

Amber Huffman and Peter Onufryk never could have imagined the little 100-page specification they worked on a decade ago would become a wide standard from phones and tables up to the largest datacenters in the world. But their early work on NVMe, now officially in its 2.0 incarnation with over 130 members, is still expanding—and it’s right on time given the changes in broad world of storage.
“When I started working with Amber on NVMe, PCIe SSDs were the wild west; drives cost $20,000 and everyone was doing their own thing like Micron and FusionIO. The vision we had was if we could standardize PCIe SSDs and today, it’s gone far beyond anything we could have imagined. Not only did we end up getting drivers into every major OS, it’s now morphed into fabrics and brought in even more folks from around the storage world,” Onufryk says.
The pair see the next major challenges and opportunities in the I/O realm revolving around computational storage, which they’ve laid the groundwork for in the new, fully refactored 2.0 spec, even if there is not enough common ground to directly build into the NVMe standard just yet.
NVMe collaborators have kicked off a task group to explore how to integrated the fragmented use cases around computational storage but it is still a bit of a wild west of its own, even if it’s been around for a while. “The challenge is aggregating enough common usages to build a standard that doesn’t end up fragmenting into a bunch of niches,” Huffman says. In addition to normal compression, for instance, there is also a need for pulling local and remote data, which is an emerging use case, but differs widely among shops who are all doing proprietary things with computational storage. The reason this is happening, Huffman explains, is that “there’s no common language or simple thing people can build on right now. That’s what we’re doing, setting the foundation to see how the pieces are eventually strung together.”
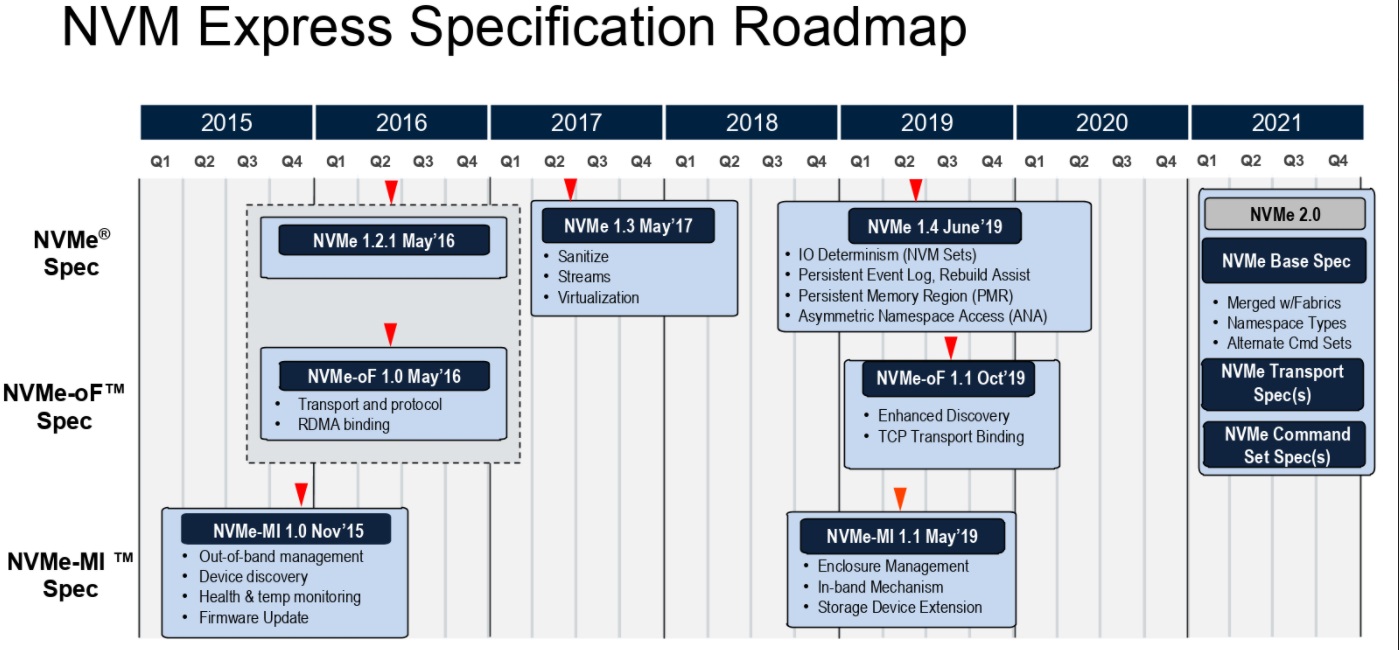
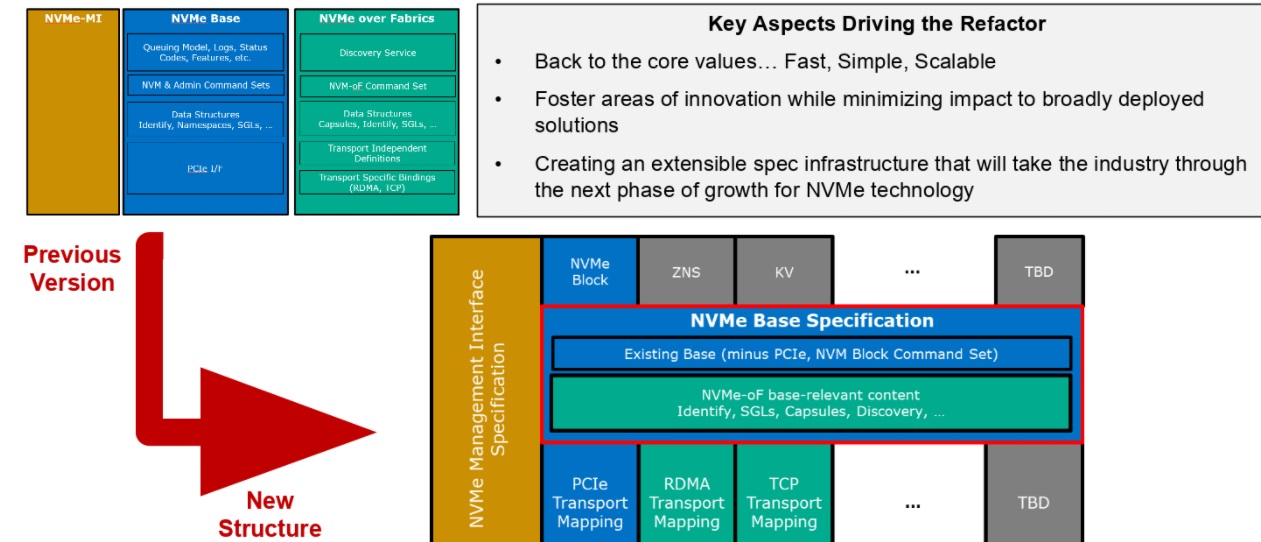
All of this has been top of mind during the creation of the 2.0 family of specification update, which involved a complete refactoring—something that was a long time coming a decade after the first iteration. Below is a sense of how the new refactored structure works. The team went from a separate base and fabric stack that always assumed a PCIe base to a unified foundational layer with command set specs (which now include key value and zoned namespaces—important additions) and a bottom layer for PCIe as well as RDMA and other things that will come over time.
Below are some of the key features that are part of the more streamlined, rich NVMe spec. The management interface remains independent and it’s now possible to do things like have DHH on NVMe while using the same NVMe software infrastructure end to end.
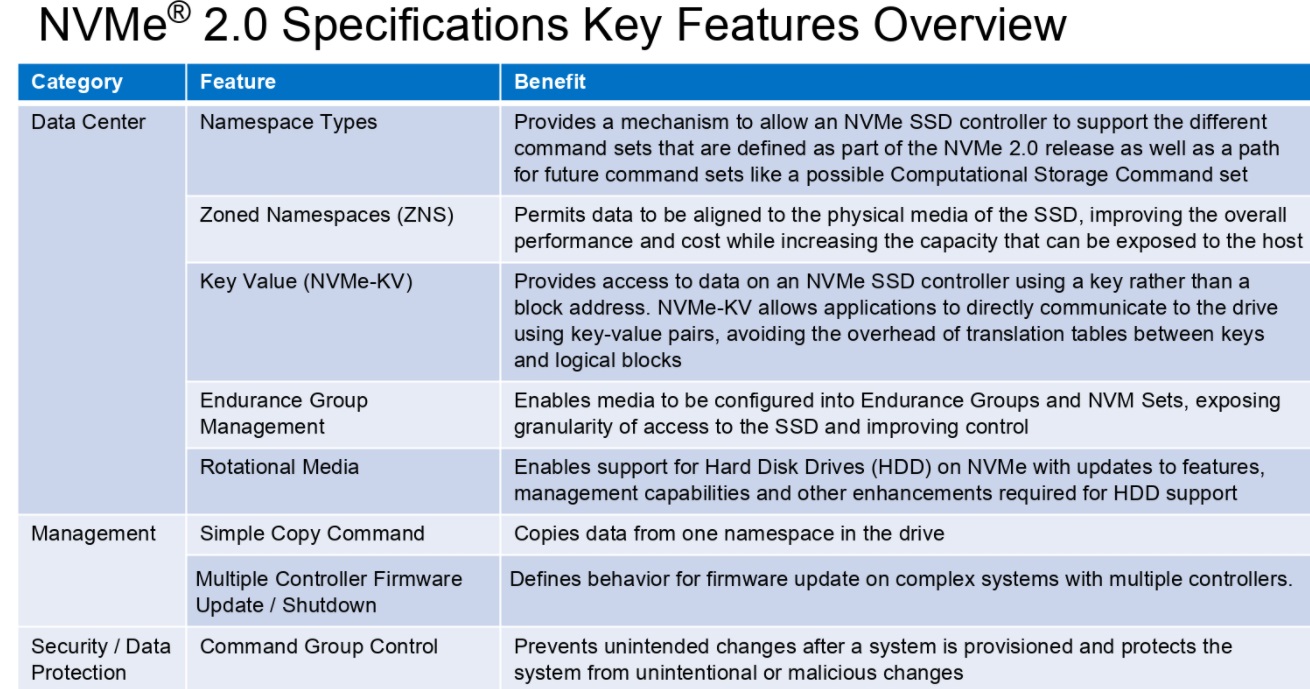
The more streamlined structure of the specifications library should make it easier to develop new NVMe use cases and push the flash ecosystem more broadly with its unified architecture. In terms of the hyperscalers, the addition of new features like zoned namespaces are likely to be most well received. “With NAND and people building their own drives, usage continues to fragment. We’ve given the ability to mix and match different flash and other technologies,” Huffman says.
This has become the language of the storage industry,” Huffman says. “Over time, people have wanted to innovate and add, so for example, NVMe over fabrics, zoned namespaces, all these things that people have brough to the table, often from a particular segment. If you just start adding it in together without refactoring at some point, you end up with one small change that craters a bunch of features that mattered.” While the process wasn’t simple, the new structure gives the NVMe team a solid foundation to meet storage opportunities as they arise. Computational storage was the one that kept creeping into the conversation and there is a path being carved for that and new transport technologies as well.


What’s Behind One NVMe Storage Company’s Meteoric Rise
There is plenty of potential to upset traditional storage via leveraging on-board NVMe devices and while the competition is thick and fierce, there are a few companies that are already standing out in 2021. It’s never easy to cut through the hyperbole and look at the real numbers for a …

Pure Storage’s Strategy Chief Talks Flash, NVMe, And The Competition
The external storage market – like most sectors of the IT industry – took a beating in the first quarter, thanks in large part to the novel coronavirus pandemic. According to IDC numbers released earlier this month, global revenue for enterprise external OEM storage systems fell 8.2 percent year-over-year, dropping …

Dell EMC’s PowerMax is Now All NVM-Express, Persistent Storage
When Dell EMC more than a year ago introduced the PowerMax storage array as the successor to the company’s all-flash VMAX offerings, the company touted the system’s readiness to leverage the NVM-Express (NVMe) protocol and, more importantly, its ability to serve as a gateway to NVMe-over Fabrics (NVMe-oF) and storage-class …
Be the first to comment