

The hyperscaler and HPC organizations of the world are not the only places where innovation happens with infrastructure. Telecommunication companies were the hotbed for the early years of computing, given the vastness of their networks and the systems needed to keep them humming and make sure we all get the correct bill and pay it.
Over the years, many of the largest telcos have created adjacent businesses hosting applications on behalf of enterprises, something they could do because they were already building datacenters and they already own networks that span large areas. In this regard, they operate more like clouds and are very hot to trot for open technologies like OpenStack and Open Compute. But in another regard, telcos are still communication firms like in days gone by, but they want to wean themselves off of proprietary appliances they do all sorts of switching, routing, security, and other functions on their networks and move towards the kind of general purpose hardware that has come to dominate the corporate datacenter. So if you squint your eyes, telcos look a bit like baby hyperscalers.
Individually, none of the telcos has the heft of a hyperscaler, but together, they comprise a very large portion of spending on servers, switches, and storage in the IT sector. We don’t have good numbers on this, but the experts we have talked to say that replacing all of those appliances with more open and generic gear could be a much larger opportunity than the enterprise.
For instance, the Ethernet switching market generates close to $17 billion in revenues, but only about a third of that is for enterprise datacenters, with telcos and service providers representing the other two thirds. With servers, this is not quite the case, which stands to reason given the amount of networking these companies do today. By Intel’s estimates, as we reported last September, Intel booked $6.7 billion in Data Center Group revenues in the enterprise, and $3.2 billion for cloud service providers and $1.2 billion for what it calls communications service providers. (HPC represented the other $3.3 billion.) But those Intel’s revenues from those service provider segments are expected to double by 2018 as the conversion of proprietary gear to generic gear sweeps the telcos and clouds as it has the compute portion of the enterprise datacenter (and is now happening to networking and storage to a certain degree.) Enterprise spending with Intel will only increase by about 50 percent over that term. (Which is still not bad.)
The point is, there is a lot of money at stake, and telco companies and service providers generally control their own software stacks, like hyperscalers and HPC shops do, and that means they can make relatively rapid architectural shifts as they see fit. Behind the scenes, many OEMs and ODMs are positioning themselves for a future that will see more competition for Intel’s ubiquitous Xeon server platform, and one such specialist in the telco field, Kontron International, has designed a generic, hyperscale-style system that will accommodate either Xeon or ARM processors and give telcos the ability to play these architectures – and their chip vendors – against each other within the same hardware platform.
One such ambidextrous platform is the Kontron Symcloud system, which is akin to other multinode hyperscaler boxes except this one is aimed specifically at the hardware needs of telcos and service providers. Sven Freudenfeld, head of business development telecom and cloud infrastructure in Kontron’s Communication Business Unit, tells The Next Platform that Symkloud development started more than three years ago, with the idea of putting multiple nodes of various architectures into a carrier-grade chassis. The initial machines were developed for video transcoding work, and that is why Kontron chose Intel’s desktop Core i7, rated at 47 watts a pop, with integrated Iris GPU graphics coprocessors as the main motors for the initial Symkloud MS2900 media servers.
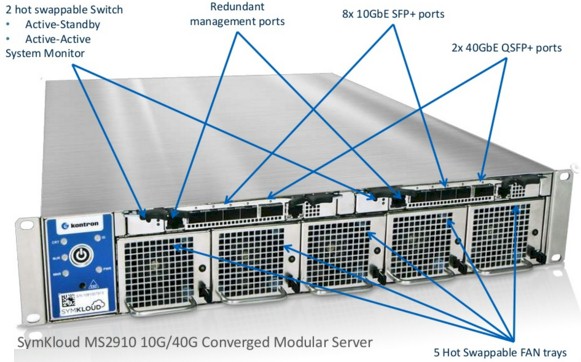
The MS2900 sleds put two of the quad-core Core i7-4860EQ processors, which run at a base 1.8 GHz clock speed with turbo to 3.2 GHz and which have 6 MB of L3 cache. The Symkloud sled can have two of these chips as well as 16 GB or 32 GB of memory per socket, and nine of the sleds fit into the 2U chassis along with redundant power supplies and virtualized network interfaces linking to integrated switches. With this setup, that is 72 cores and, more importantly, 18 GPUs per enclosure, the latter being important for accelerating the encoding work. A rack of these machines has 1,440 cores and 360 GPUs, leaving room for two top of rack switches. For local storage, each sled has two 240 GB M.2 flash stick units. The two hot swap switches have four 10 Gb/sec uplinks and eight 1 Gb/sec uplinks each. Kontron offers a 5 to 7 year lifecycle for the hardware, a longer term than your typical enterprise machine, which lasts maybe 3 or 4 years.
Liberty Global, the massive American-British cable television operator, plus a slew of media transcoding service bureaus, were initial customers for this Symkloud machine. Since that initial launch, Kontron has created a newer version of the Synkloud, which has a wider variety of compute options and which also features internal 10 Gb/sec switching inside the chassis and across enclosures and 40 Gb/sec uplinks to the network.
This machine, the Symkloud MS2910, is also a 2U enclosure with nine sleds, but there are other storage options, including Intel P3600 and P3700 SSDs, and the option of having a single Intel “Ivy Bridge” Xeon E3-1275 v2 processor on the sled instead of a pair of Core i7s. (The idea is that you have half as many cores, but the base clock speed, at 3.5 GHz, is basically twice as high. Better oomph for single-threaded jobs, plus the integrated HD Graphics P4000 GPU for further acceleration.)
The interesting bit in the X86 versus ARM pushing contest is a new sled that Kontron has cooked up that has both Intel’s Xeon D and Applied Micro’s X-Gene 1 processors as options. The new Symkloud boards include support for the four-core D-1527 (2.2 GHz), the eight-core D-1548 (2 GHz), and the 16-core D-1577 (1.3 GHz) and D-1581 (1.9 GHz). (You can see the new Xeon D lineup here. The Xeon D processor has a pair of 10 Gb/sec Ethernet port embedded in it, which greatly simplifies the infrastructure, although not everyone is using that port. (Facebook is not with its “Yosemite” server design, for instance, which is based on the Xeon D, instead has a two-port 50 Gb/sec adapter from Mellanox Technologies with cable splitters to provide 25 Gb/sec out of the four node server chassis in a virtual and shared fashion.) The Xeon D can support up to 128 GB of memory in its four sockets, but using cheap 8 GB sticks that telcos will like it tops out at 32 GB of memory. The top-end Xeon D-1581 has a 65 watt TDP.
Kontron has also created a two-node server sled for the Symkloud that has a pair of eight-core X-Gene 1 processors, which clock at 2.4 GHz, from Applied Micro. Each X-Gene 1 has a pair of 10 Gb/sec adapters on the die and support for 64 GB of memory across its two memory slots, and comes in at 47 watts.
So how do these two chips stack up on network function virtualization workloads when you pit a pair of X-Gene 1s, with a total of 16 cores per sled and four Ethernet ports, against a single Xeon D, with 16 cores and two Ethernet ports? Based on what Kontron has seen in early adopter customers, the two sleds are “similar in performance,” according to Freudenfeld, with the biggest differences higher network connectivity across the same number of cores and lower cost. With the top-speed Xeon D processors plus memory and storage, the sleds cost maybe $4,500 to $6,000 a pop, while with the X-Gene 1 sled costs maybe $4,000 to $5,000 each, according to Freudenfeld. That’s an 11 percent to 17 percent savings on raw hardware, roughly.
(Of course, we realize that it would be possible to put two Xeon D chips with 2 GHz clock speeds and on a sled and draw parity in terms of networking, dropping it down to 45 watts per chip and bringing the networking and cores to parity. Perhaps the performance – we can’t say.)
The important thing for telcos is that the Linux ecosystem is evolving for X-Gene and other ARM processors, and in the case of X-Gene 1, the same OpenStack cloud controller that runs on the Xeons can run on the X-Gene nodes. The Intel Data Plane Development Kit (DPDK) can do deep packet inspection for networks, and the combination of the Enea Linux stack and the ixEngine from Qosmos can do deep packet inspection on the ARM chips. Benchmark stats were not revealed for these workloads, but the implication is that they are equivalent. As usual, our advice is to do your own tests and keep an eye on public benchmarks as they become available. The data is still particularly thin out there on ARM servers at the moment.
Looking ahead, Freudenfeld saus that Kontron is skipping the X-Gene 2 generation, which offered some tweaks to the eight-core design plus the addition of RDMA over Converged Ethernet (RoCE) on the Ethernet ports, and jumping straight to the X-Gene 3 that will start sampling later this year and perhaps be shipping early next year. At that time, Applied Micro will reach core parity with the Xeon Ds, and more direct comparisons can be made – and will be made – by the telcos and service providers.


Will Open Compute Backing Drive SIOV Adoption?
Virtualization has been an engine of efficiency in the IT industry over the past two decades, decoupling workloads from the underlying hardware and thus allowing multiple workloads to be consolidated into a single physical system as well as moved around relatively easily with live migration of virtual machines. It is …

Argonne Aurora A21: All’s Well That Ends Better
When it comes to a lot of high performance computing systems we have seen over the decades, we are fond of saying that the hardware is the easy part. This is not universally true, and it certainly has not been true for the “Aurora” supercomputer at Argonne National Laboratory, the …

Intel Braces For DPU Hit, Awaits Jevon’s Paradox Bounce
We said this a long time ago, and we are going to say it again now. One big reason that Intel paid $16.7 billion to buy FPGA maker Altera was that it was hedging on the future of compute in the datacenter and that it could see how the hyperscalers …
“The Xeon D processor has a pair of 10 Gb/sec Ethernet port embedded in it, which greatly simplifies the infrastructure, although not everyone is using that port. (Facebook is not with its “Yosemite” server design…” – Of course Facebook is using the embedded 10Gbe ports on the Xeon D. They would be stupid not to. There is 10GBase-KR link from each node to the mezzanine card. There are three ways how the internal connectivity of Yosemite is arranged as described in its specs:
http://files.opencompute.org/oc/public.php?service=files&t=7f5d8ba3c80744bc78a92d3cad46b7d2&download