

If disk drives were not so inexpensive and capacious, companies would have stopped using them for persistent storage as soon as flash drives became reliable enough for an enterprise duty cycle. It will be a few years before flash arrays generate as much revenue as disk arrays in the datacenter, and it is arguable – and people are arguing about it, in fact – as to when disk capacity sold each year will drop below flash capacity. For the foreseeable future, hybrid arrays will continue to be used, and all-flash arrays will be deployed where specific workloads have particularly aggressive response time needs.
The first generations of hybrid arrays were little more than disk arrays with either PCI-Express flash cards or flash-based SSDs put in them to cache the hottest reads and most recent writes into the system. A slew of upstarts delivered all-flash arrays that were designed from the ground up for the high bandwidth and low latency enabled by flash storage, and the incumbent disk array makers have reacted either through their own engineering efforts or through acquisitions to build up their own portfolio of all-flash storage. The irony of all of this is that for most enterprises, persistent storage in the datacenter is hybrid even if the devices that provide that storage is not. Rather than create a giant hybrid array for all data that spans all workloads, companies seem to be buying some flash to speed up their disk arrays, giving good value for the dollar for storing large chunks of their data, while at the same time rolling in all-flash arrays to accelerate databases, virtual desktop infrastructure, and selected compute jobs.
Hitachi Data Systems, the storage arm of the Japanese IT supplier, has ridden these trends and is now rolling out its first purpose-built all-flash array, code-named “Cheetah,” that offers the density and pricing that will allow Hitachi to better compete with Pure Storage, Kaminiario, SolidFire (now owned by NetApp) and EMC and IBM, which have acquired their respective XtremIO and FlashSystem lines.
Like the Xyratex disk array maker that was spun out of IBM’s Havant, England disk operations a long time ago and is now part of Seagate, Hitachi is going after density, performance, and low-cost as a means of boosting its presence in the all-flash array market. The Xyratex disk arrays were resold by a whole bunch of big IT suppliers, notably NetApp and IBM, and were not only popular for cheap and fast storage among enterprises but also as storage nodes in HPC clusters running parallel file systems. We don’t think that HPC shops will adopt the new Cheetah arrays from Hitachi as flash-based nodes for running parallel file systems like Lustre, GPFS, or Gluster, but it could happen. Hitachi absolutely expects for the new HFS A Series, as the Cheetah arrays are called in its storage lineup, to see some use among HPC shops that need zippier storage to feed their applications. Not all HPC workloads have parallel file systems, particularly those with an analytics bent. It would be interesting to see a flavor of the all-flash arrays eventually running NFS and how that might be used, but thus far, the Cheetah arrays are just coming out as a block device.
Like most storage arrays, the Hitachi Flash Storage A Series Cheetah devices use Intel processors for their controller brains, and like other arrays, they have plenty of oomph to run the data reduction software that makes it possible to radically increase the amount of information crammed onto the flash storage and therefore bring down the price of the storage to a level that enterprises can afford for primary storage for selected workloads. In this case, explains Bob Madaio, senior director of product marketing at Hitachi Data Systems, through the combination of inline deduplication, data compression, and thin provisioning techniques, the Cheetah all-flash arrays are able to attain something on the order of a 5:1 data reduction ratio, and that brings the cost per effective gigabyte of a fully configured array down to somewhere around $1.50. This is about the same level that Hewlett Packard Enterprise established last year with the all-flash versions of its 3PAR arrays, and considerably less expensive than some of the other upstarts in the all-flash arena. This data reduction software comes at a cost, and unlike many other software stacks, the one that Hitachi has created for the Cheetahs allows for the feature to be turned on and off, depending on the need, freeing up compute and cutting down latency when and if this is needed.
The Cheetah array has redundant controllers that are based on twelve-core “Ivy Bridge” Xeon E5 v2 processors from Intel. Depending on the model, the controllers have 128 GB or 256 GB of main memory that is used to cache data as it is flying into and out of the array. The controllers work in an active-active fashion, which means that in the event that one controller has a hardware or software failure, the other one can instantly take over without any downtime. By the way, this is slightly more compute and memory than the prior generation of VSP F Series all-flash arrays from Hitachi, which are a modified version of its existing VSP G Series hybrid arrays. The VSP G and F Series machines do not have in-line block de-duplication, but Madaio says that it will be added to these older products. (Old being a relative term, given that the VSP F Series is only two months old.)
The VSP F Series arrays were interesting in that Hitachi added data compression to the machine not by adding it in the software stack that runs on the controllers, but by soldering ARM-based processors onto the flash drives themselves and doing the necessary processing at the drive. This approach has its benefits in terms of overall performance, particularly with low latency, and that is why Hitachi intends to keep selling the VSP F Series arrays. But adding processing to the flash drives also pushed up the overall cost of the unit, and having only one supplier for the drives meant it had no competition. That said, the second generation Flash Module Drive with Data Compression, or FMD DC2 in the Hitachi lingo, had capacities up to 6.4 TB in size and offered five times more write IOPS and three times more read IOPS than the plain SSD did. So if you want a lot of flash, you will have to weigh the VSP F against the HFS A.
With the HFS A Series arrays, the data reduction software is moved onto the controller, and that means Hitachi can source its SAS flash drives from a number of third parties and bring the cost of the storage down. (It is a lot cheaper to buy a few extra Xeon cores on the controllers than it is to put an ARM chip on each flash drive, apparently.) At the moment, Hitachi is sourcing its flash drives from Samsung, but any 2.5-inch SAS flash drive can in theory plug into the box, allowing Hitachi to get some competitive pricing on the flash.
The Cheetah arrays are a bit different from other all-flash arrays in that they are using all of the depth in a compute rack to cram as much processing and storage as possible into a 2U form factor. Many all-flash arrays front-mount two dozen drives into the enclosure and then put the dual controllers behind the drives in a shallow chassis. Hitachi has mounted the drives sideways in a much deeper enclosure and is able to get a maximum of 60 drives into a 2U chassis. Like this:

The drives mount on both the left and right side of the chassis, 30 each side. The initial drives uses in the Cheetah arrays are 1.6 TB units from Samsung using multi-level cell (MLC) flash memory, and with 60 drives in the enclosure, that yields a raw capacity of a fully loaded unit of 96 TB. Assuming a 20 percent overhead for RAID 5 data protection across the flash drives and then the data reduction techniques that yield an average of 5:1 effective capacity, the fully loaded Cheetah A270 model can hold around 384 TB of data. Provided that data is amenable to such techniques, of course. The usable capacity tops out at 76 TB with RAID on if the data cannot be compressed and there is no duplication.
At the moment, the Cheetah controllers cannot be clustered to create a much larger flash array on the petabytes scale, but there is technically no reason why this could not be done, and as we pointed out above, there is also no reason why a clustered file system could not be layered over top of a bunch of Cheetahs, either. After all, this is just a clever pair of Xeon server with a whole bunch of SAS drives that happen to be based on flash hanging off of them.
In addition to in-line deduplication and data compression as well as thin provisioning (which basically means lying to an operating system and telling it that it has all of the storage allocated to it that it wants while actually only giving it what it needs), the Cheetah software stack includes snapshotting and remote replication software to protect data sets as well as quality of service features that can allocate storage and bandwidth inside of the array to meet performance and capacity targets for particular data sets. Sometime this year, Hitachi will add controller-based data encryption, but this was not ready at launch time. Neither was integration with VMware’s vCenter virtualization controller or the Cinder block storage component of the OpenStack cloud controller, but these are in the works, too. So is a set of REST APIs that will make access to the management features of the Hitachi software stack accessible programmatically, and ditto for a command line interface that some storage administrators still prefer over the graphical interface that is currently shipping.
Here are the model breakdowns in the Cheetah product family:
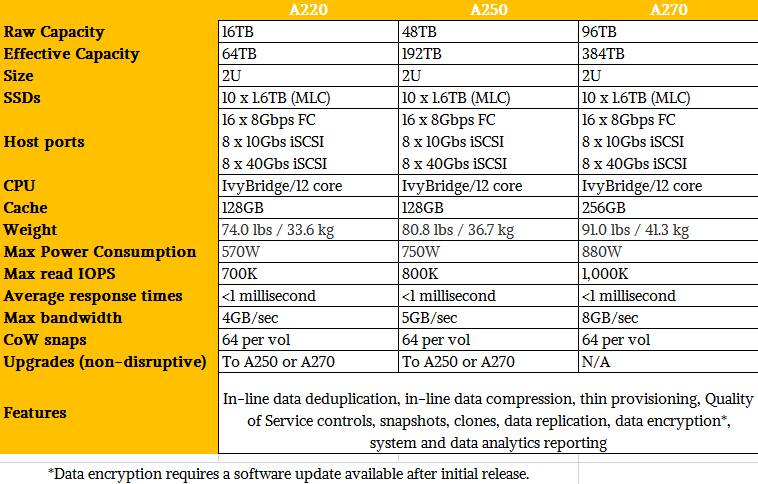
The HFS A220 is the base machine with two controllers with 64 GB of memory for cache on each node and ten SSDs for holding data for an effective capacity of around 64 TB. This base machine costs $125,000, or around $1.91 per GB at list price. Customers can buy blocks of capacity from Hitachi in 20 drive or 50 drive chunks for the HFS A220 to fill it out, with the 50 drive upgrade adding another 64 GB of memory per node to balance out the cache against the persistent storage. The HFS A250 array comes with 30 SSDs and can be upgraded with 30 drives and the memory block. The HFS A270 comes fully loaded, and has to cost around $590,000 to hit the $1.50 per effective GB price point Hitachi is shooting for. Those Hitachi prices include hardware and software licenses as well as three years maintenance.
The HFS A Series all-flash arrays support up to sixteen 8 Gb/sec Fibre Channel ports to link to servers for those who want to treat it like a storage area network, and eight iSCSI ports over Ethernet, running at 10 Gb/sec or 40 Gb/sec speeds, for those who want to go that route. Hitachi will add Fibre Channel links running at 16 Gb/sec speeds (eight ports, to be precise) at some point in the spring, and by summer it will also add support for 56 Gb/sec InfiniBand links – the latter being popular in HPC and parallel database environments. Windows certification should happen by March and scale-out support allowing for multiple Cheetahs to be lashed together is coming by the end of this year along with fatter 3.2 TB flash drives.
Servers are just starting to become available with NVM Express ports, which cut out a lot of the chatter between storage devices and the CPU and therefore radically improve IOPS and drop latencies for flash devices, and a number of vendors will be adding NVM Express over Fabrics to provide Remote Direct Memory Access (RDMA) connectivity between the flash storage and the compute complex for larger scale flash installations. Hitachi is aware of all of this, but is not committing to any particular time when this might be available in the Cheetah line. NVM Express over Fabrics could be part of that scale-out story later this year, or not. (The FlashArrays from Pure Storage implement NVM Express to link chunks of the flash memory to the CPU, but not all of the flash.) Madaio says that he believes that the all-flash array market will bifurcate going forward, with one chunk using NVM Express for super-low latency and then other devices sticking with SAS or SATA to try to drive as much flash capacity as possible into the datacenter.
In the all-flash array segment, the two products to beat are EMC’s XtremIO and Pure Storage’s FlashArray//m (the latter of which we covered in detail last June), although HPE, Dell, IBM are coming on strong and Tintri, NetApp, Tegile, Oracle, Huawei, Violin Memory, and Fujitsu also in the hunt. For the purposes of the HFS A Series, Hitachi kept the comparisons down to EMC and Pure Storage, with a focus on the density of the array and the read I/O operations per second performance.
Most disk array and flash array makers reckon their performance based on random reads of files that are 4 KB in size, but Pure Storage contends that a 32 KB file size is more representative of what it sees among its customers. Here is how Hitachi stacks up the read performance of the Cheetah arrays against two bricks of the XtremIO arrays from EMC and FlashArray//m70 from Pure Storage:
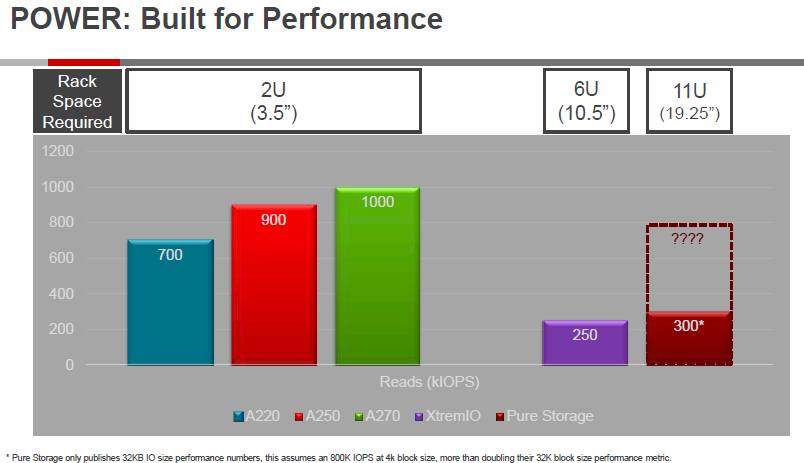
As you can see, Hitachi is estimating that, based on the 300,000 IOPS performance at 32 KB files that the Pure Storage FlashArray//m70 can handle about 800,000 IOPS reading 4 KB files.
Here is how the machines stack up based on the density of capacity and IOPS as well as power efficiency:
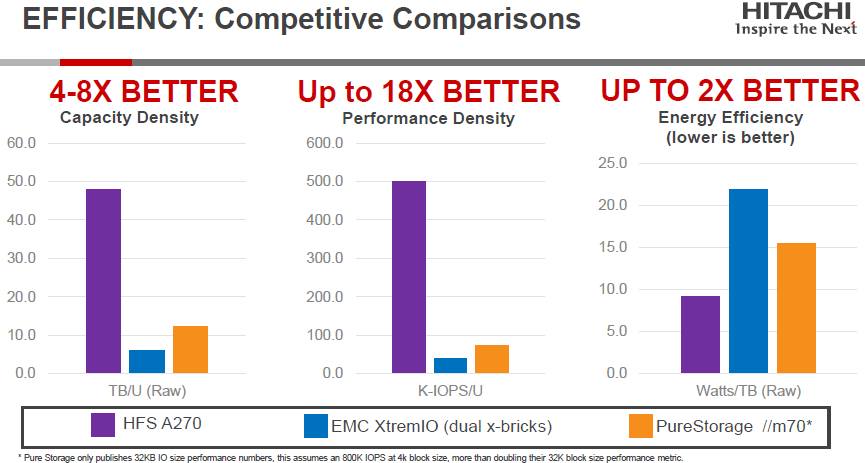
It would be interesting to see pricing on this chart, too, normalized for street price, effective capacity, and with software and supported added in. Very generally speaking, Madaio says that EMC is priced at under $3 per effective GB with the XtremIO arrays – in the same ballpark as the $2 to $3 per GB for EMC’s VMAX all-disk arrays, a number that Pure Storage is gearing its FlashArrays to beat. While Madaio explained to The Next Platform that HPE was being aggressive on price, pushing its all-flash 3PAR arrays down to $1.50 per effective GB last summer, we would point out that Dell is the real price aggressor in this market, announcing an all-flash version of its Compellent arrays last October that could bring in a 1.3 PB array at a cost of $1.42 per effective GB, and then with data compression (a new feature at the time) turned on, it could get a little better than 2:1 reduction in data and drive that cost down to 65 cents per effective GB. That is the floor in this market in terms of raw price, but you have to adjust this with performance, thermals, and density metrics to do a proper comparison.
Given how much data can be housed in a 2U enclosure these days, it is reasonable to ask if density is all that much of a differntiator. “In some cases, it is important, primarily with hosters and cloud builders where they really want to manage the growth of their rack space,” says Madaio. “We have found that many large customers like to build their own version of converged infrastructure, with servers and storage, and they are looking for compact storage that they can package into half rack bundles that they use to scale.” Being able to pack 4 million theoretical read IOPS into 8U of rack capacity will certainly get the attention of such customers.
Hitachi has been shipping flash into its various storage arrays since 2008, and through November 2015, when the VSP F Series all-flash arrays came out, it had sold more than 250 PB of flash in its storage systems. Madaio says that in all of 2015, Hitachi shipped 150 PB of flash, mostly in its hybrid VSP G Series machines, and in the fourth quarter pf 2015 alone, when the VSP F Series first started shipping, it shipped 50 PB of capacity. Those are some pretty big numbers. A lot of that flash is still going into hybrid arrays, Madaio adds, but there are customers who are buying all-flash units with 50 TB to 100 TB to test the waters and they will scale up from there, particularly as the cost of flash comes down. As for large customers, the top ten accounts each quarter for Hitachi buy more than 1 PB of capacity. But they don’t necessarily want it all in one array or one clustered array, as we have pointed out in the past. Most vendors we talk to say that once an all-flash array gets up to 500 TB or so, customers are worried that the blast radius of a device failure is too large. This is why we scale things out, after all.


Can Anyone Make Money From Modern Storage?
In the past three decades, there has been no shortage of companies with interesting ideas to solve very specific data storage and retrieval problems associated with high performance computing in some form or another. Many of them raised tons of money, and most of them got eaten by platform incumbents …

Pure Storage Breaks into Storage-as-Code, Data Services
The cloud era started off with the belief that, eventually, enterprises would migrate all of their workloads to the public cloud — drawn by the promises of greater flexibility and agility, cost reductions, manageable OPEX payment models, and the ability to shift responsibility for management of IT environments to the …
Hyperscalers Start Taking Pure Storage Flash For A Spin
Usually, innovation starts with the hyperscalers, HPC centers, and cloud builders of the world and spreads to the enterprise. But every once in a while, a technology establishes itself in large enterprises and the migrates upwards. This may be finally happening to Pure Storage, which was founded in 2009 and …
Be the first to comment