bill Lee, marketing workgroup chair for the IBTA and its software companion, the OpenFabrics Alliance. (Lee also has a day job as director of marketing at Mellanox Technologies, the main commercializer of InfiniBand technology these days alongside Oracle and, in a certain way if you squint your eyes, Intel.) “Today we are shipping EDR, and our architects are working to define HDR, which is our next speed, and in our sights we have NDR and XDR. We see a world where server connectivity is at the 1,000 Gb/sec bandwidth rate sometime in the future.”
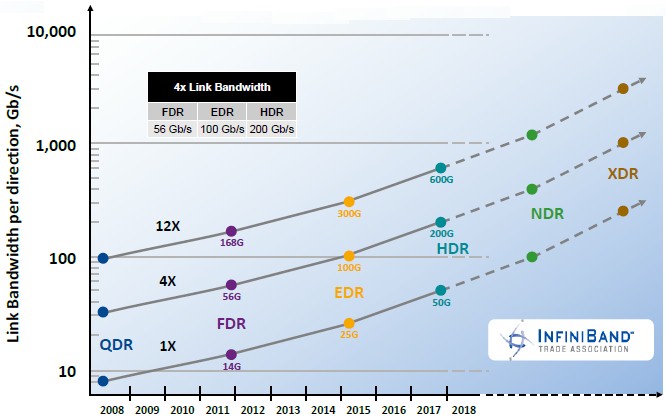
Single Data Rate (SDR) InfiniBand switches debuted in 2001 with 10 Gb/sec of bandwidth per port and port-to-port hop latencies of around 300 nanoseconds. With Enhanced Data Rate (EDR) InfiniBand, which was ramping throughout 2016, the underlying signaling rate for a lane in a port (which has multiple lanes to boost the bandwidth) is 25 Gb/sec, just like it is for the second iteration of 100 Gb/sec Ethernet (you have four lanes at 25 Gb/sec instead of 10 lanes at 10 Gb/sec) and just like it will be for the second generation of Nvidia’s NVLink and IBM’s “Bluelink” OpenCAPI ports on its Power9 chips. The prior generation of Fourteen Data Rate (FDR) InfiniBand from 2011 was a weird 14 Gb/sec, a kind of stopgap speed to bridge the gap better between the 10 Gb/sec used in Quad Data Rate (QDR) InfiniBand from 2008. With the future High Data Rate (HDR) InfiniBand that is expected to make its initial debut from Mellanox later this year in the “Summit” and “Sierra” supercomputers that IBM, Nvidia, and Mellanox are building for the US Department of Energy using the “Quantum” HDR switch ASICs and ConnectX-6 adapters from Mellanox, the signaling rate will double again to 50 Gb/sec per lane, and server connectivity will therefore be 200 Gb/sec across four lanes typically ganged up to make a server port.
“As for NDR and XDR, that is where the dotted lines come in,” says Lee. “The expectation for NDR, short for Next Data Rate, is around a doubling of the signaling, to around 100 Gb/sec to 125 Gb/sec per lane and therefore somewhere between 400 Gb/sec and 500 Gb/sec per server port. And then XDR, or Extended Data Rate, will try to double them again.”
With 125 Gb/sec lanes and four lanes per server, that puts XDR at the mythical 1 Tb/sec of bandwidth per port, something that hyperscalers like Google have been dreaming about for a long time and a bandwidth level that Ethernet was originally expected to reach a year or two after InfiniBand gets there based on the 2015 roadmap but which was removed as a possible speed in the 2016 Ethernet roadmap.
Bandwidth is interesting, of course, but cutting latency is important, too. Latency for InfiniBand has dropped by a factor of only about 3X over the past fifteen years as bandwidth has increased by a factor of 10X and that will be 20X by the end of this year. Forward error correction, which is necessary as signaling rates increase in each port lane, adds to latency and there is no getting around that. While bandwidth is interesting, low latency is also a key driver of InfiniBand adoption in clusters.
“RDMA and CPU offload enabled datacenters to achieve great latency improvements because there was such high levels of network inefficiencies built into their clustered systems,” says Lee. “With the systems now becoming more and more efficient, there is now a tight coupling between the adapter controller across PCI-Express into memory, and really latency was not part of the specification, but it was a benefit that was achieved through the RDMA enablement. What we are seeing coming from FDR to EDR is that the latency improvement was there, but small in terms of percentage and small than what we saw in past InfiniBand steps. What we are looking to do with the standard is to increase the capabilities in the system to improve scalability. You have got near-zero latencies now for point-to-point application performance and now you want to scale that to tens of thousands or hundreds of thousands of nodes and to do that you need to provide capabilities within the fabric. Our members are now shipping appliances for routing and so you can scale these networks much further than you could before routing was available.”
The InfiniBand standard had an address space that peaked at 40,000 nodes, and today there are big clusters installed with 20,000 to 30,000 nodes; with 36-port switches, the practical limit is 11,664 nodes in a three-layer fabric But with this router capability, InfiniBand networks can now connect multiple clusters with tens of thousands of nodes (depending on how many ports are on the switch) and communicate across the clusters and work in parallel on the same applications as if they were all on the same switched fabric. This network extension capability is done for virtual machines on Ethernet networks using the VXLAN protocol developed by VMware or NVGRE developed by Microsoft by essentially making networks look like one big Layer 2 network by tweaking Layer 3 routing functions in the Ethernet switch. What is being done with the most recent InfiniBand Volume 2 Release 1.3.1, which came out in November, is a similar approach to extending the network.
Let’s Get Virtual
If the IBTA wants to see more widespread adoption of InfiniBand in the datacenter, it needs to add one more thing: direct support for virtualization. With the new Virtualization Annex feature added with the Volume 2 Release 1.3.1 specification, virtual machines running on a single physical server will be able to carve up physical InfiniBand adapters on the server into multiple virtual InfiniBand adapters that are paired to virtual machines. It is not clear if Virtualization Annex supports live migration of VMs between physical servers, as VXLAN and NVGRE do, but it needs to.
Perhaps even more importantly, the Virtualization Annex support allows for RDMA to be used on virtual machines. With the current InfiniBand software stack, RDMA does work with virtual machines running on systems linked to each other using InfiniBand, but with limited scalability. On Ethernet running the RDMA over Converged Ethernet (RoCE) protocol, as it turns out, the same limits hold. This virtualization work to improve the scalability of RDA was completed during the summer last year and the specification was released for review at the end of November. It is not clear if this Virtualization Annex functionality will make the cut for HDR at Mellanox. But it would clearly be useful.
“We do see that InfiniBand is finding places in the enterprise and in the cloud as datacenter technologies evolve and as managers realize that HPC is not just for scientists,” says Lee. “People in the enterprise space are noticing that there are emerging environments that are changing the needs for server to storage communication. With hyperconverged environments, there is a lot more management and a lot more data flowing over the network, and so IT managers should consider RDMA for their I/O, whether it is on InfiniBand or Ethernet with RoCE. We are seeing now with hyperconverged and hyperscale that InfiniBand and RoCE can get a foothold in these spaces because the need for I/O speed is greater than with just regular Ethernet.”

Defying Supply Constraints, Nvidia Turns In Its Best Quarter Ever
To one way of thinking about it, this is the best of times among the worst of times for Nvidia. Despite a global pandemic that has caused disruption in IT operations as well as spending among enterprises large and small and that has disrupted supply chains all over the IT …
Arista Networks Conservatively Awaits Its AI Boom
As a founding member of the Ultra Ethernet Consortium, which has the express purpose of making Ethernet as good for AI and HPC clusters as InfiniBand but with the scalability and familiarity of Ethernet, Arista Networks wants to benefit mightily from the AI wave that is coming to enterprise datacenters …
Inside The Massive GPU Buildout At Meta Platforms
If you handle hundreds of trillions of AI model executions per day, and are going to change that by one or two orders of magnitude as GenAI goes mainstream, you are going to need GPUs. Lots of GPUs. And apparently Meta Platforms does, and it is getting out its big, …
Be the first to comment