

It you like technology, and you must because you are reading The Next Platform, then you probably like the idea of putting together the specs of a system and fitting it to a particular workload. This is the challenging bit when it comes to any technology, because no one wants to underprovision or overprovision the machine because that means wasting money. Sometimes lots and lots of money. Enough to take a lot of the fun out of the experience, in fact.
One of the things we want to do with this publication is learn how people tackle such problems, how they can think outside of the box (so to speak) and perhaps build a better mousetrap. System architects have to be aware of so many types of hardware and software options when they design their systems, which makes this quite a challenge. But it is one that IT shops face every day. And by system we do not just mean a server, but a platform, meaning servers that do the computing and the networks, storage, operating systems. and other systems software that makes it suitable for running a particular application. There are experts out there who know things about workloads and the systems that support them well, and we intend to find them and learn from their experience so you can as well.
We got to talking with Joseph George, executive director of big data solutions and hyperscale servers at Hewlett-Packard, as part of the company’s Apollo 2000 and Apollo 4000 launch back in May, about this Building A Better series of articles, and as it turns out, HP had just completed a new reference architecture for a Hadoop cluster that mixed its Moonshot microservers for compute and storage-heavy ProLiant SL4540 and Apollo 4510 series for storage. The machines are linked through 40 Gb/sec Ethernet switching. Most people probably find reference architectures a little tedious, but we here at The Next Platform think the devil is always in the details, and we study these things whenever we can to try to gain some insight into how the experts think a software stack and its hardware should be put together.
The interesting bit to us was that HP has broken the linkage between compute and storage within a single node and across the cluster with its new Hadoop reference architecture, and that means that compute and storage can be scaled independently from each other.
Breaking The Symmetry
Hadoop was originally designed to put a lot of storage inside server nodes and then dispatch compute jobs to the nodes where the data that they needed to chew on was located. It would be a lot harder to do it the other way around, of course, because no network can move terabytes of data instantly. This was surprising, and so we came back to HP and set about to get not only an explanation of this, but also to take on the larger task of helping people understand how the rules of thumb for architecting a Hadoop cluster has changed considerably in the past five years as hardware has changed and as the Hadoop stack has evolved with Hive, SQL overlays, and Spark in-memory processing, just to name a few interesting bits of software.
“I think that when we first all started with Hadoop, with general purpose servers with a balance of compute and storage was the simplest way to go about this. But what we are finding is that when you take Hadoop and start applying it to practical workloads, there are some cases where you want to apply more compute horsepower and there are other places where you want to deviate on the storage.”
Our desire with this type of story is to engage in conversations with system architects from industry and the vendor community to share their experience. Given the competitive nature companies and the edge that IT gives people, such information may not be as forthcoming as we would all like. But our commitment to you is to do our best to try to get our hands on it and share.
George knows plenty about tuning systems and to software (it is not always the other way around, you know), having steered the development of a number of products at Halliburton, BMC Software, and HP. At the latter company, notably, George was responsible for the Insight Control systems management software and its related integrated Lights Out (iLO) management controller for ProLiant server line. (This was several years after HP bought Compaq.) In 2010, George moved over to Dell’s Data Center Solutions custom server unit, which focuses on designing gear for hyperscale and cloud giants, and also managed Dell’s relationship with the OpenStack community for four years. Last June, George came back to HP, driving the development of the new Apollo machines, which offer some compelling compute and storage densities and which will give the Cloudline hyperscale servers that HP is building in conjunction with Foxconn a run for the money. But this Building A Better series takes some expertise, and for that George tapped Greg Battas, the chief technologist at HP, who held similar roles at Compaq and before that fault tolerant cluster maker Tandem Computers. (Compaq ate Tandem in 1996, Digital Equipment in 1998, and then was eaten by HP in 2001.) Battas was the architect on the hybrid Moonshot-Apollo cluster for data analytics, which is aimed at Hadoop and similar distributed software.
Back in the early days of Hadoop, the rule of thumb was that you needed to have one core for every disk spindle in the machine to provide a kind of balanced throughput within a node and across a cluster of machines. Achieving that core-spindle balance was not always easy. In general, disk capacity and CPU core counts are both driven by Moore’s Law, but their capacity increases do not move in lockstep and, equally importantly, the prices of terabytes and cores are not constant across the many capacities that are available within any generation of products. So even if you could somehow keep them in lockstep, the pricing might not be sensible. (Fatter disks tend to cost less per unit of capacity in the same model family, while CPUs with many cores tend to cost more per unit of capacity within the same family. Those many-cored chips are hard to make, and by the way, it is getting tougher to make fatter disks, too, and eventually prices will have to rise here as well along with capacity, despite Moore’s Law advances.)
“I think that when we first all started with Hadoop, with general purpose servers with a balance of compute and storage was the simplest way to go about this,” George tells The Next Platform. “But what we are finding is that when you take Hadoop and start applying it to practical workloads, there are some cases where you want to apply more compute horsepower and there are other places where you want to deviate on the storage.”
The issues get even more complex once a flash layer is introduced into the Hadoop cluster or in-memory processing is added through Spark, he adds.
Doug Cutting, formerly of Yahoo and chief architect at Hadoop distributor Cloudera now for the past several years, did not create the data analytics framework, which mimics Google’s MapReduce technique and its Google File System, until 2005, and it did not really take off in commercial settings until five years ago. Three or four years ago, says Battas, when Hadoop adoption was on the rise, customers tended to buy a workhorse ProLiant DL380 server with 32 GB of memory and one drive per core. (The drive bays in the system determined the core count, more or less, and customers tried to maximize the capacity per spindle as much as possible within the constraint of trying to mirror core and spindle counts.)
“Here we are, only several years later, and a cluster made of such machines would barely boot Spark,” says Battas. “Customers may think that their cluster could last forever, but the Hadoop stack is obsoleting it, with so many releases per year. We have had other customers come back to us and use underpowered DL380 nodes for raw storage and then add more DL380 compute capacity on top of that. With Spark, it is really not the raw memory that matters so much as the memory to core ratio. Because Spark scales out, we don’t need to have 512 GB of memory on each node. With Moonshot, we just add more nodes, and they are more cost effective and so we are in the knee of the price and the heat curves.”
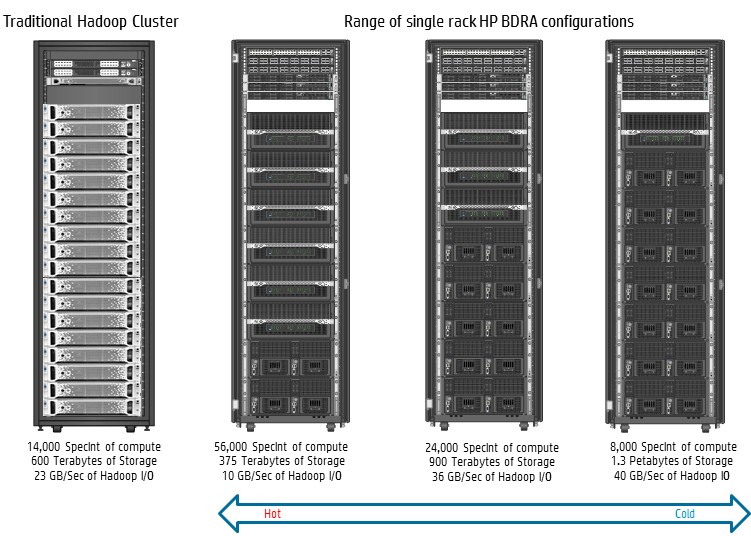
The reference architecture for Hadoop, Spark in-memory, Vertica database, and other similar workloads offers a range of machines that have a mix of compute and storage within a rack, as you can see in the chart above. The middle of the line reference machine, using ProLiant m710 server cartridges based on the four-core 1.8 GHz Xeon E3-1284 v3 processors from Intel for compute and the SL4540 nodes for storage, has more aggregate compute and storage capacity than a rack of DL380p Gen8 machines from the prior generation of ProLiant machines, which HP ran its tests against. HP is not using the Apollo 4510 storage server nodes yet for primary storage in this reference architecture, but is suggesting that it can be used for data archiving and backup.
Comparing a plain vanilla cluster to the balanced compute-storage configuration based on Moonshot and SL storage sleds, Battas says that asymmetrical Hadoop configuration offers 2.5X more density, meaning it would take more than 2.5 racks of DL380 servers to get the same compute and storage for the same Hadoop performance. The memory density in the Moonshot compute is actually twice as high, and the raw storage performance, as gauged in MB/sec of throughput, is 60 percent higher, too, on the storage nodes. The hybrid asymmetrical Hadoop system also burns half the power, and if you run the Terasort benchmark test on both machines, the hybrid architecture delivers 16 percent better bang for the buck.
On the Moonshot compute nodes for Spark/Hadoop, HP is getting away with 8 GB per core on a four-core Xeon E3 node. And Battas says that 8 GB per core on the compute side works well for a lot of workloads, and that HP was concerned initially that it would not be enough. “Once you have memory speed access, you get CPU bound again,” he says with a laugh. “So the balance actually stays pretty good. What ends up happening is that the ratio of compute to memory to storage to network bandwidth will change, because with Spark we pull things up to memory, we do a lot of work, and then we talk to storage again. This architecture allows me to double down on the compute and the memory as well as the network and the local SSD and not have to make a lot of HDFS noise to make that happen.”
In essence, by breaking the storage free of the compute, you can turn it into the much-talked-about data lake based on HDFS, and then have different kinds of frameworks and algorithms pull data from that lake and perform analysis on it using the best-suited compute for the job, whether it is wimpy core machines with lots of memory or big fat engines with high clock speeds or whatever.
“We are probably on the order of two to three cores per spindle in our middle of the road Hadoop configurations on this new architecture, but part of the reason we can do that is this architecture allows us to drive compute so much harder,” says Battas.
You might be thinking that running Spark on top of Hadoop (or next to it on a segment of the cluster because Spark does not require Hadoop) would create all kinds of network contention issues, with delays between where data is located and where it is going to be processed, but Battas says performance research shows that Spark is generally not network or storage bound, but compute bound.
“What we are finding with Spark and similar workloads that I can ship the data across the network faster than I can read it off the drives. Hadoop was built back when we had Gigabit Ethernet, and networking is growing at a faster rate than other parts of the system, so the storage bandwidth required in my system is actually less than the network connectivity. We try to unload a lot of CPU cycles from those storage nodes so we can max them out. We probably get twice the I/O per drive that we would get from a traditional system because we are able to push the disk drives much harder.”
The addition of flash is key, too. Take, for example, a simple sort. All of the data that you want to sort is sitting out there on a slew of disk drives, and it has to be sucked into the CPU and sorted this way and that. During any intermediary steps, the partially sorted data would be pushed back out to disks, pulled back into the CPUs, sorted some more, and so on until the sort is finished. With a modern Hadoop cluster, flash-based SSDs are put on the compute nodes and they are used to store the temporary results there on the node, so the disk drives are only bothered to get the data and then to store the final results of the sort. This is a lot less I/O across the network and puts a lot less strain on the storage and keeps the compute from waiting.
One of the key innovations that makes this asymmetrical hybrid Hadoop architecture possible, aside from very fast networking and flash, is the tiered storage that has been added to the Hadoop stack over the past several releases. That means using flash for boosting speed on certain Hadoop routines as mentioned above and HDFS on core storage, but also using cheaper object storage for archiving data.
The price/performance advantage of this architecture is interesting, but it is not the reason why customers are going for it, says Battas. What has them deploying this hybrid architecture is the fact that they can add compute as Hadoop, Spark, and other elements of the analytics stack change without having to obsolete the entire cluster – or add storage separately as data capacity grows. The way HP sees this evolving is that customers will swap out their compute as workloads change, and maybe the latest-greatest nodes with the most CPU and memory oomph get used by data scientists with complex algorithms, but the older nodes get used for batch jobs.
HP has, in fact, created a node labeling feature for the YARN scheduler in conjunction with Hortonworks, called YARN labels, and contributed it back to the Hadoop community; this feature allows for work to be assigned to particular nodes and for the work to be allocated dynamically to nodes using the Ambari provisioning tool. This is far better than building a point cluster for every line of business, and as Google Fellow Amin Vahdat pointed out in talking about Google’s internal networks recently, it is easier and more efficient to schedule jobs on a single cluster with 10,000 nodes than it is to put the same work on ten clusters with 1,000 nodes each.
If you have other clever ways to set up a Hadoop cluster, let us know. There are probably a lot of ways to tame that elephant, and we want to share the ideas.




Its very nice to see that the features like YARN labels (https://issues.apache.org/jira/browse/YARN-796) and HDFS tiering (https://issues.apache.org/jira/browse/HDFS-2832) are out and HP already have a reference architecture to utilize these new features.
However, this article does not cover the drawbacks of this architecture:
1. If you have X CPUs, Y RAM and Z HDD spindles hardly would I believe that the solution separating them into different servers would be more price efficient than putting them evenly across the DAS servers
2. I don’t understand why talking about MapReduce, Spark and other technologies like this people think of HDFS as the only storage for their data. In fact, both MR and Spark put intermediate data on the local disks on the nodes where the computations take place. This is why when we plan the cluster for X TB capacity and replication factor 3 you need X*4 TB raw disk space on it, because intermediate data might occupy up to the X TB of space on the nodes running your computations. And this is not a corner case, any reduce-side join in Hive would require you to put _both_ of the tables participating in the query to the local HDDs before proceeding with joining them. So this cluster with blades just won’t be able to handle most of the typical MR/Spark cases and you would have to failover to running the computations on the “archival” nodes which would be times slower than running the same on the standard DAS server
3. This architecture creates huge network contention and you should be very careful in calculating network oversubscription planning this kind of cluster. Having a big compute part means that you would mostly do in-memory computations and this is the point where the network would become your bottleneck. HP does not publish exact network topology and the amount of Moonshot servers per rack, so we can only hope that they have designed it properly.
This architecture looks interesting and density is very impressive – so engineering part seems pretty good.
However, implementation of this architecture using recommended HP parts seems to have no price/performance advantage whatsoever due to extremely high price of m710 cartridges (at least 2x times more than market price for slightly less dense – but faster – equivalents).
It’s also rather doubtful that for majority of server workloads E3-1284L v3 CPU has any price/performance or power/performance advantage vs (for example) E3-1240L v3 (25W) or E3-1265L v4 (35W) or even Xeon D-1540 CPU (which has 8 cores, can use up to 128GB – not 32GB – RAM and has built-in 2x10GbE support).