

As has been demonstrated, it is relatively easy to launch tens of thousands of containers on a single host. But how do you deploy thousands of containers? How do you manage and keep track of them? How do you manage and recover from failure. While these things sometimes might look easy, there are some hard problems to tackle. Let us walk through what it makes it so difficult.
With a single command the Docker environment is set up and you can docker run until you drop. But what if you have to run Docker containers across two hosts? How about 50 hosts? Or how about 10,000 hosts? Now, you may ask why one would want to do this. There are some good reasons why:
- In order to serve more users, you may experience limits scaling your Nginx Web server vertically, that is, using a bigger instance type at a cloud provider or stuffing more RAM into your pizza box on-premises. If you hit that wall, you will want the option to scale out horizontally, typically along with a proxy/load balancer as a stable entry-point to your service.
- Another aspect is that of fault tolerance. What if your lovely Redis container ceases to exist? Maybe because the underlying host died? You want to be able to fail over. In the context of container workloads, this means your orchestrator launches the container in question on a host other than the one that just caused you headache.
It depends on your motivation – scale, fault tolerance, or a combination thereof – if you end up with 10 or 1,000 hosts, but the challenges remain: How to scale containers across machines efficiently and effectively.
Before we get into the challenges and how to address them, however, let’s get some terminology sorted. Studies around cluster traces from Microsoft and Google suggest a workload classification as follows:
- There are long-running services that should always be up. Those usually serve interactive, latency-sensitive tasks such as end-user-facing Web apps or infrastructure services like Cassandra, ArangoDB, HDFS, or Quobyte.
- Then there are batch jobs ranging from seconds to many hours. They are typically less sensitive to performance fluctuations, while overall service level agreements (SLAs) in terms of completion time, incl. dependency management, may exist.
In addition to the above job type distinction, one wants to support a job prioritization: on the one hand (business critical) production jobs that contribute directly to the top-line of the revenue vs non-production jobs, for example for QA, testing and development.
From One To Two
With the terminology out of the way, let’s jump right into the challenges one has to overcome when running containers on more than one host.
The most basic question is: How many containers fit on one host? We found in various load tests on bare metal that not more than around 250 containers per host would be possible, potentially a limitation of the Docker daemon. Take an average of 20 Docker images for a simple microservices architecture based app, yielding roughly a 10X scale factor for a single app. Obviously, when you run more than one app on a single host, this can easily go down to 2X. Further, resource consumption poses a natural limit: assume that a single container might, for example, consume 100 MB of RAM; with a host equipped with 32 GB RAM – and minus 2 GB for the host operating system – this leaves us with 30,000 MB or the equivalent of 300 containers. This is way above the limitation we discussed earlier on. Scaling out, even under moderate load, seems inevitable.
Once you have two hosts up and running, happily serving your containers, you want to keep track of the following:
- What is the health of any given container? Is it still running and serving and if so what are its vital statistics (monitoring).
- Where do I find a certain container? That is, a mapping between the logical ID of the container to a concrete (routable) IP:PORT pair must be established and maintained, also known as service discovery.
- Application versions & upgrades. Whenever a new version of the app is deployed, the Docker images need to be delivered to the hosts (liveliness of and trust in the images).
The above list of functional requirements comes in addition to the core task of the orchestration system, which is scheduling the containers. (Or, to put in other words, to decide on which host to launch it). While this description is admittedly a simplification of the reality, it helps us understand the basic challenges of running containers on more than one host. For two hosts, any solution, including Docker Swarm, Kubernetes, and Mesos are a fit, with the latter two, while advisable, might seem like an overkill. Until your application is heavily used and you add the third, twentieth, or 487th host. Then, what?
From Two To Many
Earlier this year Google released details about its main production cluster manager, Borg.
Google’s median cluster size is about 10,000 machines with some clusters much larger, in the range of 100,000 machines. Google reports that a single Borgmaster (the brain of its proprietary cluster scheduler) can manage many thousands of hosts in a cell (Google terminology for cluster). A busy Borgmaster uses 10 to 14 CPU cores and up to 50 GB of RAM. Further, several cells have job arrival rates above 10,000 tasks per minute. While not everyone is Google or Twitter, for this matter, you can easily get into the hundreds of hosts dimension for a moderately complex enterprise application with thousands of in-house users or a popular consumer mobile app, with millions of users (and potentially thousands of concurrent users).
In a distributed system, keeping track of thousands of things (processes, connections, and so forth) and their state is a hard problem. What is the source of truth? Do you check in intervals from a central place? Do you run agents that push their state upstream? These and related questions have arguably been around for a while, for example in the form of the C10K issue from the late 1990s.
In addition, running thousands of containers (which as we already know from above requires hundreds of hosts) gives you a distributed system which has many complex failure modes, from time out-caused issues to network partitions to garbage collection CPU spikes or out-of-memory problems. Last but not least, in order to utilize the hosts efficiently, containers have to be bin-packed in the most efficient way; one particularly hard thing, especially when taking both job types (long running versus batch) as well as job prioritizations into account. You surely don’t want to lose $100,000 per hour in revenue just because a weekly scheduled Spark batch job thinks it needs to hoard large parts of your cluster, starving your enterprise application servers to death.
Summing up, scheduling containers across a cluster optimally means doing in such a way that
- if a failure occurs your service keeps running and
- your maximized utilization
is hard and dynamic.
Further, actually dealing with failures, i.e., making sure things that failed get rescheduled, potentially preempting other jobs
Now, since we’ve explored the problem space, let’s have a look at the solution space.
Mesos fulfils above laundry list of requirements, is mature, and – thanks to its two-level scheduling mechanism – also extremely flexible. In contrast to monolithic schedulers, which assume a one-size-fits-all scheduling mechanism, Mesos delegates the actual job placement decision into the hands of dedicated (so called) framework schedulers, while itself focuses on resource abstraction and management through applying the Domain Resource Fairness algorithm. This DRF algorithm essentially enables sharing different resource types (CPU shares, RAM, and so on) amongst jobs in a fair way.
Maybe even more importantly to this discussion, Mesos scales linearly. Already established back in 2010, in the original Mesos tech report (section 6.5, to be precise), an experiment was carried out on a cluster comprising 99 EC2 instances on Amazon Web Services, each with eight CPU cores and 6 GB of RAM. Some 50,000 slave daemons were launched across the cluster and the result is a linear overhead increase (always under one second), suggesting a linear scalability relation between the master and its slaves:
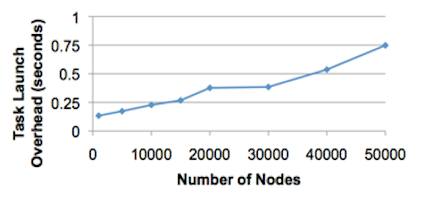
This linear scalability characteristic of Mesos is crucial for running containerized workloads, be it in a cloud environment or in a hybrid cloud setup (as in: mixed on-premises and cloud or between different cloud providers). To date, Mesos is the only open source, community project that has a proven track record (Twitter, Airbnb, Apple, and 50+ more companies) in this space and it will be interesting to see where the development will lead us.
Certain lessons learned from Google’s more than ten years of experience in running containers at scale – be it the pods concept found in Kubernetes or the optimistic offers, modelled after Google Omega – are already being introduced to Mesos core and on the other hand people can already now benefit from it using the Data Center Operating System, the commercial version of Apache Mesos, with the Kubernetes and Swarm packages.
We will continue to document advances in this space, so in order to learn more about how Mesos scales, keep an eye on The Next Platform.
Michael Hausenblas is a developer and cloud advocate with Mesosphere. He helps developers and system operators to build and run distributed applications. His background is in large-scale data integration, Hadoop and NoSQL, IoT, as well as Web applications. Hausenblas is contributing to open source software at the Apache Software Foundation, such as Myriad, Drill and Spark.




Be the first to comment