

We said it from the beginning: There is no way that Meta Platforms, the originator of the Open Compute Project, wanted to buy a complete supercomputer system from Nvidia in order to advance its AI research and move newer large language models and recommendation engines into production. Meta Platforms, which has Facebook as its core platform, likes to design and build its own stuff, but got caught flat-footed by the lack of OAM-compatible GPU and matrix accelerators and had no choice but to buy an N-1 generation DGX SuperPOD system using InfiniBand interconnects between modes.
And now, as Meta Platforms looks ahead to the future of AI inside the social network and the interconnect underpinning the compute engines it must lash together at incredible scale to compete against its hyperscaler and cloud builder rivals, it is back to Ethernet interconnects. This is why Meta Platforms is one of the founding companies behind the Ultra Ethernet Consortium, a buddy movie collection of Ethernet ASIC suppliers and switch makers who do not really want to cooperate with each other but who are being compelled by the Internet titans and their new AI upstart competition to figure out a way to not only make Ethernet as good as InfiniBand for AI and HPC networking, but make it stretch to the scale they need to operate. That would be for Meta Platforms around 32,000 compute engines today, and then hundreds of thousands of devices and then over 1 million devices at some points in the not too distant future.
What unites these companies – Broadcom, Cisco Systems, and Hewlett Packard Enterprise for switch ASICs (and soon Marvell we think), Microsoft and Meta Platforms among the titans, and Cisco, HPE, and Arista Networks among the switch makers – is a common enemy: InfiniBand.
The enemy of my enemy is my ally.
The math is very simple. In the early 2010s, when the hyperscalers and cloud builders were really starting to build massive infrastructure, the networking portion of any distributed system represented less than 10 percent of the cost of that overall system, including switches, network interfaces, and cables. As the first generation of 100 Gb/sec gear came out, the costs were very high because the design was not right, and soon networking was representing 15 percent or more of the cost of a cluster. With the advent of affordable 100 Gb/sec Ethernet and now the advance to 200 Gb/sec and 400 Gb/sec speeds, the cost is now down below 10 percent again – but only on the front end network where applications run. For AI training and inference infrastructure among the hyperscalers and cloud builders, Nvidia will tell you plain and simple that the network represents 20 percent of the cluster cost. InfiniBand, explains Nvidia co-founder and chief executive officer Jensen Huang, delivers 20 percent better performance at scale at the same bandwidth than Ethernet, however, so “InfiniBand is effectively free.”
Well, no. It is not free. You still have to come up with the cash, and it is 20 percent of the cost of the cluster, which is impressive when you think of the very high cost of GPU compute engines compared to the overall cost of a Web infrastructure cluster based on CPUs. The cost of InfiniBand networking for AI systems, node for node, must be enormously more expensive than Ethernet – admittedly at a lower bandwidth – was on other infrastructure clusters to run databases, storage, and applications.
And this was why Ethernet with RDMA over Converged Ethernet – a kind of low latency Ethernet that borrows many ideas from InfiniBand – was on display at the Networking @ Scale 2023 event hosted by Meta Platforms. The company talked about how it has been using Ethernet for modest-sized AI training and inference clusters and how its near term plans were to scale to systems with 32,000 GPUs sharing data and enabling a factor of 16X improvement in scale over the initial 2,000 GPU clusters it had been using to create and train its LLaMA 1 and LLaMA 2 models. (The Research Super Computer system that Meta Platforms bought from Nvidia topped out at 16,000 GPUs, with most of them being Nvidia’s “Ampere” A100 GPUs with a relatively small share of them being the more recent and more capacious “Hopper” H100 modules.
Meta Platforms knows a thing or two about building datacenter-scale networks, given that its applications serve over 3 billion people on Earth – that’s roughly 40 percent of the population on the planet. But, as the Networking @ Scale presentations showed, scaling AI is a whole lot more troublesome than scaling PHP or Python applications the various middleware, databases, and storage that underpins them to keep us up to date on our social networks. (Can you even tell if the feeds are slightly behind the actual posts on a social application? No, you can’t.)
“AI models are growing 1,000X every two to three years,” explained Rajiv Krishnamurthy, director of software engineering for the Network Infrastructure group at the company. “And we have observed this internally at Meta and I think that seems to be a secular trend based on whatever we are observing in industry too. And that number is difficult to grok. So from a physical perspective, this translates into tens of thousands of GPU cluster sizes, which means that they are generating exaflops of compute. This is backed by exabytes of data storage. And from a networking perspective, you are looking at manipulating about terabits per second of data. The workloads themselves, they are finicky. By that people understand that typical AI HPC workloads have very low latency requirements and also from a packet perspective, they cannot tolerate losses.”
Meta Platforms wants to have production clusters for AI training that scale 2X beyond the Nvidia RSC machine it acquired in January 2022 and ramped up throughout all of last year to its full complement of 16,000 GPUs. And then, before too long, it will be talking about 48,000 GPUs then 64,000 GPUs and so on. . . .
Like other hyperscalers who actually run their own applications at scale, Meta Platforms has to balance the needs of large language models (LLMs) against the needs of recommendation engines (Reco in some of the slides at the Networking @ Scale event) that are also using AI to provide. LLMs need to store models and weights to do inference, but recommendation engines need to store massive amounts of embeddings – usually at least terabytes of data – in memory as well, which us a set of data that has salient characteristics about us and the zillions of objects it is recommending so it can make correlations and therefore recommend the next thing that might be useful or interesting to us.
Architecting a system that can do LLM training (that’s using LLaMA 2 at Meta Platforms at this point) and inference as well as Reco training and inference (in this case, the homegrown Deep Learning Recommendation Model, or DLRM) is very difficult, and one might even say impossible given the divergent requirements of these four workloads, as Jongsoo Park, a research scientist at the AI Systems division of Meta Platforms, showed in this spider graph:
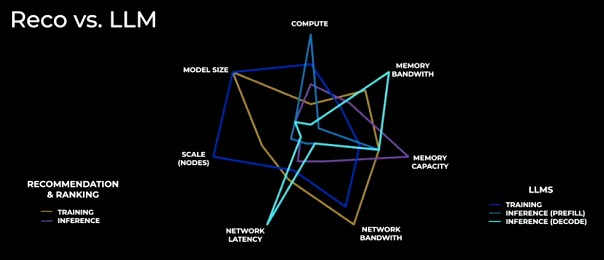
LLMs need “three orders of magnitude more compute” than reco engines, says Park, needing about 1 teraflops of compute for every sentence that is processed and against a datastore of hundreds of billions of sentences and therefore trillions of tokens. This training is distributed across the cluster, but so is the inference, which is now busting out beyond an eight GPU server node to clusters with 16, 24, and even 32 GPUs. Park sized up the compute needs for these four distinct workloads as such:

Imagine, if you will, walking into the office of the CEO and CFO and explaining that you have this wonderful hyperrelational database thingamabob and it could answer questions in plain American, but it needs on the order of 1 petaflops to process one sentence of your corpus of enterprise data and it would need 10 petaflops of oomph to start talking within one second of asking a question. You would be laughed out of the boardroom. But, if you say generative AI, then they will probably come up with the money because everybody thinks they can be a hyperscaler. Or borrow some of their iron and frameworks at the very least.
Love this table that Park showed off:
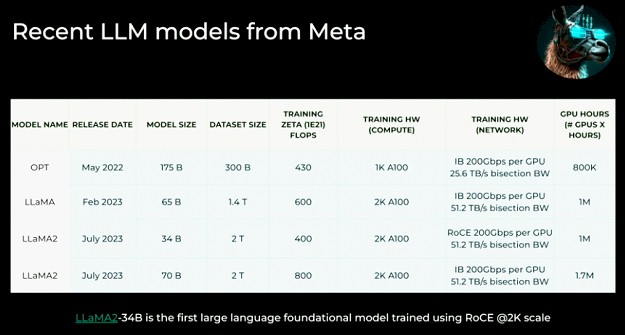
This table shows the interplay of LLaMA model generation, model size (parameter count), dataset size (tokens), aggregate zettaflops needed to complete the training on the hardware shown. Add parameters and you either need more GPUs or more times, and it scales linearly. Add more tokens and you either need more GPUs and more time, and it scales linearly. Scale up parameters and tokens, you need exponentially more GPUs or more time – or both.
Park said that this GPU cluster running LLaMA2 34B with 2,000 A100 GPUs was the largest Ethernet RoCE network in the world as far as he knew, and you can see how if you doubled up the parameter count to LLaMA2 70B, it would probably take 1 million GPU hours to complete against a 2 trillion token dataset – and that InfiniBand is about 15 percent faster at the same 200 Gb/sec port speed used in the clusters.
This is just the beginning. Meta Platforms needs to ramp up its parameter scale, but it can’t do so until it can scale up its back-end AI network and also get its hands on 32,000 of Nvidia’s H100 GPUs. We presume that Meta Platforms has done its penance with Nvidia by touting the RSC system for the past year and a half and will revert to using PCI-Express versions of Hopper and build its own systems from here on out.

With 32,000 H100s yielding about 30 percent of peak performance in production at FP8 quarter precision floating point math, Park says Meta Platforms will be able to train a LLaMA2 model with 65 billion parameters in a day. Lots of things will have to change to make this happen, and this includes increasing the training token batch beyond 2,000 and making that scale across more than a few thousand GPUs. The global training batch size will also have to be maintained across 32,000 GPUs as well, and using what he called 3D parallelism – a combination of data parallel, tensor parallel, and pipeline parallel techniques – to spread the work out across the GPUs. Park says data parallelism is running out of stream because the parameters and data sizes are getting so large, so there is no way to get around this issue.
As for latency, Meta Platforms looks at time to first token and then the average response time for each successive token. The first token should come in under 1 second, which is why it is taking more than eight GPUs to do inference, and then each successive token should come in 50 milliseconds. (An eyeblink is around 200 milliseconds, which is the attention span of a human being since the Internet was commercialized and widely distributed.)
There are subtleties with inference that we were not aware of, and these also have compute and networking needs that are at odds with each other, which is driving system architects to distraction:
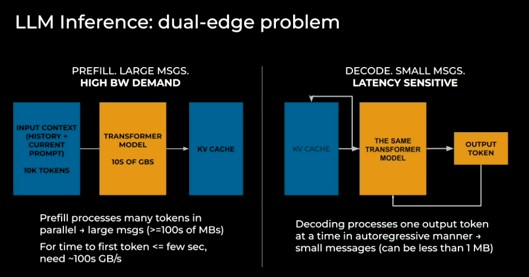
The inference stages are prefill and decode. The prefill stage is about understanding the prompts, which means processing tens of thousands of tokens in a parallel fashion through large messages – on the order of hundreds of megabytes. The time to first token is a few seconds and you need hundreds of GB/sec to feed the prompts into the inference engine. The decode stage is all about latency. One token is output at a time, with each output token being fed back into the transformer model to generate the next token.
Petr Lapukhov drilled down into the AI networks at Meta Platforms a bit more. Lapukhov was a senior network engineer at Microsoft working on LAN and WAN issues for the Bing search engine, has been at Meta Platforms for the past decade as a network engineer, and most recently has been focused on AI systems and their network topologies.
Here is how the Meta Platforms AI systems have evolved over time – and a relatively short period of time at that:
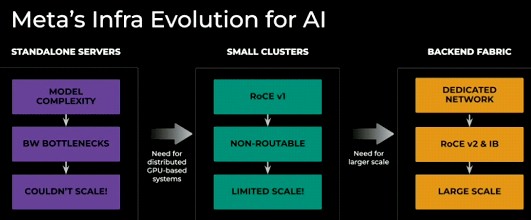
In the old days of only a couple of years ago, DLRM training and inference could be done on a single node. Then, with its first generation of Ethernet RoCE clusters, Meta could cluster multiple nodes together, but the cluster size was fairly limited. To get the kind of scale it needed, it had to move to InfiniBand and Ethernet RoCE v2, and the former had a financial problem and the latter had some technical problems, but the company has made do up until now.
Starting with the basic building blocks, an eight-way GPU server based on Nvidia accelerators can deliver 450 GB/sec of bandwidth across the devices with tens of accelerators inside of a node, according to Lapukhov. Model parallel traffic runs over the in-node interconnect, in this case NVLink but it could also be PCI-Express switching infrastructure. From here, models have to scale with data parallelism across thousands of nodes (with tens of thousands of aggregate GPU compute engines) using some form of RDMA (either InfiniBand or Ethernet RoCE) and you can deliver on the order of 50 GB/sec of bandwidth between the nodes with a reasonable number of network interface cards.
For Ethernet AI networks, Meta Platforms is using the same Clos topology that it uses for its datacenter-scale front end network for applications and not the fat tree tropology generally favored by those using InfiniBand in AI training and HPC clusters.
To get to 32,256 GPUs – the charts from Meta Platforms are imprecise – the company puts two servers in a rack, each with eight Nvidia H100 GPUs. This is not particularly dense, as racks go, but it is no less dense than what Nvidia itself is doing with its DGX H100 clusters. This means there are 2,000 racks that need to be connected, like this:
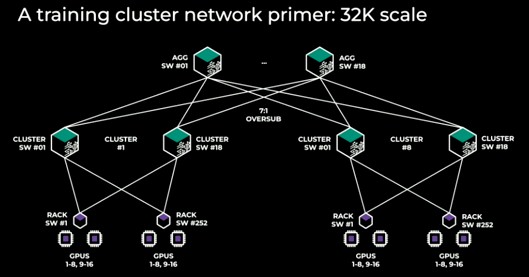
If you look at this carefully, it is really eight clusters of 4,096 GPUs each cross-linked in two tiers of networking.
Each rack has a pair of servers with a total of sixteen GPUs and a top of rack switch. It is not clear how many ports there are in the servers or switches, but there had better be one uplink port per GPU, which means eight ports per server. (This is what Nvidia does with its DGX designs.) There are a total of 2,016 of these TORs in the whole enchilada. That is a fairly large number of switches as networks go.
These top of rack switches are cross connected into a cluster using eighteen cluster switches (what you might call a spine), which works out to 144 switches across the full cluster. And then there are another eighteen aggregation switches with a 7:1 oversubscription taper that link the eight sub-clusters to each other. That’s 2,178 switches to interlink 4,032 nodes. That is a 1.85:1 ratio, thanks to the bandwidth needs of those data hungry GPUs.
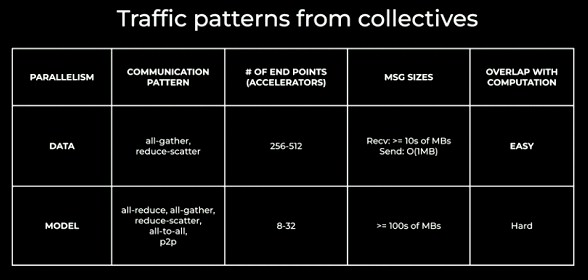
This table by Lapukhov was cool, and it showed that the sub-cluster granularity as far as the AI models were concerned is really on the order of 256 to 512 GPUs:
And this shows how the collective operations that underpin AI are mapped onto the network:
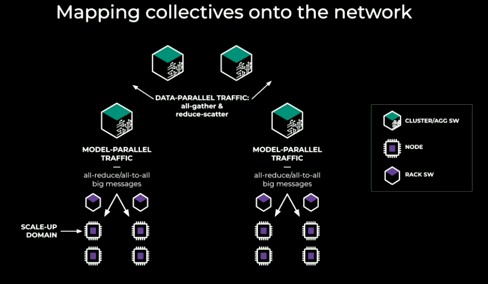
The gist is this, and it is not surprising. As you make larger fabrics to span more GPUs, you add more layers to the network and that means more latency, which will have the effect of lowering the utilization of the GPUs at least some of the time when they are waiting for collective operations to finish being propagated around the cluster. But fully shared data parallel all-gather operations tend to send small messages – usually 1 MB or smaller – and if you can handle small messages well, you can do tensor parallelism with fine-grained overlapping of communication and computation.
Sounds like someone needs big fat NUMA nodes for inference and training. . . . which is exactly what NVLink does and what NVSwitch extends.
So what does this look like in the Meta Platforms datacenters? Well, here is what the front-end datacenter fabric looks like:
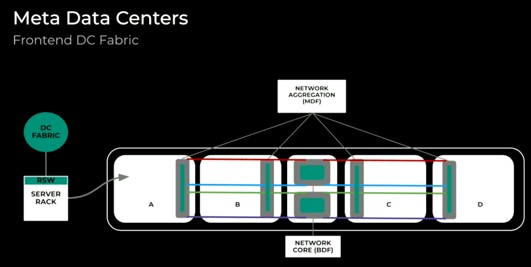
A datacenter us carved up into four rooms, and there is some aggregation networking in each room and then the core network that lashes together the rooms in its own area at the center of the datacenter. To add AI to server rooms, the cluster training switches (CTSW) and rack training switches (RTSW) are added to the same rooms as the other application servers and can be interleaved with application servers. Across four data halls, Meta Platforms can house tens of thousands of reasonably tightly coupled GPUs:
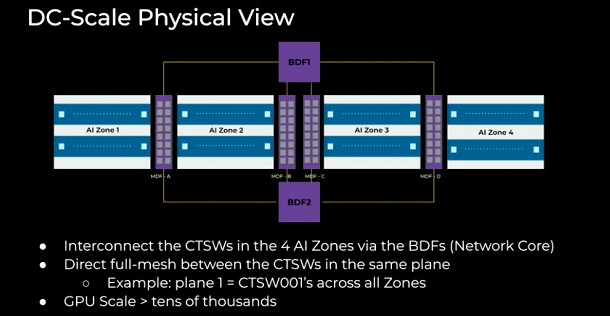
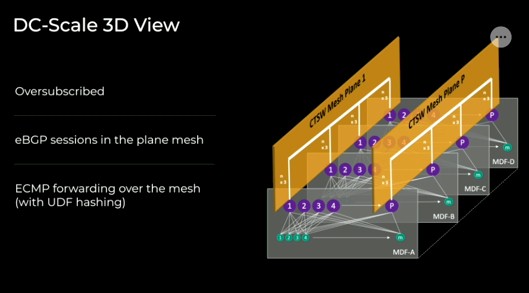
Here is a 3D representation of the network planes if this makes it easier to visualize:
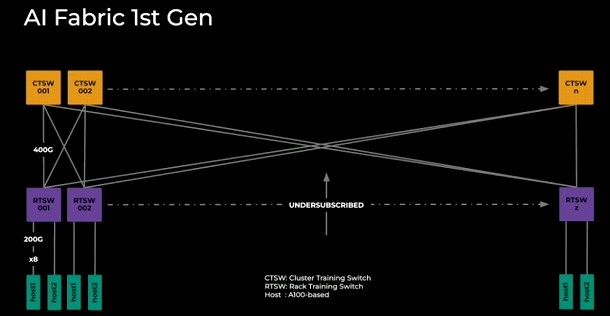
Back in the old days, Meta Platforms was using 100 Gb/sec Ethernet and RoCE v1 with some success:
With the shift to Ethernet RoCE v2, which had much-improved latency and packet protection features, Meta Platforms had eight ports of 200 Gb/sec going into each server (whew!) and cross-coupled these with rack and cluster switches using 400 Gb/sec ports.
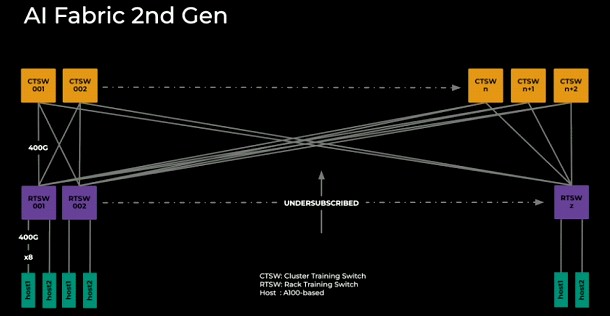
In the second generation of its AI fabric, which is presumably what is helping Arista Networks make so much money from Meta Platforms, the social network has moved to 400 Gb/sec downlinks to the hosts for each GPU and is still running the higher levels of the network undersubscribed to keep the bits moving without any obstructions.
Echoing our “supply win versus design win” observation that has driven a lot of datacenter infrastructure sales since the beginning of the coronavirus pandemic, Lapukhov laid it right out there when asked what is the most important property of an AI fabric.
“So funny enough, the most important property is buildability,” Lapukhov said. “Will you have the materials on time to build your fabric? I know it’s controversial, it’s very unusual to say this thing. But what we found out is that building a large system requires you to get a lot of components on time in one place and test them. So from my perspective, you have Ethernet and InfiniBand as two poles, but they solve the problem in different ways. Ethernet offers you an open ecosystem, multiple vendors, and easier supply sources to get your hardware. InfiniBand offers you the pedigree of technology used in HPC clusters, but there is only one supplier as of today. So the answer is, whatever you can make work on the timescale you need. So for us for longest time, it was Ethernet. We built many fabrics on Ethernet because this is technology we are familiar with good supply and we have had devices to deploy on time. And that took precedence. We have been building clusters with InfiniBand as far back as three years ago. So as of today, we have allow our technologists to deploy both InfiniBand and Ethernet. And once again, I’ll reiterate the most important property is building the fabric you can build on time for your GPUs to arrive and use in the datacenter.”
Exactly. And it will be like this for many more years to come, we think. But if the Ultra Ethernet Consortium has it Meta Platforms’ way, Ethernet will be a lot more like InfiniBand and will have multiple suppliers, thus giving all hyperscalers and cloud builders – and ultimately you – more options and more competitive pressure to reduce prices on networking. Don’t expect it to get much below 10 percent of the cost of a cluster, though – not as long as GPUs stay costly. And ironically, as the cost of GPUs falls, the share of the cluster cost that comes from networking will rise, putting even more pressure on InfiniBand.
It is a very good thing for Nvidia right now that it has such high performance GPUs and higher performance InfiniBand networking. Make hay while that AI sun is shining.




Interesting piece! It brings perspective on the need for, and reasoning behind, wanting composable disaggregated heterogeneous computational systems, linked by interesting switches (eg. Enfabrica Godbox). As illustrated here, when systems grow to accomodate bigger workloads, previous-gen hardware can remain valuable as long as it can be integrated (or composed into) an upgraded system with pods of latest-gen machinery (say A100 and H100, or MI210 and MI300x, or even tutti-frutti) — rather than having the new system being a complete overhaul of uniformly new-gen chippery, and the old system being landfilled.
Composability should also help large disaggregated heterogeneous systems better meet the contrasting needs of LLMs vs DLRMs, training vs inference, and prefill vs decode phases. Slicing through the composable system in different ways to accomate those different processes, at different times. A great job opportunity for IaC tools, or just convincing shoulder shakin’!
InfiniBand is the frog that gets a kiss from Nvidia
Ah, but did it turn into a prince? HA!