

We have been waiting for a long, long time for the ionic bond between compute and main memory to be softened to something a little more covalent and therefore allow for more complex storage structures to be formed within systems and across them.
With the advent of memory-class storage (or storage-class memory, depending on how you want to call it) and a slew of interconnects that have memory atomics to one degree or another – CAPI and OpenCAPI from IBM, NVLink from Nvidia, Gen-Z from Hewlett Packard Enterprise and Dell, CCIX from Xilinx, and CXL from Intel – this dream is ever so gradually becoming a reality.
We didn’t get a chance to see this at the time, but at the SC19 supercomputing conference back before the holiday season, the Gen-Z consortium (plus one member of the IT crowd that is not yet a member but who is vitally important to any compute and memory cause) was showing off some early prototypes of systems using Gen-Z in innovative ways, including what we are calling a memory server. Jimmy Pike and Kurtis Bowman, both of Dell Technologies, sat down to talk to us about what Gen-Z was up to and the possibilities for system design that they represent. Pike is a Senior Fellow and senior architect at Dell who was formerly the CTO for Dell’s Enterprise Solutions Group and before that the chief architect of the company’s Data Center Solutions hyperscale server and storage business; Bowman is the president of the Gen-Z consortium and also director of server architecture and technologies at Dell.
HPE and Dell uncloaked the Gen-Z memory fabric back in October 2016 in the wake of all of the work that HPE had done with the memory-centric ideas in The Machine concept system. It was not clear how Gen-Z would play out against all of these other protocols because, to put it bluntly, Gen-Z could be used as a replacement to any of the other protocols above. It certainly looked that way when we did an update on the Gen-Z effort back in September 2017. More recently, now that the server industry is falling into place behind Intel’s CXL standard for accelerator and persistent memory interconnects, it is becoming apparent that Gen-Z will be used to stitch together memory fabrics even if it could do these other jobs of linking server CPUs to accelerators and to dynamic and persistent memories. We may get to a Gen-Z only world in the long run, but in the short run, probably not. HPE is certainly laying some of the groundwork here, as it discussed at the Hot Chips conference last summer when it revealed its Gen-Z fabric switch ASIC design (which has native optical interfaces) as well as electrical-to-optical bridges for linking to legacy interconnects to the switch ASIC’s optics.
Just as a reminder, Gen-Z doesn’t care how it connects to anything. It can be a direct point-to-point link as well as switched, it can be to DRAM or SCM blocks, it can be to processors that in have various memories and accelerators (with their own memories) hanging off of them, or to FPGA or GPU accelerators that have their own memories, like this:
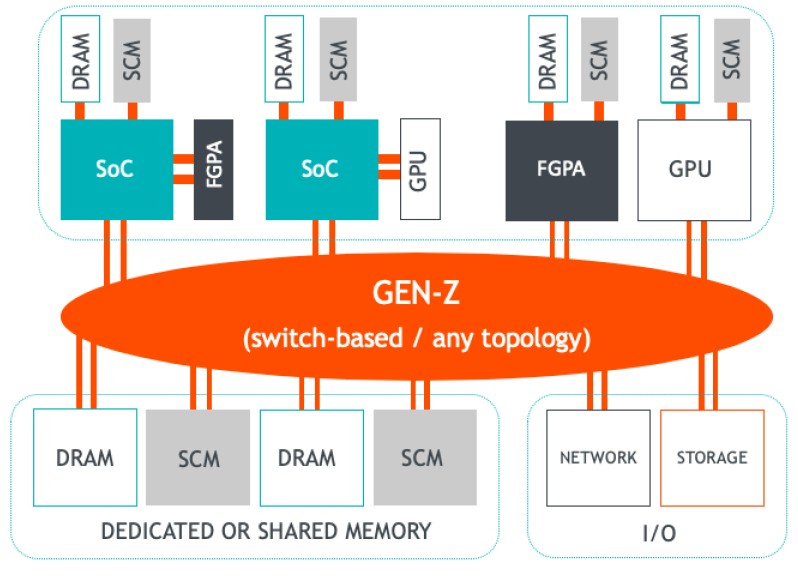
AMD, Arm Holdings, IBM, and Xilinx are among the members of the Gen-Z consortium, and while Intel has not joined, it is working with the consortium here and there and is keeping lines of communication open. Most of the major server OEMs and a few of the ODMs are on board, as are memory makers SK Hynix, Samsung, and Micron Technology. Among the Super 8 hyperscalers and cloud builders, Microsoft is the one that is most vocally supporting Gen-Z for its future infrastructure and Google is a member and is active. Amazon Web Services doesn’t really talk to anybody, but Facebook is, like Intel, keeping the channels open and is looking at the potential for Gen-Z. Alibaba and Tencent are doing much the same; we don’t know about Baidu or China Mobile or JD.com, the other Chinese hyperscalers. What we do know is that Broadcom and Microchip are both interested in making Gen-Z ASICs at some point, and HPE has already, as we said, demonstrated its own designs for switch and bridge chips.
It is still early days for Gen-Z, of course, and until there are native Gen-Z ports available on processors, accelerators, and memory devices, there is going to be a lot of bridging going on. This is how Bowman and Pike see Gen-Z playing out in the near term, both in the datacenter and at the edge:
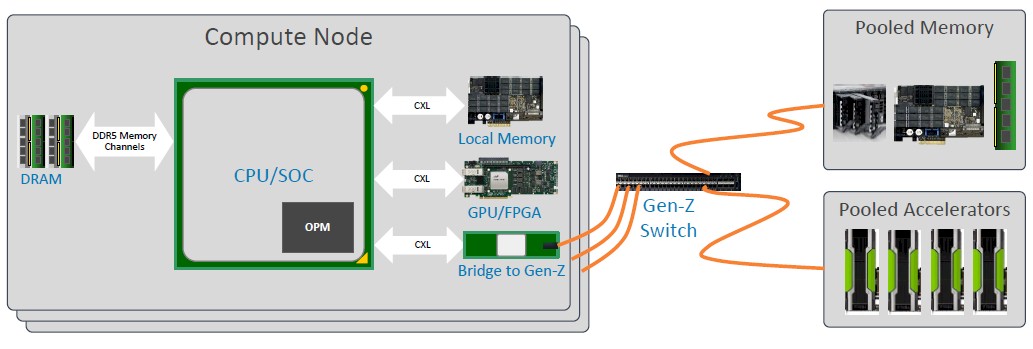
It is natural enough to wonder why system architect would not just want to use Gen-Z inside the chassis as well as outside across nodes and linking to JBOMs (just a bunch of memory enclosures). It comes down to money as much as availability.
“The reason you probably won’t use Gen-Z inside of the box is that it is going to cost you a little bit more,” Bowman tells The Next Platform. “I have to believe that all of the CPU vendors are going to come out with CXL support, and if they have CXL, they are not going to have a direct link to Gen-Z. That means that you will need the bridge that connects from CXL to Gen-Z, and then you can go out to pooled memory or pooled accelerators outside of the box. I think that you will find that people who just need a small pool of accelerators or a small amount of pooled memory inside the box will use the CXL link because it is going to be cheaper, since it works atop PCI-Express 5.0. Over time, if Gen-Z becomes ubiquitous, maybe you will see it coming out natively from some of the processors, just as we have seen happen with Ethernet controllers. But Ethernet still doesn’t come out of all of the processors natively.”
In the future, Bowman adds, on-package memory will bring an amazing amount of memory bandwidth for the processor, but directly attached DRAM as systems have today will still be there because it has the lowest latency and still has reasonable bandwidth, Beyond that, some of the memory will be attached to the system using CXL or be located in FPGA or GPU accelerators and linked back to the processors asymmetrically as Intel has designed CXL to support. But for certain applications, losing data in memory when a node goes offline for whatever reason will not be acceptable, and that is when Gen-Z bridging to what we are calling a memory server will come into play. Now, the memory is stateful but the compute using it is stateless. Or at least that’s the idea. And in fact, more than one compute node should be able to act upon a dataset stored in a memory pool provided there is enough bandwidth in the memory server and in the memory fabric to support it.
“The ability to do physical disaggregation but still maintain a logical connection is the key here,” adds Pike.
We concur, and think that in the long run, those companies that are doing disaggregation and composability over PCI-Express or Ethernet or InfiniBand networks will probably want something more like Gen-Z, which has memory atomics, lots of bandwidth, and optical links when they are ready.
As we said, some of these ideas are being put to the test right now by the Gen-Z consortium, which implemented a rack-level Gen-Z cluster as a demonstration at SC19. Here’s what it looked like:
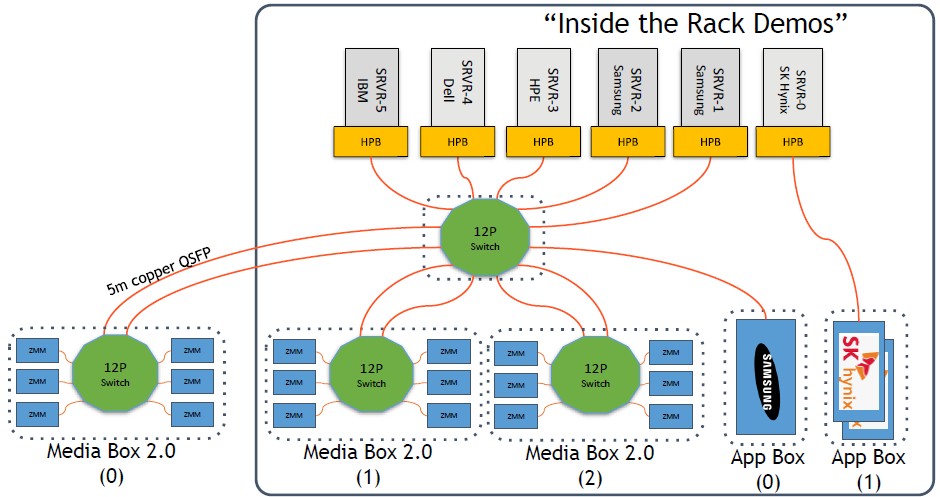
At the moment, Gen-Z switch and bridge chips are not commercialized, but the Gen-Z techies implemented the Gen-Z switch protocol and a twelve-port Gen-Z switch on an FPGA from Xilinx, and then they grabbed the 256 GB Gen-Z memory modules (ZMM) that have been created by Smart Modular, which put Samsung DRAM into a pluggable SSD-style form factor with Gen-Z connections and a DDR4 bridge to Gen-Z, to create that memory server. Here is what it looks like:

The Gen-Z switch adds about 30 nanoseconds of latency to memory accesses (both ways, coming and going), and in the demo, the Gen-Z switches implemented in the FPGAs are inside the memory server and another layer of switching connected servers to the aggregation switch in the middle. At some point, the Gen-Z switch will be implemented as an ASIC, and it will be a lot smaller and a lot less costly.
The testbed also had a setup from PLDA that showed a direct Gen-Z link between DDR4 memories on two Arm processors on a pair of Xilinx Zynq FPGA cards, where the average latency to access the memory across an optical card linking the two cards was 350 nanoseconds. This latency, says Bowman, is low enough to not require special pinning or other techniques of carving up the main memory; each device just sees a larger memory space.
The Samsung Gen-Z demo in the testbed had data stored for machine learning training one ZMM and shared across the Gen-Z fabric with all of the servers so they could all read the same data at the same time. It is not clear how far you can push this – at some point, with enough nodes hitting the same ZMM, you will create a hotspot. But you can always replicate the data to another ZMM and keep a reasonable ratio of servers to ZMMs.
SK Hynix did a benchmark test of local DRAM compared to the remote ZMMs connected by emulated Gen-Z ports and showed that the performance of the remote memory ranged between 85 percent and 90 percent of that of the directly attached DRAM. (We are not sure what the metrics were here, in terms of latency and bandwidth.)
Finally, the FPGA team at Intel worked with server makers HPE and Dell and chip designer IntelliProp to create a bridge from CPUs to remote Gen-Z ZMMs and compared the latency of a transaction processing benchmark on the SQLite database with the data being stored either on local NVM-Express drives on the server or on the remote Gen-Z memory. In this case, IntelliProp created a bridge from the UltraPath Interconnect (UPI) NUMA links used on “Skylake” and “Cascade Lake” processors to the Gen-Z protocol, in this case using a Stratix 10 FPGA from Intel. The latency of database reads was 5X lower across the Gen-Z link to the ZMM than it was for locally attached NVM-Express drives.
Now, we need to know what all of these components will cost, of course, if we are to make any buying decisions. If we know one thing for sure, it is that flexibility, low latency, high capacity, and zippy performance will come at a premium – and in many cases, customers will be willing to pay the Gen-Z premium.
That’s why we are bullish on memory servers. With a proper engineering of densely packed ZMMs, a 1U or 2U or 3U form factor could be crammed to the gills with memory capacity to create a shared pool across many servers, perhaps with only single-socket configurations and lots of cores and I/O going out to that main memory instead of doing NUMA work with all of those lanes. It will be hard to tell the difference between a system and a cluster in this future world where there are memory servers, compute servers, and storage servers, all glued with a Gen-Z fabric into a very memory centric cluster. Imagine, if you will, what MPI might look like on such a system.
There are so many possibilities, and we are just getting started.




Be the first to comment