

Intel was the first of the major CPU makers to add HBM stacked DRAM memory to a CPU package, with the “Sapphire Rapids” Max Series Xeon SP processors. But with the “Granite Rapids” Xeon 6, Intel abandoned the use of HBM memory in favor of what it would hope would be more main stream MCR DDR5 main memory, which has multiplexed ranks to boost bandwidth by nearly 2X over regular DDR5 memory.
Intel had its reasons for adding HBM memory to Sapphire Rapids. The main reason was to boost the CPU performance of the exascale-class “Aurora” hybrid CPU-GPU supercomputer that Intel created with the help of Hewlett Packard Enterprise for Argonne National Laboratory. The Aurora machine has 21,248 of the Xeon SP Max Series CPUs packaged in 10,624 nodes that also have a total of 63,744 of Intel’s “Ponte Vecchio” Max Series GPUs. (That is two CPUs paired with six GPUs in a single node, which is about all that anyone can pack into the space of a Cray EX sled.)
The other reason to add HBM memory to the CPU was the hope that other HPC centers that were stuck on CPUs because they have not yet ported their applications to GPUs – or cannot expect to get good performance on their workloads even if they did – would see that having a CPU with a lot more memory bandwidth – on the order of 4X to 5X that of normal DDR5 memory – would significantly boost the performance of bandwidth-bound applications without the need to port those codes to GPUs.
We think the HBM on CPU idea is sound, and there are some notable machines aside from Aurora using such memory, including the “Crossroads” ATS-3 all-CPU cluster installed at Los Alamos National Laboratory in September 2022. Crossroads has a total of 11,880 of the Intel Xeon SP-9480 Platinum Max processors, which have 56 cores running at 1.9 GHz, for a total of 660,800 cores delivering a peak theoretical performance of 40.18 petaflops at FP64 precision in a power envelope of 6.28 megawatts.
But, as we said, there is no HBM variant of the Granite Rapids Xeon 6 processor with the fatter P-core cores, and that has left the door open for AMD to deliver an HBM-fronted CPU, which is the rumored “Antares-C” variant of the Instinct MI300 series of compute engines.
The “Antares” MI300X has eight GPU chiplets and looks and feels like a single GPU as far as software is concerned. The “Antares-A” MI300A used in the “El Capitan” system at Lawrence Livermore National Laboratory unveiled this week at the SC24 supercomputer conference has six GPU chiplets and three eight-core “Genoa” chiplets with a total of 24 cores. (Eight cores per chiplet.) With the MI300C announced this week at both the SC24 conference and at Microsoft’s Ignite event in Las Vegas, the MI300 package is completely populated with Genoa chiplets – that is a dozen chiplets in two columns of six – that yields a total of 96 Genoa cores running at what we presume is the same 1.9 GHz clock speed of the Zen 4 cores used on the MI300A hybrid compute engines employed in El Capitan. Those cores can scale up to 3.7 GHz in turbo mode with a single core active. The GPU chiplets on the MI300A, by the way, have a peak speed of 2.1 GHz.
This device is not sold as the MI300C, however, but is technical in the Epyc CPU product line and is known as the Epyc 9V64H and is explicitly aimed at HPC workloads, just like Intel’s Xeon SP Max Series CPU was. That said, the device plugs into the SH5 socket used for the MI300X and MI300A devices and not the SP5 socket used for the Epyc 9004 (Genoa) and 9005 (Turin) series.
It is interesting to note that AMD and its first customer for the MI300C device – Microsoft Azure – did not opt to create a variant of the compute engine based on the more current Turin Zen 5 cores. The work on the MI300C was presumably largely done when AMD started fabbing hybrid CPU-GPU chips for El Capitan, and AMD no doubt did not want to let that Turin cat out of the bag or maybe Lawrence Livermore would be asking for an MI355A that paired the tweaked Antares GPUs with the Turin CPUs for El Capitan.
(That would be fun, wouldn’t it?)
Having said that, it would clearly not be a big engineering stretch for AMD to create an MI355A or an Epyc 9V65H based on Turin chiplets based on Zen 5c cores. The Turin X86 CPUs were announced back in October, and they offer eight core Turin chiplets that are etched in 3 nanometer processes, allowing a 33 percent increase in chiplet count per socket and therefore a 33 percent in core count from 96 with Genoa to 128 for Turin top-bin parts. The layouts of Turin chiplets and the MI300 SH5 sockets might now map our right, of course, but in theory AMD could quickly put together an MI355C that has 128 cores by arranging sixteen X86 chiplets in two columns much as it has already done in the actual Epyc 9006 series. The question, really, is whether the new I/O die that is partitioned for the MI300 series can be mapped to the Turin chips.
Anyway, we digress. Frequently and with enthusiasm.
Importantly, the Epyc 9V64H has 128 GB of HBM3 memory that runs at a peak 5.2 GHz clock speed and that provides an aggregate of 5.3 TB/sec of peak memory bandwidth. A regular Genoa SP5 CPU socket using 4.8 GHz DDR5 memory delivers 460.8 GB/sec of bandwidth across a dozen DDR5 memory channels, by comparison. So this is a factor of 11.3X higher memory bandwidth across the same 96 cores of Genoa compute.
By the way, the Xeon SP Max Series CPUs launched in November 2022 had four stacks of HBM2E memory with a total of 64 GB of capacity and in excess of 1 TB/sec of aggregate bandwidth out of that memory. AMD is delivering 71 percent more cores, 2X the memory capacity, and somewhere around 5X the memory bandwidth of the Intel CPU with HBM.
The neat bit is that Microsoft is putting the Epyc 9V64H processor into its four-socket HBv5 instances on the Azure cloud, and the configuration looks like some things on the cores and memory have been geared back from their peak theoretical limits a little bit while others have been goosed.
The El Capitan system uses Infinity Fabric to cross-couple four MI300A units into a shared memory fabric for their hybrid CPU-GPU cores to all share 512 GB of HBM3 memory, and it looks like Microsoft is using the same architecture:
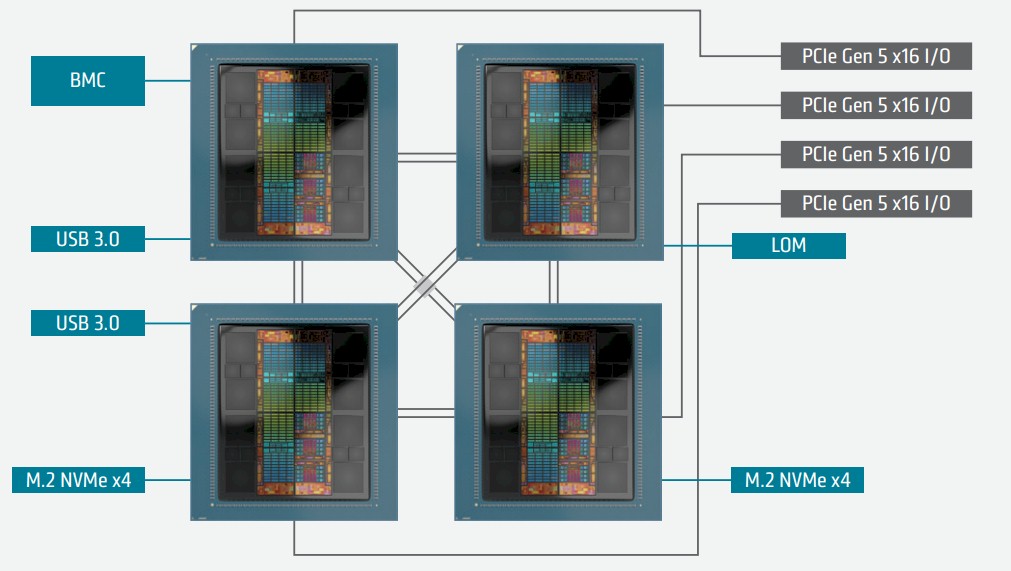
For all we know, whoever is making the system boards for Hewlett Packard Enterprise is making them for Microsoft Azure – and it might even be HPE who is making the boards for these Azure HBv5 instances as well as the whole server nodes behind them.
The four-way server card used for the MI300C – er, the Epyc 9V64H, pardon us – has four Infinity Fabric ports cross-linking the four SH5 sockets with 128 GB/sec of bandwidth across that memory fabric and then four PCI-Express 5.0 x16 slots that hang off of each node. This is twice as much Infinity Fabric bandwidth, says Microsoft, than any AMD Epyc platform to date.
In any event, the important thing – and the funny thing – is that AMD has made a four-way shared memory configuration using the SH5 sockets for its GPU-ish compute engines, but still tops out at only two-way shared memory configurations with its actual CPU setups. But, if you want an AMD four-way machine, it is possible as the El Capitan and Microsoft iron shows. AMD should be doing four-way servers to take on IBM and Intel at the high-end of the market for in-memory databases and analytics, and this lays the foundation for that work, we think.

To tackle workloads requiring high memory bandwidth in the HPC space, Microsoft Azure has been using the 64-core “Milan-X” Epyc 7V73X CPUs in its HBv3 instances and the 96-core “Genoa-X” 9V84X CPUs in its HBv4 instances. These are special variants of the Milan-X and Genoa-X chips created for Microsoft Azure by AMD, and the X variants, you will recall, have 3D V-Cache that triples their L3 cache and adds about 50 percent to 80 percent to their performance on the bandwidth bound applications that are typical among HPC simulation and modeling workloads.
The move to HBM memory just blows these 3D V-Cache numbers out of the water, and part of the reason, of course, is that the MI300C complex has “Infinity Cache” underneath those X86 core tiles that acts like a superfast go-between linking the cores to the external HBM memory. We have said it before, and we will say it again: All chips should have 3D V-Cache once it is cheap enough, if for no other reason than to leave more room for other things on the compute complexes and to shrink the L3 cache area on the cores.
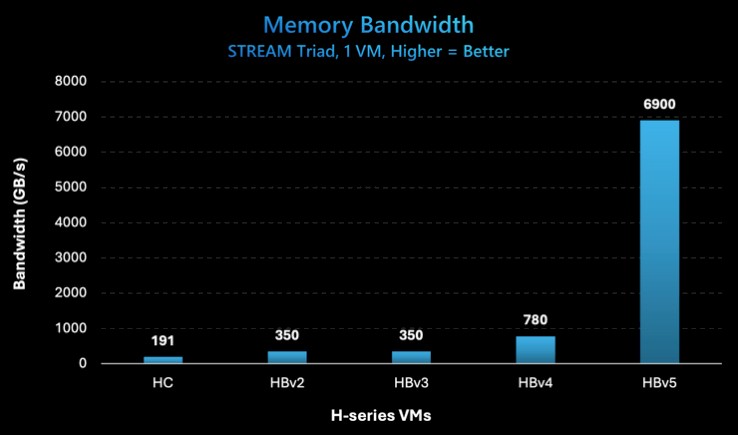
Here is a fascinating chart that Microsoft put together showing the bandwidth benefits of moving to the MI300C for a 96-core Genoa compute complex:
When we were talking to Bronis de Supinski, the chief technology officer at Livermore Computing at Lawrence Livermore National Laboratory, about the El Capitan machine this week at the SC24 conference, he commented to us that the CPU cores “get more bandwidth than they can drive.” And that might explain why more CPUs don’t have HBM memory.
If we take 5.2 TB/sec per MI300 series SH5 socket across 128 GB of HBM3 memory and we put four of these together, we get 20.8 TB/sec of aggregate bandwidth across four SH5 sockets. On most machines we have looked at over the years, a STREAM Triad benchmark delivers sustained memory bandwidth that is about 80 percent of peak theoretical bandwidth out of a single device. So call that 16.6 TB/sec sustained on STREAM Triad. The NUMA nature of that Infinity Fabric has its own overhead, to be sure, and it is hard to say how much that might be. On CPU systems, a four-way NUMA setup delivers about 3.65X the performance against that theoretical 4X. (On a two-way socket with twice the links between the CPUs, you are talking about 1.95X against the peak theoretical 2X.)
But on the STREAM Triad test run by Microsoft Azure on its HBv5 instance, the sustained memory bandwidth came in at 6.9 TB/sec, which is a lot lower than the peak aggregate bandwidth of 20.8 TB/sec. Given that the CPU cores might not be able to drive the high bandwidth like a far larger number of GPU cores with massive amounts of parallelism, perhaps it is necessary to gear down the HBM memory subsystem to match what the CPUs can and cannot do. It is an oddity, and we have calls out to both AMD and Microsoft to help us better understand the situation where the STREAM Triad results are about 2.2X smaller than we expected given NUMA overheads and past STREAM test results on independent devices.
Having said all of that, good heavens 6.9 TB/sec out of a four-way server just beats the pants off the other two-socket servers that Azure is using to boost the performance of HPC applications that have memory bandwidth issues. (So do we. We don’t judge.)
The HBv5 instance makes somewhere between 400 GB and 450 GB of the 512 GB of HBM3 memory in the system available to HPC applications. At the top end of that range, that is an average of 3.5 GB per core, which is a lot better than the slightly more than 1 GB per core of the Sapphire Rapids HBM setup. The HBv5 instance on Azure can have up to 9 GB of memory per core because that memory per core is user configurable. Of the 384 cores on the box, 352 of them are available to the applications running on the instance. Somewhere between 62 GB and 112 GB of HBM3 memory and 32 cores are allocated to overhead in the HBv5 instance. (The wonder is why this hypervisor and other overhead isn’t offloaded to a DPU as Amazon Web Services does with “Nitro” NICs and that Google is trying to do with “Mount Evans” NICs.
The HBv5 instance has SMT disabled to boost performance, and this is a single-tenant instance, too. The instance has a single 800 Gb/sec Quantum 2 InfiniBand port, which is carved up into four virtual 200 Gb/sec ports, one for each socket in the box. These InfiniBand NICs are used to cluster the nodes together to share work, and with Azure VMSS Flex, which is short for Virtual Machine Scale Sets and which the “Flex” means it is flexible in that it spreads VMs across fault domains in a region or availability zone, Microsoft says it can “scale MPI workloads to hundreds of thousands of HBM-powered CPU cores.”
Which means Microsoft has already installed thousands the quad-CPU servers in various regions already to be able to make that claim. The systems also have an Azure Boost network interface card based on Ethernet that provides 160 Gb/sec of connectivity for the machine underneath the HBv5 instance. That machine has 14 TB of NVM-Express flash that can read data at 50 GB/sec and write data at 30 GB/sec.
The HBv5 instances are in preview now, and it is not clear when they will be available. The MI300C – er, Epyc 9V64H – is currently only available through Microsoft and was apparently develops in close collaboration with Microsoft, which wants to get more HPC codes running on Azure. Having hardware that can deliver GPU-class memory bandwidth on CPUs that do not require the porting of code is definitely a greasing of the skids from on premises to the cloud for many HPC customers.
That said, we think that it would be good if the OEMs and ODMs could get their hands on the MI300C. Perhaps with the MI355C or the MI400C, this can happen.

Debunking Datacenter Compute Myths, Part Two
Welcome to the second part of our Debunking Datacenter Compute Myths series. In the first part of this series, which you can see here, as well as in this second part, The Next Platform sat down with Lynn Comp, vice president in AMD’s server business unit, to talk about some …
Why TSMC Did A $100 Billion Deal With Trump On US Chip Manufacturing
All presidents of these United States have the bully pulpit from which to lecture the American people and, for the past century, the rest of the world about how the global economy and culture should work. Donald Trump has certainly used this pulpit in his first and now second terms …
Datacenter Will Be AMD’s Largest – And Most Profitable – Business
Two and a half years into the global coronavirus pandemic we all have upgraded our home IT infrastructure. And after several fibrillatory interest rate shocks by the major governments to try to curb inflation in the world economy, spending on PCs has consequently taken a nose dive. And a glut …
An interesting chip to be sure! If I understand, it has HBM, no DDR5, and possibly CXL 2.0 off of PCIe 5.0 for extra RAM. Comparing this to a non-HBM Granite Rapids (or other) may be like the reverse comparison of Sapphire Rapids with Genoa that we saw earlier, where Streams and HPCG benefited most — but then, Granite Rapids’ MRDIMM also does quite a number on HPCG ( https://www.nextplatform.com/2023/06/12/intel-pits-its-sapphire-rapids-xeon-sp-against-amd-genoa-epycs/ ).
With the CPU Max’s ability to boot into either HBM-only, Flat, or Cache modes, those chips provided a nice opportunity for TACC to evaluate the resulting performance, and it seemed that WRF and AWP-ODC benefited most from HBM-only mode (nearly 2x), and no workload was negatively impacted ( https://www.nextplatform.com/2023/11/12/putting-taccs-stampede3-through-the-hbm-paces/ ). This tends to support this here 9V64H’s HBM-only hypothesis (or bet!).
So I guess these Azure HBv5 4-packs of Epyc 9V64H should be ok for the target HPC jobs … though CXL 3.0 on PCIe 6.0 would be a nice upgrade, and the ability to fully tier memory, between HBM, DDR, and CXL, could be a real bonus IMHO ( https://www.nextplatform.com/2023/01/24/building-the-perfect-memory-bandwidth-beast/ )!
Gotta think there is a market for this in the normal world. High volume high speed databases, anyone? I think your point about getting the bandwidth benefits of HBM without having to port code to GPU is very well made.