

When it comes to a lot of high performance computing systems we have seen over the decades, we are fond of saying that the hardware is the easy part. This is not universally true, and it certainly has not been true for the “Aurora” supercomputer at Argonne National Laboratory, the second exascale-class system in the United States that has actually been installed.
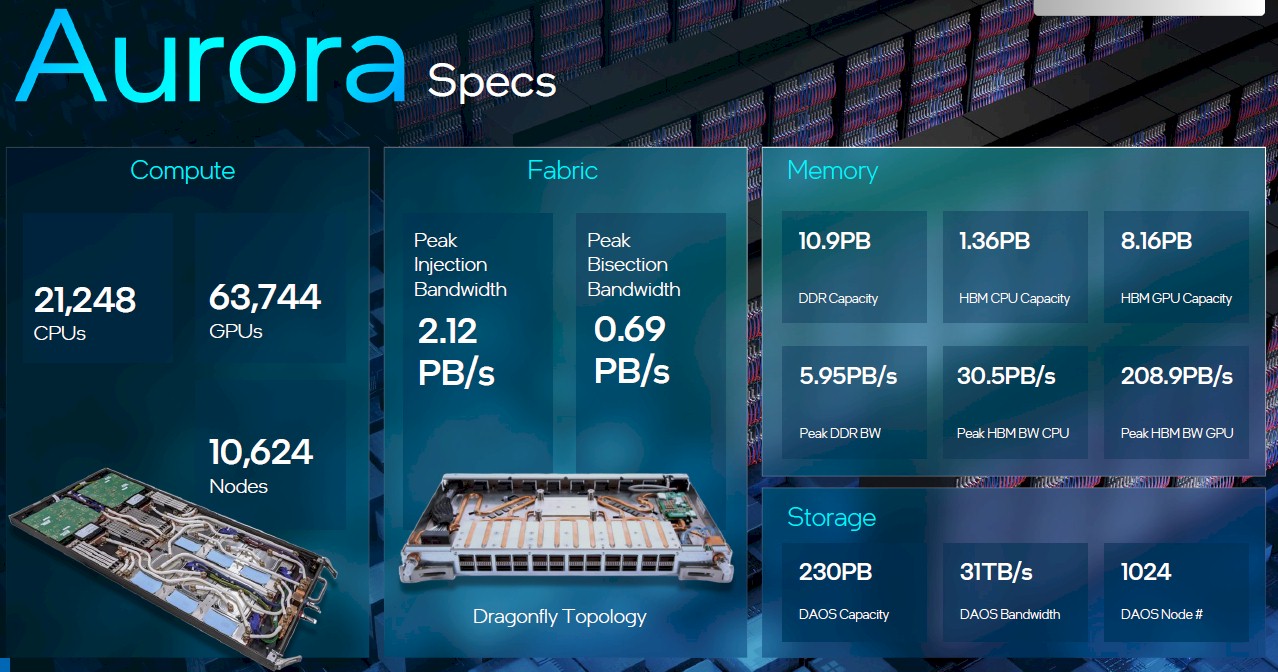
Last Thursday, after heaven only knows how many days of work unpacking the blade servers comprised of a pair of “Sapphire Rapids” Max Series CPUs with HBM2e main memory and six “Ponte Vecchio” Max Series GPU compute engines, all 10,624 of the blades that are going into the 2 exaflops Aurora A21 system were finally and fully installed. That has been an even heavier job than it sounds. (Our backs hurt just thinking about putting 10,624 blades into the racks, which weigh over 70 pounds each. . . . And that is a mountain of cardboard to crush and recycle, too.)

The Aurora saga that began even before Argonne announced the plan for the original 180 petaflops pre-exascale machine, which we have dubbed Aurora A18, in April 2015 based on Intel “Knights Hill” many-core processors and InfiniBand-ish Omni-Path 200 interconnects, scaling across a massive 50,000+ compute nodes. There were a lot of issues, particularly with Intel’s 10 nanometer processes used to make the compute engines but also with managing that level of concurrency across so many nodes and with trying to support emerging AI workloads on such a machine. And thus the original A18 machine architecture was killed off in March 2018 and the Knights Hill processor was killed off in July 2018. And instead of getting a pre-exascale machine in 2018, Argonne was promised a machine with in excess of 1 exaflops of sustained double precision floating point compute in 2021, which was dubbed Aurora A21, and it was not at all clear that it would be a hybrid CPU-GPU architecture given that Intel had not yet announced its intent to enter the datacenter GPU compute arena to take on Nvidia and AMD. That plan was revealed in March 2019, with Intel as prime contractor and Cray as the system builder.
The Aurora A21 machine, which is being installed here in 2023 after delays with the Ponte Vecchio GPUs and Sapphire Rapids CPUs, is a much better machine than Argonne was originally going to get and about as good as it could have expected for this year given the state of CPUs and GPUs here in 2023 as well. It has perhaps taken many more nodes to break that 2 exaflops peak performance barrier than either Intel or Argonne expected – we revealed last month that the Ponte Vecchio GPUs are geared down to 31.5 teraflops peak FP64 performance, significantly lower than the professed 52 teraflops peak performance of the device – but the resulting Aurora machine is a compute and bandwidth beast just the same. And it looks like Argonne got quite a deal on it, too – as was completely fair given all of the delays. Had it been possible to run the Ponte Vecchio GPUs at full speed, Aurora A21 would be rated at more than 3.3 exaflops peak, which would have made it the undisputed champion in the supercomputing arena for probably a few years.

As it stands, it looks like “El Capitan” at Lawrence Livermore will come in at in excess of 2 exaflops peak as well, based on AMD’s hybrid CPU-GPU devices, called the Instinct MI300A. How far in excess of 2 exaflops is unclear, but El Capitan only has to beat 2.007 exaflops to beat Aurora A21. With Lawrence Livermore in recent years playing second fiddle in the supercomputer performance to whatever machine that Oak Ridge National Laboratory has installed at roughly the same time, you an bet that Lawrence Livermore is angling to beat out Argonne on the November 2023 Top500 supercomputer rankings. We think it could be by 10 percent or more if the economics work out.
The researchers and scientists at Argonne just want to get some science done, we imagine, and are looking forward to just having a big beast to run their applications upon.
All of those compute nodes are stored in 166 of the “Shasta” Cray XE cabinets from Hewlett Packard Enterprise, which bought Cray in May 2019 for $1.3 billion, each with 64 compute blades per cabinet and comprising a total of eight rows of cabinets spread over an area the size of two basketball courts. In addition to these compute nodes, Aurora A21 includes 1,024 storage node that run Intel’s Distributed Asynchronous Object Storage, or DAOS, which has 220 TB of capacity and 31 TB/sec of bandwidth across the Slingshot interconnect in its own right. The compute nodes are also interlinked by Slingshot, and HPE/Cray is architecting a shared compute and storage network in the pre-exascale and exascale-class machines it is building in the United States and Europe. In the past, there was a network for the compute and another one for the storage.
We are excited to see how Aurora A21 performs, and there is no reason that it cannot stand toe-to-toe in terms of real-world performance with El Capitan or Frontier. And if it does, then there is hope for Intel’s revised HPC and GPU aspirations, which seem to be a bit more practical these days than they were a few years ago.
Intel has killed off the next-generation “Rialto Bridge” GPU and has also pushed out its own hybrid CPU-GPU devices until past 2025, and is also killing off its “Gaudi” family of matrix math engines in favor of creating a re-envisioned “Falcon Shores” discrete GPU that makes use of the integrated Ethernet interconnect and the matrix math units of the Gaudi line. It remains to be seen if this is all being done to get the next system deal at Argonne, which has to be pretty miffed at Intel given all of the changes and delays. Five years and three different architectures is a jagged little pill to swallow.
Argonne and Lawrence Livermore were both early an enthusiastic supporters of IBM’s BlueGene line of massively parallel machines, and Argonne was very supportive of the Knights compute engines and Omni-Path interconnects that Intel built as a kind of off-the-shelf replacement to BlueGene machinery. But now Argonne has been burned three times – once by IBM and twice by Intel – and it may not want to be the risk lamb that the US Department of Energy wants to have so it can keep two or three different architectural options in the pipeline at any given time. The DOE has not tapped Nvidia to provide compute engines for any of its current exascale computing systems, but that is always an option for future machines that will probably weigh in at between 5 exaflops and 10 exaflops in the 2028 to 2030 timeframe.
That seems like a long time away, but given how tough it is to wring performance and cost out of these massive machines, it really is not that far away. Argonne is no doubt thinking about its options, and Intel is no doubt trying to make the case that whatever follows the Falcon Shores GPU – perhaps an integrated CPU-GPU device like Lawrence Livermore’s El Capitan is getting from AMD – will fill the role and foot the bill.
The one thing we know for sure is that it is, in fact, Argonne’s job to push the envelope, even if it gets cut by it sometimes. That is what supercomputing centers do, and always did do. It’s in the job description.
Then again, Argonne may take a hard left turn and be the first US national lab to say to hell with it and move all of its applications to Microsoft Azure’s North Central US region outside of Chicago on hybrid CPU-GPU machines interconnected by InfiniBand or gussied up Ethernet.
Stranger things have clearly happened for Argonne, you have to admit.


Intel Let The Chips Fall Where They Might
This day always comes. It is the nature of monopoly and hubris. It came for IBM. It came for Microsoft, and it is coming for Facebook. It will come for Google and, even though it is hard to believe, it will come for Amazon. And it is most assuredly coming …
Why Did Silver Lake Buy A Majority Stake In Intel’s Altera FPGA Business?
Beleaguered chip maker Intel has been looking for ways to capitalize on non-core, not large, but profitable parts of its business to raise funds for its ambitious plans to revitalize Intel Foundry and to also invest heavily in the Intel Products group. And only two weeks after taking the helm …
Intel Aims For Zettaflops By 2027, Pushes Aurora Above 2 Exaflops
Just because Intel is no longer interested in being a prime contractor on the largest supercomputing deals in the United States and Europe — China and Japan are drawing their own roadmaps and building their own architectures — does not mean that Intel does not have aspirations in HPC and …
I wonder if various researchers doing AI research who would in the past apply for time at the DOE supercomputers have already begun to instead apply for funding to rent cloud processing time for their research. If one wants to do large-scale AI research surely the DOE machines are slower and more effort to use.
Can only speak to AWS. You have to build up credibility there and get them to increase your quota, you cannot simply make an account and fire up 1000 GPUs. If you want to stand up accelerated spot instances on AWS you can get enough quota for a set of four 8 GPU A10G machines without too much problem, but beyond that the gotchas start. Getting quota for on demand GPU/AI training instances is an extremely bureaucratic and BS laden process.
Also, take a look at the hourly cost of, say, an on demand 8 GPU A100 instance… AWS is not actually cheap. You can buy GPU servers outright and they’ll pay for themselves in a year or two compared to similar capacity AWS.
I should add, there are niche players that are not as hidebound as AWS but most are not quite up to the level of useful either. Example, one company was offering GTX1080ti, RTX A6000 and also A100 and was going to roll out Ada GPUs as well, perfect for some samisdat AI training and experimentation. But until very recently the company did not offer attachable/composable storage. You got to pay GPU prices while uploading your training data and when the run was complete and you shut down the VM your data would go away.
WoW! That’s as near to a kiloton of gooey-gooey good HPC news as it gets — to be celebrated (I think) with Chicagoland Gangster-style Gnarly Knots triple-cheese soft pretzels … Great job!
At 5x the square-footage of ENIAC, 20x the mass, 100x the cost, 400x the power consumption, and 5,000,000,000,000,000x the performance (all approx.) … inquiring minds urgently need to know: does it run “Hello World!”?
(A: at this perf. level, the output comes out before the code is even submitted …). d^8
When you type Hello World, it actually generates a new one from a black hole’s energy….
Great catch! “!dlroW olleH” :lasrever-emit noziroh-tneve htiW (neglecting stochastic re-ordering by quantum turtles … !) b^8
The next interesting competition it is about EL CAPITAN from AMD (the class struggle company) and AURORA from INTEL (the subsidize company), wonderful battle !!
Could anyone elaborate on the statement “But now Argonne has been burned three times – once by IBM and twice by Intel – and it may not want to be the risk lamb.” In what way burned? Did all system installations have delays? Were any unfit for purpose?
I guess I’m unfamiliar with the history. Any explanation with details would be appreciated.
Argonne counted on BlueGene having successors, and a shortsighted IBM manager killed it off. So no roadmap. Then it invested in the Knights systems and Omni-Path systems from Intel. Which were scrubbed. And then it had to adopt a whole new architecture from Intel, which was years later than planned and that has what looks like a different future. Falcon Shores will be very different from Ponte Vecchio, it looks like. Systems have delays, to be sure. But this has been difficult on Argonne, which is just trying to get science done.
They should have ditched Intel and gone with AMD after the third year of no chips. Didn’t they build an Epyc based test bed cluster at one point just because with Intel they had exactly no CPUs and a handful of frighteningly expensive & barely manufacturable FrankenGPUs ?
This is a bit rich, it’s a lot like the pentagon talking about how great it’s new fighter/carrier/tank is now that it is finally delivered years late and 300% over budget.
Intel should be sued and some managers at Argonne should be fired.
It’s a little different if, as we suspect, Intel wrote off $300 million of the $500 million price tag on the A21 contract and Argonne got a 2 exaflops machine for $200 million. That’s four years late, approximately 2X the performance of the second or third iteration of the contract, at 60 percent off the cost.
El Capitan is now expected to be accepted in mid 2024. So is AMD two years late?
https://insidehpc.com/2019/08/cray-to-build-el-capitan-exascale-supercomputer-at-llnl/
“To be hosted at LLNL, El Capitan will have a peak performance of more than 1.5 exaflops and an anticipated delivery in late 2022”
It is running a year behind just like Frontier was as well at Oak Ridge. We are many years later with any exascale machines–excepting China, which apparently had two in the field in early 2022.
The other half of that story is the software. Intel’s oneAPI bundle, libraries and performance analysis tools are pretty impressive. Has anyone else ever delivered that amount of software for one of these contracts?
Well, nVidia had it ready at the beginning, didn’t it?
Uncle Sam had to pay AMD and Intel for the code.
nVidia has software that can run on their GPUs. What Intel provided is a heterogeneous programming solution, including dpc++, fortran, python, SYCL, their performance analysis tools, openMP, MPI, CUDA conversion tools, their whole oneAPI group of tools … oneDNN, oneTBB, oneVPL, oneDAL, oneMKL … converted to run on CPUs and/or GPUs.
Much of this is open source, and that includes examples to port to other accelerators.
So you say Intel DID NOT screw DOE around? U need to re-read the piece & comments.
I wonder why they took a $300m hit in the $500m deal?
I don’t recall saying that. I have written the pieces over the years chronicling the pain. What I am saying is that it is built, it has a lot of performance, and Intel adjusted the price down such that A21 provides the best price/performance in the world.