

Those in the high performance computing world have been hearing about the applicability of burst buffers for some time now, but most talk about them is centered on their role in future pre-exascale systems at large HPC centers and national labs.
The initial target of burst buffers was to relieve the bandwidth burden on parallel file systems by providing an SSD cushion layer between the compute and storage systems, offsetting constant I/O demands. As the concept has evolved, new uses, benchmarks, and now products are being pushed forward as possible solutions for the data movement bottlenecks inherent to HPC machines–taking the idea well beyond improving the efficiency and performance of basic functions like checkpoint and restart.
With the arrival of the first commercial products that provide a true burst buffer (as Gary Grider at Los Alamos National Lab described them when he coined the term), there are finally some implementation and use stories filtering in, setting the stage for how they might function in much larger systems. While there is already some solid background on burst buffers in theory (the how it works) and future practice in the big DoE systems (the how it works in context), it is interesting to hear what smaller HPC centers and enterprise shops are getting out of the technology.
Among some of the early, mid-range HPC centers experimenting with burst buffers is the Irish Centre for High-End Computing (ICHEC). The hub has thick relationships with industry, including energy company, Tullow Oil. ICHEC assisted with the development and refinement of an in-house reverse time migration application called TORTIA, which like other seismic analysis codes common in energy exploration, is based on wave propagation and reconstruction to help oil companies find interesting areas ripe for plundering.
The application itself is not so different than other oil and gas codes in that it requires a large scratch element to the I/O environment. While the output data generated by the simulations is in small chunks, there is a lot of it—and it must be run forwards, backwards, and in some cases, used as a reference set to compare other data chunks to. In other words, even though HPC has large systems, it doesn’t mean that their file sizes are equal to their hardware. Cache is hugely important, with writes comprising a bulk of the I/O activity.
But backing up, there is some slight over-simplification of the application happening here, but the point is that these (very common in other areas) applications have a demanding I/O pattern. Take a look at the chart that represents TORTIA’s typical jaunt through the scratch and all about.
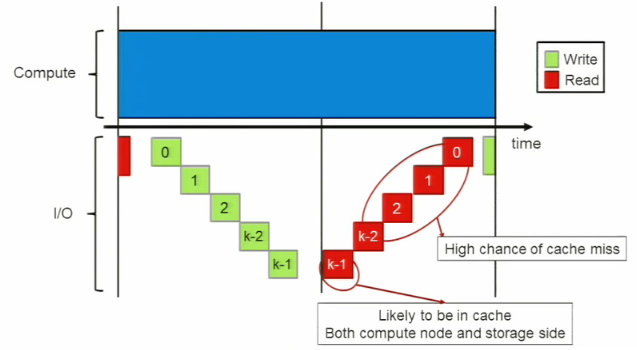
They are running TORTIA on a relatively small, eight-node Sandy Bridge-based cluster with a larger than usual amount of memory for its size (128 GB, for caching versus computation) connected with FDR Infiniband. The file system and storage environment is comprised of a DataDirect Networks SFA 7700 appliance with Lustre 2.5 file system and some rather impressive read/write rates (3.5 GB/s write, 3.3 GB/s read max).
 There is nothing incredibly notable about the infrastructure of this test cluster built to put burst buffers to the RTM test until one notices the IME pieces in the graphic nextdoor. These constitute the burst buffer via the DDN Infinite Memory Engine, which is one of a couple such offerings targeting the larger cluster folk (another being Cray’s DataWarp). These four IME servers, which are standard 2U boxes, each with packed with 24 SSDs equipped with 240GB.
There is nothing incredibly notable about the infrastructure of this test cluster built to put burst buffers to the RTM test until one notices the IME pieces in the graphic nextdoor. These constitute the burst buffer via the DDN Infinite Memory Engine, which is one of a couple such offerings targeting the larger cluster folk (another being Cray’s DataWarp). These four IME servers, which are standard 2U boxes, each with packed with 24 SSDs equipped with 240GB.
For their tests they used six of the eight nodes to see how the application performed with Lustre, running on the thicker memory nodes, and by using the burst buffer across three types of runs. One small test case for quick data validation for a total I/O size of 80 GB, a medium, normal-sized production run at 950 GB and a large 8.4 terabyte high-res one. As you can see below, the in-memory approach pooped out for high-res and Lustre was clearly strained as granularity increased, which while not a surprise, marks a notable curve:
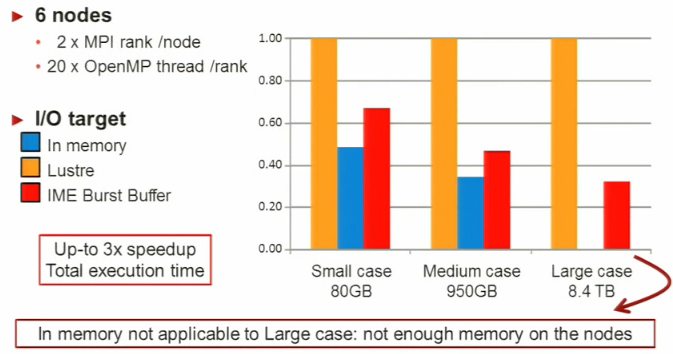
The main takeaway here is that even though this was run on a relatively small number of regular nodes (albeit with a memory boost), the results show where traditional approaches can peter out against an application that looks and smells a whole lot like many other codes in HPC. The small but numerous files, the dramatic emphasis on writes, and ensemble nature of the flow are all representative of what many HPC centers contend with. And yes, while SSDs are not a cheap proposition at this point, one can imagine that this is not the last we’ll hear about burst buffers in an increasing number of non-mega-DoE environments (yes, I wrote that on purpose).
Although it’s at a much smaller scale, Grider’s initial thoughts on the advantages of burst buffers played out for the Irish supercomputing folks as well, who will likely scale their use of the burst buffer nodes to support the time migration code—a bit of software that has quite a bit in common with other scientific computing workloads that use memory and scratch spaces in much the same way. While checkpoint and restart is one of the primary use cases Grider talked about early on with burst buffers, there appears to be some thought going into how it can take part throughout the simulation process, which is great news for Cray, DDN, and the small handful of others who are looking closely at I/O constraints on large, high performance computing systems.
We will start getting an even better sense of how burst buffers play out for other real-world applications on even larger machines soon enough. The technology is at the heart of the I/O and overall system utilization strategy for the upcoming Trinity machine, which will chew on National Nuclear Security Administration (NNSA) workloads, including weapons stockpile degradation simulations and lord knows what else. The Cray-built system will sport over 80 petabytes of storage in the Sonexion subsystem and employ Cray’s variation on burst buffers (they’re careful to note that they aren’t “just” to be considered as such) that are part of the newest XC40 line (although not part of a 5-petaflops machine they just won in Norway).
“The burst buffer might be in the 5-7 TB/sec and the disk system is 1-2 TB/sec,” Grider told me back when the system was announced. “The models show that you could sustain the 90 percent goal with less disk bandwidth, more like 10x less than the burst buffer bandwidth instead of the 4X to 5x on this machine. This was a deliberate choice because of the immaturity of the burst buffer solution space. This is the first burst buffer solution being deployed and it is a pretty large scale deployment as well, so there is reason to be a little conservative. If we had complete confidence in the burst buffer solutions at this scale, we could have saved money by buying less disk bandwdith. Future machines can be more aggressive in this area.”
While the best and biggest of the supercomputing systems might be getting aggressive, many centers are taking a close look at untying their I/O with the SSD tier for problems that go beyond the checkpoint and restart choke.

Weathering Heights: Of Resolutions And Ensembles
In the past year or so, watching supercomputer maker Cray, which is now part of Hewlett Packard Enterprise, has been a bit like playing a country and western song backwards on the record player. Supercomputing is booming a little (we don’t want to jinx it), Cray has its own interconnect …

Sneak Peek At “Sapphire Rapids” Xeons In “Crossroads” Supercomputer
Managing an aging nuclear weapons stockpile requires a tremendous – and ever-increasing – amount of supercomputing performance, and the HPC system business the world over is focused on this as much as trying to crack the most difficult scientific, medical, and engineering problems. Los Alamos National Laboratory has had its …

The Eternal Battle Between InfiniBand And Ethernet In HPC
It is always good to have options when it comes to optimizing systems because not all software behaves the same way and not all institutions have the same budgets to try to run their simulations and models on HPC clusters. For this reason, we have seen a variety of interconnects …
Be the first to comment