
When it comes to systems, the first thing that most people think of is compute. But if HPC is teaching us anything about system design – and one that is increasingly relevant as more and more data is being processed in memory in the corporate datacenter – it is that we don’t have a compute problem so much as a memory and I/O bandwidth problem.
The memory bandwidth issue is particularly acute, and as we try to scale systems up into the exascale range and beyond, it will get much worse unless something changes. This was certainly the theme of AMD’s research for the US Department of Energy’s FastForward projects, as we discussed last week. And it was also a recurrent theme among HPC architects who revealed their thoughts about future systems and memory subsystems design at the recent ISC 2015 supercomputing conference in Frankfurt, Germany. Al Gara, chief exascale architect at Intel and one of the designers of IBM’s BlueGene family of massively parallel supercomputers, spoke about re-architecting the compute complex of future HPC systems to accommodate new kinds of high bandwidth memory without having to sacrifice performance, providing a hint, perhaps, about how Intel’s future “Knights Hill” Xeon Phi massively parallel processor might be designed.
The memory bandwidth, CPU performance, and energy consumption issues that Gara discussed are equally applicable to general-purpose computing, too. So it could turn out that the possible future that he outlined, in a very general way and certainly not as a preview of forthcoming Intel products, will apply equally well to Xeon processors as they might to future Xeon Phi chips.
Gara is well aware of the innovations in processor and memory technologies that are underway among chip makers are academic researchers all over the world, who are looking beyond the silicon chip making technologies that we have perfected over the past many decades. But for the sake of exploration, Gara took a more pessimistic view of the future, one where we will have to get performance increases out of architectural innovation instead of a radical change in the underlying chip composition. He is fairly optimistic that we can get to very high levels of performance without such a jump, which is going to be music to plenty of ears in the HPC market.
“I think that memory technologies are going to allow for at least a 10X to 100X improvement that we will be able to exploit as we go forward,” Gara said. “In the end, I think that between 10 and 100 exaflops, we will be able to get there through architectural innovation if we don’t get some new magic replacement for CMOS technology.”
None of this means such a big jump in performance will come easy, of course. But the first big change that Gara was predicting is that we will have to reorganize the processor and memory complexes of future systems, and the reason why is that processors that have dozens of cores are running out of memory bandwidth. To make his point, Gara showed the interplay of performance and memory bandwidth on the biggest machines on the Top 500 supercomputer rankings over the past decade or so:
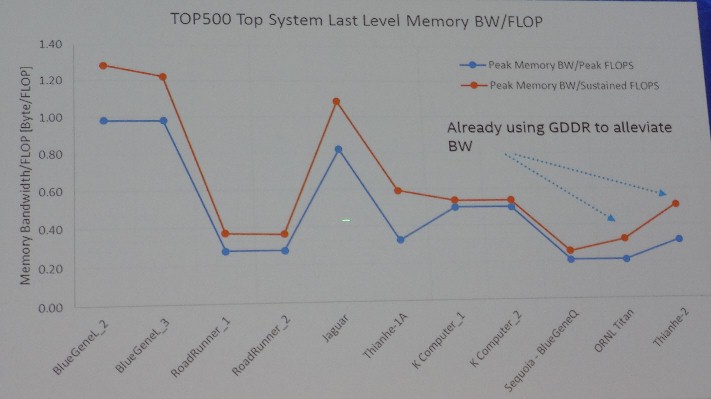
It is fairly easy to see that the memory bandwidth has not kept up with the floating point performance of systems and that only by shifting to Nvidia Tesla GPU coprocessors as core compute engines, with their high bandwidth GDDR5 graphics memory, have we been able to bend that curve back up to something pointing towards better balance. “I wanted to point out that in that we have already adopted something that is not a standard DRAM DIMM technology to get the bandwidth we need,” Gara explained. “The new high bandwidth memory technologies that are being developed offer a tremendous opportunity to address what looks to be a big problem for us – the memory wall. As the price of this memory drops to a price that is in a range where it gets similar to DRAM, it really starts to make us think about how we should be architecting systems.”
Even without price parity between these merging high bandwidth memory technologies, the performance benefits compared to DRAM DIMM memory commonly used in serve nodes is compelling for applications that are bandwidth-starved:
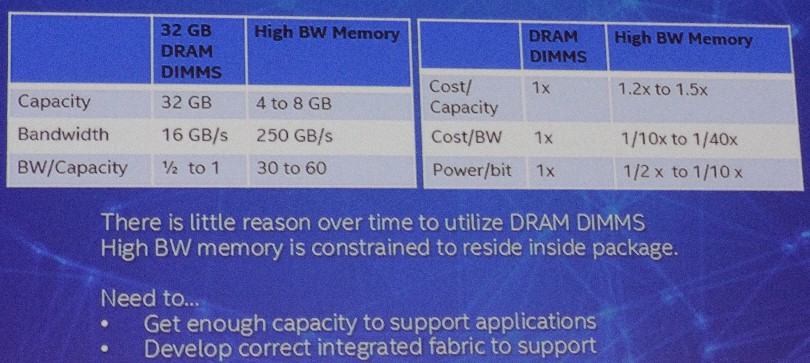
Gara says that these comparisons above between DRAM DIMM and on-package high bandwidth memory (HBM), which is being put on the chip package with Intel’s impending “Knights Landing” Xeon Phi processors and future Tesla GPU compute cards from Nvidia and graphics cards from AMD (which can also be used as compute engines), are conservative. The important thing is to look at the ratios of memory capacity to bandwidth and the cost of bandwidth and power consumption per bit. In every case, HBM (in a general sense, not a specific product) delivers at least an order of magnitude and sometimes more better metrics that DRAM DIMM memory that is the standard for servers.
To show the current state of the art with HBM, Gara showed off the Knights Landing Xeon Phi chip, which we detailed back in March here and added some new information about last month there. Here is the architectural layout of processing and main memory for Knights Landing:

The HBM memory that is on the Knights Landing package has a maximum of 16 GB of capacity, which is not a lot, but it will deliver over 400 GB/sec of aggregate bandwidth. That DRAM DIMM memory associated with the processor, which is sometimes called far memory by Intel, weighs in at 384 GB and has only 90 GB/sec of aggregate bandwidth.
Here is where it gets interesting. While that Knights Landing CPU will have 72 cores (which Intel finally confirmed last month), Gara says that what happens in a compute node with lots of cores it that it gets carved up into subdomains for the MPI message passing protocol used in modeling and simulation applications.
“The size of that [CPU] is really a cost optimization, the number of cores we put onto a chip,” explained Gara. “But one of the net impacts of this kind of architecture is that we cannot get quite enough memory into a package because of the size of the CPU die. That doesn’t mean there isn’t a solution. If we actually portioned this into a smaller CPU die, it won’t have any effect on writing MPI and MPI ranks since each one of these would have had multiple MPI ranks within it even after we have divided it up.”
So here is what a re-architeched Knights chip might look like:

The compute complex in this example is carved up into four bits and then the number of HBM stacks on the package is available to each chunk is quadrupled. (The capacity could go up even faster than that.) And, the design completely eliminates DRAM DIMM memory from the server node. The memory capacity and the compute capacity in the nodes remains the same. There are two issues to shifting to this approach, and they both have to do with economics.
“The high bandwidth memory in Knights Landing is not cost competitive yet with DRAM, but it is one of these technologies that is continuing to evolve and we expect that it will get more and more cost effective as it gets adopted more widely,” said Gara, who is obviously hopeful, like many, to see this technology take off as quickly as possible.
Cutting back on the number of cores is also counterintuitive, based on the trend in recent years for both general purpose processors like Intel’s Xeons and is specialized processors like Xeon Phi. (With Knights Landing, the Xeon Phi is for all intents and purposes a highly parallelized Xeon chip; it will even run Windows Server if you want to.)
“We have to be really disciplined in this because the thing that we will tend to think – and I know at Intel we always want to make things bigger – is that it is attractive to add more cores to this,” warned Gara. “What happens is when you add more and more cores, you end up needing more and more power, and because your system has a finite power limit, what will happen is that you will get fewer of these as you add more cores here, and as you get fewer of these blocks, you will end up constraining yourself. You will not be in an optimal solution. You may have as many cores, because most of the power is driven proportional to the cores, but you will get much less memory capacity per core than you would have wanted. So this sort of takes a level of discipline to get to this, but once you are disciplined to get to this point, you can really have this very elegant solution where you have a very clean memory system – single layer, enormous bandwidth – but we have more of these end points. So there is a fabric issue that needs to be addressed – you need to do this holistically from a systems perspective, but from a building block perspective, this is extremely attractive.”
That, we presume, is where the next generation of Intel’s Omni-Path Interconnect, a hybrid of the Cray “Aries” interconnect and QLogic InfiniBand interconnect, both owned and controlled by Intel, come into play. Gara did not name it by name, but we know generation two of the Omni-Path interconnect as well as the future Knights Hill parallel processors are to be used in the “Aurora” supercomputer at Argonne National Laboratory, due in 2018 or so.
The Omni-Path 200 series, as we presume this future interconnect will be called to be consistent with the Omni-Path 100 series due later this year, will sport 200 Gb/sec of bandwidth and presumably low latency suitable for HPC and certain other latency-sensitive workloads in the datacenter. (Think several dozens of nanoseconds, perhaps.) As Avinash Sodani, Knights Landing chief architect at Intel, already told The Next Platform, the memory bandwidth in the Knights Landing processor is so high that you cannot do NUMA or SMP clustering of them. But that does not necessarily mean you cannot link them together with a very fast interconnect and use Remote Direct Memory Access (RDMA) to share data between nodes.
Is This For HPC Only?
The big question, and one that Gara answered, is whether or not this architecture was far out ahead of the broader IT market, if HPC customers at the very high end were driving vendors like Intel in directions they didn’t want to go.
“I would say that there would not be one voice, one answer to that,” Gara said with a smile. “But my own view on it is that HPC is an area that allows us to explore more aggressive directions than what the broader computing environment will often adopt. So it is really an opportunity to have a significant market exploration into some new areas. I think it is a very positive thing. Now it is true that some of the forces in HPC are somewhat different than in the other markets, and some of the directions that we are going you would find that there would be some people that would feel that it is unlikely that those would ever be adopted by the rest of the market. It is largely a time scale thing in my mind, more than anything. Some of these things would be adopted immediately if they worked, and some of these things are going to take years before they get to that point. Like the in-package memory that I talked about, moving to a scenario where all of the memory is inside. We are not ready for that in the general market. Will eventually use this memory, when it gets to the right cost point and capacity point, I think even in that market it will start to play. But it will be significantly after the HPC market gets it.”
It will be interesting to see how the hyperscalers react to Knights Landing and Knights Hill. They would seem to solve a lot of problems for workloads that are constrained by memory bandwidth.

Intel Adjusts, However Slowly, To New Realities In The Datacenter
While chip designer and maker Intel has a new strategy and a new executive team to implement it, it is going to take a long time for changes made last year and this year to be felt and for product and process roadmap changes to put the company into a …

Keeping Pace In A Fast-Moving AI Space
During the Intel AI Summit earlier this month where the company demonstrated its initial processors for artificial intelligence training and inference workloads, Naveen Rao, corporate vice president and general manager of the Artificial Intelligence Products Group at Intel, spoke about the rapid pace of evolution in the AI space that …

Intel Hopes To Accelerate Datacenter And Edge With A Slew Of Chips
It is hard to say how many Xeon and Xeon SP CPU sales have been obliterated by Nvidia GPUs, but the number is a big one. And that is why Intel finally came around to the idea that GPU compute was not just going to be a niche thing, but …
This is an excellent article. I note with interest that most main vendors aren’t talking about the profound implications of this technology. It seems likely that they are concentrating on selling what they have today, ’cause the new memory technology is going to obsolete a lot of current products PDQ! Thanks for a really good newsletter.