
One of the big issues with any complex piece of distributed software is getting the most performance out of the scale inherent in the system. Scaling things out is always the first order of business, and then after seeing how workloads run on top of whatever framework we are talking about, programmers can go back into the guts of the code and figure out how to make it all perform better.
This is ever the way, and it is the point at which Nutanix has reached with its Xtreme Computing Platform hyperconverged storage, which mashes up a virtual SAN environment and virtual compute on a single cluster of X86 iron.
Most people seem to intuitively understand that for certain classes of workloads, hyperconverged storage is the best way to deliver flexibility and capability through generic servers, as opposed to distinct compute and storage appliances as we have done in the past. At the moment, hyperconverged solutions have been widely adopted by midrange enterprises with a smattering of adoption among large enterprises for greenfield applications like Microsoft Exchange email servers or virtual desktop infrastructure. But we think that the slower adoption by large enterprises is more a function of the conservative nature of these organizations. While large enterprises are out there testing many new technologies very early in any cycle, they let those technologies mature a bit before going gangbusters with them. Enterprises have been watching the rise of Nutanix and its peers SimpliVity, Maxta, HPE, EMC (with ScaleIO), Pivot3 (which just bought distributed storage upstart NexGen, whom we profiled last July when it popped out of stealth mode), Scale Computing, and a few smaller players. But what we are hearing is that large enterprises have been concerned about the performance that these hyperconverged solutions offer as much as the limited scale many of them – but certainly not all of them – exhibit.
In past conversations, Nutanix has been adamant that the distributed file system at the heart of the Xtreme Computing Platform has no upper limit, but we know that this cannot, in fact be true. But the scale can be very, very large – many thousands of nodes, apparently.
The secret to this scale is to distribute the control of that file system as well as the data across the cluster in an even fashion. To be specific, the Nutanix Distributed File System takes the Cassandra NoSQL datastore that Facebook created to span some of its largest workloads and uses it to spread file system metadata across the nodes in the Nutanix cluster. The Paxos algorithm that was adopted and to a certain extent made viable by Google for its own distributed storage and compute platforms was parallelized by Nutanix and run atop Cassandra to provide the foundational layer of all of the storage services. Nutanix then grabbed Zookeeper from the Hadoop stack to keep track of the state of the cluster, with a few megabytes of overhead per node (and importantly constant per node to keep that overhead balanced across the cluster). The MapReduce framework is used to spray data across the cluster and is also used to handle data deduplication and compression tasks in a parallel fashion across that cluster as well.
Suda Srinivasan, director of product marketing at Nutanix, tells The Next Platform that the file system is capable of holding billions of files, and that you can partition Nutanix Distributed File System to create multiple file stores on a single cluster.
According to its S1 filing with the US Securities and Exchange Commission for its initial public offering, which could happen this year, the company has over 2,100 customers worldwide as of January, and it is probably approaching 2,500 customers if its run rate has stayed the same. Based on past statements from the company and our projections, we believe it may have as many as 35,000 nodes in the field. The average is low, but as Howard Ting, senior vice president of marketing at Nutanix, told The Next Platform back in November, that the large enterprises that Nutanix is selling to have hundreds of nodes, with some having over 1,000 nodes and the largest having over 1,500 nodes. It is important to make a distinction here: just like with EMC’s ScaleIO distributed block storage, the scale of the underlying Nutanix Distributed File System is quite large, but both platforms are limited on the compute side by the scalability limits of the hypervisor that companies choose to deploy. One of the reasons why Nutanix launched its own embedded and tuned version of the KVM hypervisor, called Acropolis, was to be able to scale that hypervisor further than the 32 node upper limit of VMware’s ESXi 5 hypervisor and the 64 node limit of ESXi 6. (The other reason was to cut off revenue to its hyperconverged storage rival and yet another was to have a complete stack of its own. If KVM had been more mature back in 2009, Nutanix might have started there, but ESXi was by far the safer bet.)
We happen to think companies want a high scale ceiling, and once they know they have that, the next thing they start worrying about after cost is the raw performance of any distributed computing or storage framework. And with the Xtreme Computing Platform 4.6 release announced today (meant to coincide with the launch of the VxRAIL hyperconverged appliances from EMC and VMware today), Nutanix is focusing on performance improvements. The trajectory for performance just took a hockey stick upwards, as you can see:
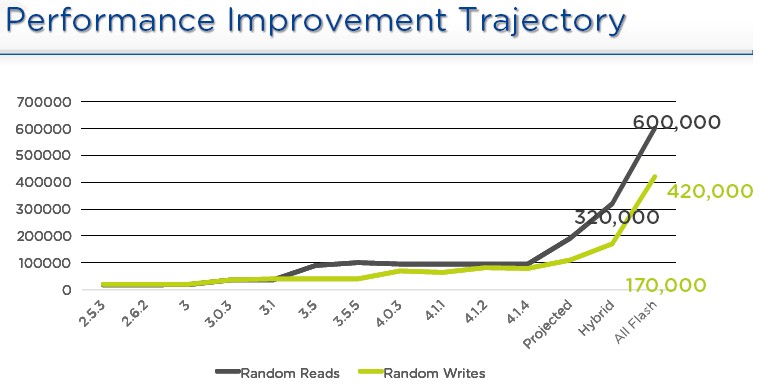 As we have said before, we would love to see benchmarks pitting real SANs against the virtual ones embodied in hyperconverged storage, and more importantly, we would love to see the performance results that real customers get on their workloads. (This will come in time, we hope.)
As we have said before, we would love to see benchmarks pitting real SANs against the virtual ones embodied in hyperconverged storage, and more importantly, we would love to see the performance results that real customers get on their workloads. (This will come in time, we hope.)
The update of the Nutanix stack with the 4.6 release includes 25 different performance enhancements, according to Srinivasan. In some cases, this comes down to tuning the software better for both disk and flash. Generally speaking, the performance improvements include reducing locking overhead, dynamic memory allocation, and context switching overhead in the file system as well as making use of the latest C++ 11 features to boost performance. The performance updates also include improved metadata caching and better data write caching algorithms, as well as faster I/O categorization and finer grained checksums on data. Add it all up, and two of the four-node, all-flash NX-9000 appliances can do 1 million I/O operations per second on a mix of random reads and writes of 8 KB file sizes using the updated software, about 3X the performance compared to the prior generation of Nutanix software. And for hybrid disk/flash configurations using the NX-7000 series appliances the performance improvements are on the order of 2X, says Srinivasan. On some workloads, the performance boost is as high as 4X, and the cost per IOPS can drop as low as 35 cents which Nutanix says is on the same order of bang for the buck that all-flash arrays deliver.
We asked about a specific workload performance improvement, rather than simple reads and writes to the file system, and Srinivasan said that on one relational database test running transactions, the latency was taken down by 50 percent. On another test that Nutanix has done, it was able to cram up to 30,000 Microsoft Exchange mailboxes into 8U of rack space with its appliances. (We are trying to get details on these benchmarks, but vendors often talk only at a very high level.)
The interesting bit is that these performance improvements are available to customers who have already acquired Nutanix appliances. It just takes a software upgrade to do it, and the 4.6 update will be ready before the first quarter ends.
In addition to the performance updates, the Nutanix software stack is getting a few more goodies. As it turns out, the Nutanix Distributed File System acts like a boot drive for virtual machines running on the cluster, but for applications that require their own file system space, such as virtual desktop infrastructure, companies often had to buy external filers from NetApp, EMC, Hewlett Packard Enterprise, or Dell to perform this function. (Think of NDFS as the C: drive and the NetApp filer as a D: drive for each user.) This is obviously not something that Nutanix wants, so it grabbed the open source Zettabyte File System created by Sun Microsystems way back when, modified it, and embedded it into the stack as a distributed file service that runs alongside NDFS. This is called Acropolis File Services, and it will come as a free feature in the upgrade for customers who have the Ultimate Software Edition. (The Starter and Pro Editions do not include this files services layer.)
Now that it has block and file services, we asked Srinivasan if Nutanix was working on object services for the stack, and while not committing to the idea, he said it was the next logical move.
The updated Xtreme Computing Platform stack will also have one-click, automated conversion from ESXi hypervisors and their virtual machine formats to the Acropolis KVM variant and its formats when it ships before the end of March. In the next release, Nutanix will offer bi-directional conversion, allowing customers to move from Acropolis back to ESXi if they want, and if enough customers ask for conversion to and from Hyper-V, then Nutanix will entertain that as well, says Srinivasan. By removing this friction of VM conversion, Nutanix should be able to accelerate conversions to its own stack and get VMware software off its clusters, and it should also be able to help companies that have virtualized on ESXi make the jump from their servers to Nutanix appliances with greater speed.
The race is on to see who can convert those VMware customers to hyperconverged storage, and VMware has built momentum and now has a slightly larger customer base than Nutanix. But they are essentially neck and neck and not even around the first turn in this race. There are 50 million ESXi virtual machines that are the prize.


The Fundamental Disconnect Between Software Pricing And Moore’s Law
There are two major opposing forces in the datacenter that create tension in IT budgets. The first is that Moore’s Law makes the cost of compute, networking, and storage go down at an exponential rate, which leads to all kinds of new applications. The second is that software costs scale …

Modern Networks For An Increasingly Distributed IT World
The shift by enterprise IT vendors from hardware box makers to software and services vendors has been ongoing for several years as OEMs have looked to adapt to the rapid changes in a tech world that is becoming application- and data-centric. Companies like Dell Technologies, Hewlett Packard Enterprise, IBM and …

Bringing AWS-Style DPU Offload To The VMware Base
Databases and datastores are by far the stickiest things in the datacenter. Companies make purchasing decisions that end up lasting for one, two, and sometimes many more decades because it is hard to move off a database or datastore once it is loaded up and feeling dozens to hundreds of …
Be the first to comment