
The old adage in the modern datacenter is that compute is free, but data movement is very, very expensive. We would add that data storage is also nearly free, although at the scale that hyperscalers and HPC centers operate, the numbers add up pretty quickly and suddenly you are spending tens to hundreds of millions of dollars to store data.
Hence, the whirring pace of innovation in storage, where data needs to be moved more quickly and stored less expensively to be of practical use.
As we have previously explained, DataDirect Networks got its start in 1998 as a storage provider dedicated to solving the unique storage and archiving needs of media and entertainment companies, but its first sale was to an HPC lab that grabbed that technology and adapted it to its own peculiar needs. Since its beginning, DDN has scaled the high-end of the storage market, spanning multiple industries where customers demand the highest throughput and capacity and the lowest latency. The company has been previewing its “Wolfcreek” storage server since June, and as promised, DDN rolled out two platforms that are based on Wolfcreek, also known generically as the DDN14K, at the SC15 supercomputing conference in Austin, Texas last week. One variant is the Storage Fusion Architecture 14K block storage server and the other is the Infinite Memory Engine 14K all-flash array.
The Wolfcreek system is based on a two-socket server using Intel’s “Haswell” Xeon E5 v3 processors and uses a mix of processor cores, DDR4 memory, and flash-based solid state disks to create varying degrees of capacity and performance. The system is, by default, upgradable to the forthcoming “Broadwell” Xeon E5 v4 processors, due early next year, since the Haswell and Broadwell chips are socket compatible. The system comes with two controllers, which operate in an active-active configuration
Generally speaking, the Wolfcreek SFA14K platform is able to deliver as much as 60 GB/sec of bandwidth on sequential read and write workloads or up to 6 million I/O operations per second (IOPS) on random reads and writes using 4 KB file sizes as the test. This is considerably more than the 48 GB/sec and 1.4 million IOPS that the prior generation of SFA12K generation delivered. DDN is still testing the average read latency of the flash drives in the system.
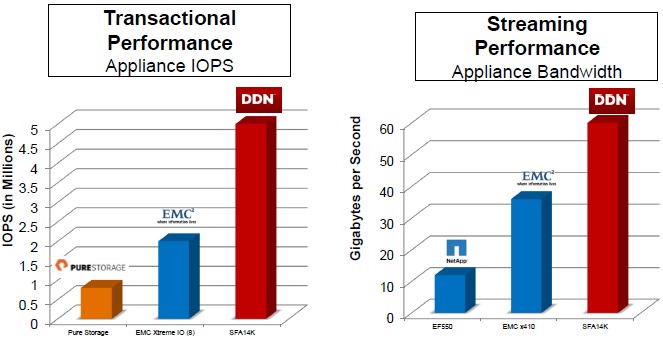
The base SFA14K is a 4U enclosure that has 72 drive bays that can support either 2.5-inch SAS drives or 2.5-inch SATA drives, depending on the need for speed or capacity. Within that system, 48 of those ports are linked to the compute complex through a PCI-Express fabric that supports the NVM-Express (NVMe) protocol, which has a much more efficient driver stack than the standard ones in the Linux and Windows Server kernels and which radically reduces the latency of the devices attached to the fabric. This is particularly important for latency sensitive applications, such as using the Wolfcreek platform as a burst buffer. (More on that in a moment.) The controller node in the SFA14K system supports RAID 1, 5, and 6 data protection on the drives, and has system fabric and expansion ports to add drive enclosures to the complex to increase its capacity as follows:

DDN has two drive expansion enclosures, the SS8462 and the SS8412, which come in 4U form factors as well and which support up to 84 drives in either a 3.5-inch or 2.5-inch form factor. Nearline SAS and SSD drives are supported in the expansion enclosures, and it looks like a 8 TB drive is the fattest drive that can be supported at the moment. The fully extended SFA14K with 1,752 drives and up to 13.7 PB is large enough for just about any customer looking at raw capacity. But capacity is not everything, and so it is also possible to expand the compute capacity of the SFA14K by adding multiple controllers and linking them together using a variety of protocols. At the moment, the SFA14K has a dozen InfiniBand ports, running at either 56 Gb/sec FDR or 100 Gb/sec EDR speeds, or a dozen Ethernet ports, running at 100 Gb/sec, for linking controllers. The array will eventually support Intel’s Omni-Path switching, which also runs at 100 Gb/sec, when it becomes generally available in the first quarter.
The SF14K array is used as a raw disk array providing block storage and it will no doubt be the basis of a preconfigured appliance running the Lustre or GPFS parallel file systems, as DDN has done in the past with its GridScaler line. (These have not yet been announced, but Shepard confirms they are in the works.) DDN is however debuting an SFA14K configured as a an all-flash array or as a burst buffer to sit between massively parallel clusters and their parallel file systems to smooth out the flow of data between the two, accelerating both compute and storage when they would otherwise slow each other down.
Importantly, the SFA14KE variant of the storage servers have enough oomph that customers can add all kinds of storage-related applications to the machines and execute them close to the storage rather than out on the cluster, reducing latency and working on the data where it sits rather than trying to move it, says Shepard. This is what DDN is referring to when it calls the Wolfcreek platform hyperconverged, which is akin to and somewhat broader than what enterprise storage makers mean when they use that word. (Hyperconvergence in the enterprise means virtualizing the storage area network and running it across a cluster of X86 servers while at the same time allowing bare metal or virtualized server applications to run on the controller nodes.) DDN will also be making VMware’s Virtual SAN as well as the OpenStack cloud controller equipped with Ceph object storage available on the SFA14KE platform. Other data management software, such as iRODS, DST, HPSS, DMF, and dCache, which are commonly used in HPC environments, can run locally on the SFA14KE’s controllers. There is also an option to run the kdb+ time series database from Kx Systems on the arrays, which is popular in financial services applications. The hypervisor of choice for most of these applications will be KVM, excepting Virtual SAN, of course.
Depending on the job, the Wolfcreek machine is configured with different processor, memory, and storage options, Laura Shepard, director of HPC markets at DDN, tells The Next Platform. And if customers want to run DDN’s block storage on their own commodity X86 server hardware, that is also an option, interestingly enough. The SFA14KE variant of the Wolfcreek platform will support thin provisioning, snapshots, in-line deduplication, compression, and asynchronous replication – features that many enterprise-class arrays have had but DDN’s SFAs did not until now.
DDN is not providing pricing information for the SFA14K or SFA14KE products, but they are available now.
One of DDN’s own hyperconverged implementations of the Wolfcreek storage platform is to configure it as an all-flash array, which is being productized as the IME14K. In this case, the Wolfcreek server is configured entirely with flash-based SSDs in all of its 72 slots. In this case, the controller nodes are configured with hefty 14-core Haswell Xeon E5 processors and 256 GB of memory. The flash drives come in 800 GB and 1.6 TB capacities and up to 48 of them can link to the server over four-lane NVMe links.
The IME14K sits between the parallel file system in a storage cluster and the compute cluster it serves, and is so blazingly fast that it essentially eliminates the file locking bottlenecks that sometimes hinder the performance of clusters. The IME14K appliance supports POSIX, Direct-IO, and MPIO data access methods on file systems and does not require customers to change their applications, which think they are talking to Lustre or GPFS as they always have. The parallel file system locking, small file I/O, and fragmented I/O patterns that are typical of HPC applications are accelerated and dealt with by the IME14K burst buffer, and all of the I/O is reorganized and stored so it can be streamed out of the back end of the buffer to the actual file system in a more sequential and less random fashion. The net effect is that writes to the parallel file system are dramatically accelerated.
As an example, Shepard shared some results on an HPC physics application called S3D that is commonly used to simulate fuel ignition. “It is a very interesting workflow in that you are looking at the transformation of materials as you are modeling them,” explains Shepard. “It is very complex, and notorious for I/O patterns that have small files and are fragmented, which is something that a parallel file system has a lot of trouble with because you end up with a lot of contention against the file system itself.”
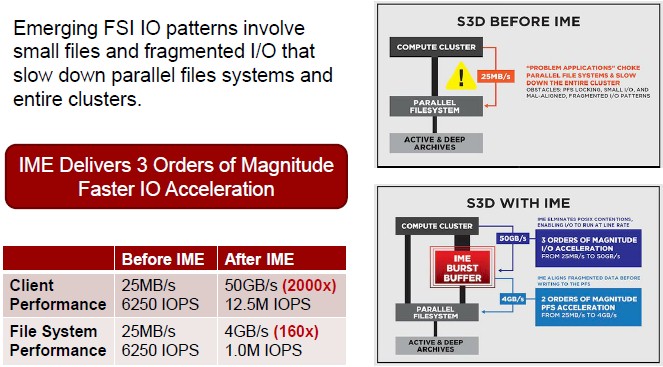
In the use case cited above, the customer above had a parallel file system that was capable of handling 4 GB/sec of bandwidth into the parallel file system, which Shepard said is typical of many HPC environments these days, but was only getting 25 MB/sec of performance out of the file system because of choppy I/O. Because of file locking contention, this customer ended up with a crippling performance hit, and it affected other workloads besides S3D that were running concurrently on the system. By adding the IME14K burst buffer, which was sized to take the full I/O load at 4 GB/sec, both the file system client and the file system itself could run at the speed it was originally intended to.
The IME14K will be used in a number of different roles in HPC shops, says Shepard. This includes being used as a burst buffer, where a workload has a big spike in I/O needs at some point and would normally choke the file system and the IME14K will sit as a shock absorber; checkpointing of an application state at periodic intervals is also a burst buffer use case. This is better than adding storage servers and drive spindles just to boost the I/O capacity of the parallel file system. The IME14K will also be used as a file accelerator for those workloads where POSIX locking becomes a bottleneck. The device will also be used as an application optimizer for writing fragmented I/O to the parallel file system in an orderly fashion, thereby attaining the expected performance out of that file system and getting rid of the “I/O blender” scenario that can plague HPC and virtualized enterprise workloads. (In the S3D example above, all three of these issues were happening at the same time.) The IME14K will also be used as what Shepard calls a “core extender,” which means that if need be, DDN can hang terabytes or petabytes of flash storage using the fast NVMe protocol for low latency off of clusters. This would be used for a dataset that is too large to fit into main memory in the cluster, but which is too latency sensitive to be pushed out to disks. In essence, no dataset is too big to be fast – provided you have enough cash to pay for flash, of course.
DDN did not provide pricing on the IME14K all-flash arrays, which will ship this quarter to select customers with general availability in the first quarter of next year.
What DDN will be focusing on is that the IME14K will allow customers to not have to build out their parallel file system infrastructure to boost performance, and in one example, Shepherd says that using this all-flash device as a go-between can make a $5 million cluster perform like a $100 million machine with a hefty disk-based parallel file system. This, more than anything else, explains why the storage hierarchy is being broken up and expanded by flash and other non-volatile storage. It is the only way to make things work better.


What’s Behind One NVMe Storage Company’s Meteoric Rise
There is plenty of potential to upset traditional storage via leveraging on-board NVMe devices and while the competition is thick and fierce, there are a few companies that are already standing out in 2021. It’s never easy to cut through the hyperbole and look at the real numbers for a …

NVMe 2.0 Firms Foundation for Future Storage Shifts
Amber Huffman and Peter Onufryk never could have imagined the little 100-page specification they worked on a decade ago would become a wide standard from phones and tables up to the largest datacenters in the world. But their early work on NVMe, now officially in its 2.0 incarnation with over …

Pure Storage’s Strategy Chief Talks Flash, NVMe, And The Competition
The external storage market – like most sectors of the IT industry – took a beating in the first quarter, thanks in large part to the novel coronavirus pandemic. According to IDC numbers released earlier this month, global revenue for enterprise external OEM storage systems fell 8.2 percent year-over-year, dropping …
Be the first to comment