

The cloud era started off with the belief that, eventually, enterprises would migrate all of their workloads to the public cloud — drawn by the promises of greater flexibility and agility, cost reductions, manageable OPEX payment models, and the ability to shift responsibility for management of IT environments to the cloud providers themselves.
Over that past several years, that has morphed into hybrid clouds and multiclouds, with organizations sending some workloads to multiple public clouds while keeping some — for a variety of reasons, from security and compliance to expense and latency — on premises. However, this shift — along with the rise of such modern technologies as containers, Kubernetes, artificial intelligence, and data analytics — also has given rise to demand from enterprises for more cloud-like capabilities in their datacenters, from on-demand resources to flexible consumption models.
That has forced established datacenter tech providers to evolve from hardware makers to software and services providers, as seen with vendors like Hewlett Packard Enterprise launching its GreenLake platform, Dell Technologies with Apex and Lenovo with TruScale.
Pure Storage is no different. Starting out as a pioneer in the all-flash storage space, the company has evolved to offering its products as services, launching a flexible consumption model for block storage in 2017 and rolling out its Evergreen Storage Service (ES2) — offering its technologies through subscriptions a year later and eventually renaming it Pure as-a-Service. It made block, file and object storage available as a service, with all the cloud goodness of agile operations and economics.
Pure has continued to expand what it can do, as illustrated by its $370 million acquisition late last year of Portworx, a move that expanded its data services capabilities via Portworx’s Kubernetes-based multicloud platform. At the time of the acquisition, Pure Chairman and CEO Charles Giancarlo wrote in a blog post that modern organizations were embracing Kubernetes and containers as key elements in their embrace of cloud-native technologies and that Portworx would expand Pure’s reach in offering data services.
The twelve-year-old company this week continued the trend with the release of its Pure Fusion storage-as-code platform and Portworx Data Services database-as-a-service (DBaaS) platform, providing automated management capabilities to DevOps engineers responsible for juggling testing, development and production demands with such requirements as performance, availability and security.

“What we’re doing is driving an agenda where we’re not only focusing on what we traditionally did, which was best-in-class infrastructure, but also driving up the cloud operating model through modernizing operations,” Pure Chief Product Officer Ajay Singh tells The Next Platform. “We’re also going up to modern data services with Portworx Data Services. We’re moving our agenda more and more up stack and more multi-cloud infrastructure and Kubernetes-agnostic [and] accelerating operations with one-click automation. [The new platforms change] the positioning with the profile of the company from storage infrastructure to also include modern data services. Ultimately what we’re trying to do is enable technology teams to become internal multi-cloud storage service providers. We’ve got a lot of things on the roadmap. Essentially, we map out the customer journey to what we call a modern data experience, which is fundamentally delivering a cloud operating model. To do that, a key component of the modern data experience is modernizing the infrastructure.”
Pure’s roadmap also includes automating and driving the cloud, operating in both on-premises and multi-cloud environments. This is where the Portworx acquisition comes in, enabling Pure to move beyond managing operations to pushing data services that leverage Kubernetes.
A key to all of this is Pure’s continued focus on flash, which Singh says is gaining ground on hard disks in terms of cost. This will enable flash to overtake hard as enterprises build modern infrastructure, he says.
“We are going to hunt every hard drive, but it’s going to be a three- to four-year journey,” Singh says, noting the growing use of solid-state disks (SSDs). “We are two to three years ahead of SSD because we got direct to flash. … Traditional storage vendors had a ton of software already written for hard disk. They said, rather than having to rewrite this stuff, if I can make a solid state or flash appear like a hard disk, then my software will just work with it and I can go about my business. We have no legacy to the hard disk, so we started straight direct to flash. We’ve optimized the NAND at the individual cell level and therefore we get better data reduction. We’re starting to take out a lot of hybrid disks with some pretty big deals. If I were a hyperscaler, I would be scratching my head saying, ‘This thing is starting to roll into my infrastructure as well. In the next three to five years, I’m dealing with SSDs. I can do the easy thing, but I’m super cost-sensitive and I also want to figure out how to go to flash directly.’ We have a ton of IP in that space on the direct to flash.”
Through Pure Fusion, the vendor is taking a step into the world of storage-as-code. The platform pools arrays and enables enterprises to scale their storage environment up or down — even into the public cloud — with on-demand consumption and automated back-end, instant provisioning. It initially will integrate with Pure’s FlashArray//X NVMe and FlashArray//C all-QLC flash storage as well as Pure’s Cloud Block Store, with planned integrations with Portworx and FlashBlade, which consolidates file and object data.
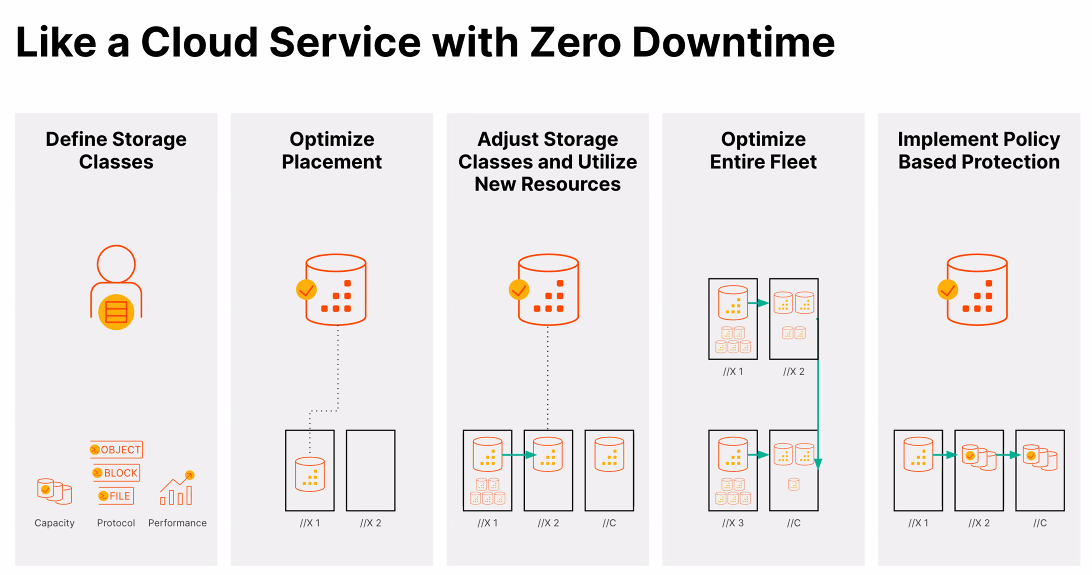
It leverages AI techniques to deliver self-service and storage-as-code automation — including tasks like workload placement and fleet rebalancing — and intelligent workload management to adapt to changing application needs. There are availability zones and an API framework.
“For storage admins, effectively they just need to define storage classes and capacities — file, object and block protocols, performance — and then Pure Fusion will optimize placement, adjust storage classes and utilize your resources as need be for applications,” Singh says. “You’ll optimize the entire fleet and implement policy-based production to appropriately do safe mode, snapshots, to protect against ransomware, those kind of items. In some sense, we’re upleveling to a cloud operating model for our storage offerings.”
Portworx Data Services gives Pure a position at the top of the stack, offering DevOps engineers a one-click way to deploy services on Kubernetes. They can choose options such as SQL, NoSQL, search and streaming.
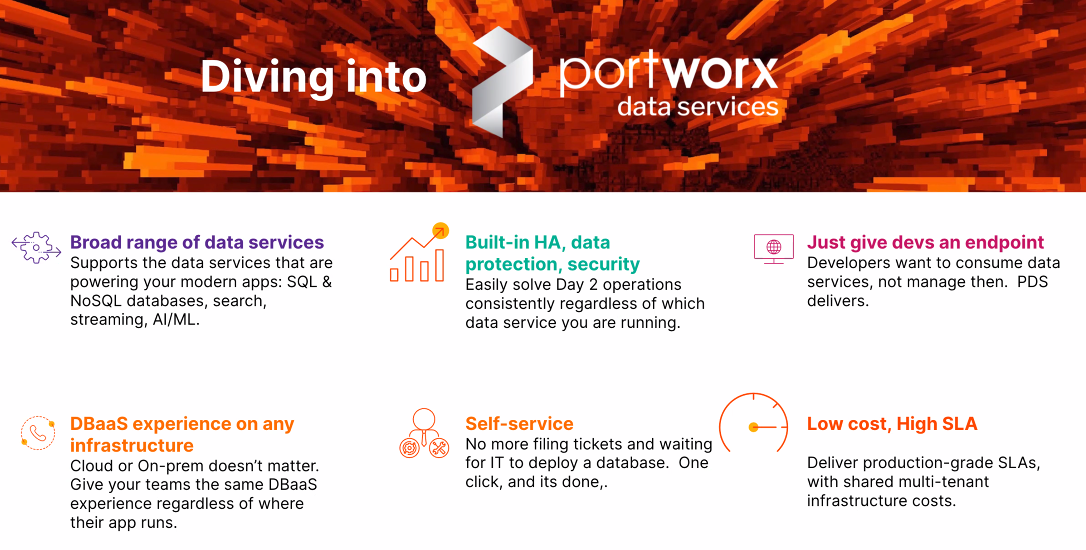
“We’ve spent a lot of energy on availability, secure access, migration, a whole bunch of data management services that you get automatically with PortWorx — [including] backup capacity [and] managing compliance,” he says. “On top of that software-defined storage platform, we’re also helping you accelerate your applications to include doing further automation, bridging the gap from what it is to automate your data platform to what it is to automate data services. This is what is new — the one-click PortWorx Data Services. With a single click deploy a Cloudera, MongoDB, PostgreSQL, Sandra Lastic, Kafka, Rubberneckers, etc., common data services that development teams want to use to accelerate the mining of data to drive new insights and to win in the digital transformation.”
The services also can run on any Kubernetes distribution, such as Red Hat’s OpenShift, VMware’s Tanzu, Elastic Kubernetes from Amazon and GKE on Google, and any infrastructure.
“Ultimately the buyer of this is pretty much the same buyer that’s buying Portworx because they are trying to become multi-cloud storage cloud providers or storage service providers or data service providers, because ultimately, that’s what businesses are asking for,” Singh says. “They don’t care about the storage they’re using. Dell or Pure or public cloud, they don’t care. They just want the services. That’s what they need to drive the insight and gain the insight from the data. If we can offer these services, all they need is an endpoint. They can run with it. This is what’s enabling infrastructure teams to step up, to become cloud data service providers.”
Pure will start with four or five services in the first half of next year, with more services rolling out over time, he says.

Hyperscalers Start Taking Pure Storage Flash For A Spin
Usually, innovation starts with the hyperscalers, HPC centers, and cloud builders of the world and spreads to the enterprise. But every once in a while, a technology establishes itself in large enterprises and the migrates upwards. This may be finally happening to Pure Storage, which was founded in 2009 and …
Flash To Kill Disk In The Datacenter – And This Time, For Good
The days of the disk drive have been numbered for so long that it is hard to take any prediction of its demise seriously. It is literally like predicting the demise of the IBM mainframe. In fact, the first rotating storage device with a moving head, the IBM 350 RAMAC …

Pure Storage Takes On Tier 1 Storage With FlashArray//XL
Since its inception in 2009 as a provider of all-flash systems, Pure Storage has carefully put together a portfolio that has many of the storage bases in the datacenter covered. Its FlashArray//C appliances take aim at the capacity needs of enterprises while the FlashArray//X systems are designed to address the …
Do whatever Pure, you know you are counting days much like HPE, DELL etc. If someone acquires you, good. Challenge with Pure and others is, unlike other tech changes historically, now the new players are fundamentally so different (read cloud vendors), they have no use for these type of Pure, HPE, Dell vendors. Unlike say a Salesforce buying a Workday, that can still happen, because they are cloud vendors. Or an SAP buying Anaplan, that can still happen, as SAP may want to scale cloud. So in ISVs this type of acquisition may happen. But in cloud infrastructure, the big cloud guys, have no use for on-premise vendors. If they want to build hybird offerings, which they are, they can do on their own
Good article!
“For storage admins, effectively they just need to define storage classes and capacities — file, object and block protocols, performance — and then Pure Fusion will optimize placement, adjust storage classes and utilize your resources as need be for applications,”
Does it require to define the priority_io while defining the storage classes or is it auto-managed based on performance?