

As long as great science gets done on the final incarnation of the “Aurora” supercomputer at Argonne National Laboratory, based on Intel’s CPUs and GPUs but not on its now defunct Omni-Path interconnect, people will eventually forget all of – well, most of – the grief that it took to get the massive machine to market.
And while they will be sanguine about all of the science that didn’t get done on the original Aurora machine, announced in April 2015 and slated for delivery at the end of 2018, or on the much-delayed current one based on CPUs and GPUs, because scientists are forward looking and will immediately set about doing the simulation and modeling work they have been itching to do.
It doesn’t hurt that instead of getting a 180 petaflops machine using 50,000 “Knights Hill” Xeon Phi many-core CPUs (many for the time, mind you) with the possibility of expanding that out to 450 petaflops with a stunning 125,000 nodes for $200 million, Argonne got a $500 million deal to get a machine slated to break the exascale barrier – and in 2021, after delays, Intel Federal, the part of the chip maker that was the prime contractor on the Aurora contract, took a $300 million writeoff that Intel has danced around in explaining, so Argonne might be getting the new and much improved machine for the original $200 million when all is said and done.

It doesn’t hurt that the final Aurora architecture suits the time better than the original one did, and looks a whole lot more like a modern AI training system than the IBM BlueGene/Q machine that was long used by Argonne and that was the inspiration for the original design. Al Gara was the architect at IBM for the BlueGene processors and the torus interconnect for linking together lots of modestly powered nodes, and he was the chief architect of the Knights CPU and coprocessor designs, too. So the resemblance was not coincidental.
Intel launched its HPC efforts in the mid-2010s with the idea of creating an X86 and InfiniBand, commodity style supercomputing infrastructure that embodied many of the ideas of BlueGene, which in and of itself was not at all a stupid idea for traditional HPC simulation and modeling workloads.

But then AI came along in 2012, and totally changed the HPC landscape, forcing Argonne to question the architecture and Intel to change the Aurora design. The GPU-accelerated machines that were going into Oak Ridge National Laboratory and Lawrence Livermore National Laboratory – the 200 petaflops “Summit” machine and the 125 petaflops “Sierra” machine, respectively – were based on a hybrid CPU-GPU architecture and could, to a certain extent, pivot to AI training as well as running accelerated HPC workloads.
Here is the kicker. When that last delay with the “Ponte Vecchio” Max Series GPU happened in October 2021, the plan was to have more than 9,000 nodes with a pair of “Sapphire Rapids” Xeon SPs – we didn’t know they would have HBM2e memory at the time – and six Ponte Vecchio CPUs rated at 45 teraflops at double precision floating point.

As it turns out, that peak theoretical number for a single Ponte Vecchio GPU was raised by 15.6 percent in 2022, to 52 teraflops at both FP32 and FP64. And knowing what we know today about the GPU counts, it would be easy to jump to a conclusion and multiply 52 teraflops – shown in the Max Series GPU chart in the Intel ISC presentation – by 63,744 GPUs in 10,624 nodes – the numbers shown in the specifications for the Aurora machine – and get 3.31 exaflops of aggregate peak theoretical compute for the Aurora 2023 machine. That would be a very big number indeed, and very exciting given that all Intel has said is Aurora would have “in excess of 2 exaflops of peak theoretical DP performance” thus far.
And as it turns out, that is not a correct conclusion to jump to. We had a hunch it wasn’t. Intel confirmed with us what the speed of the Ponte Vecchio GPU used in Aurora was.
What Argonne is actually getting is a Ponte Vecchio GPU rated at 31.5 teraflops, which is 61 percent of the peak performance of a standalone GPU, which means Aurora is only delivering just a hair over 2 exaflops of peak double precision floating point oomph. Intel has been clearly adding node counts to get above that 2 exaflops peak, and is not going to be adding one node more.
Assuming that somewhere between 65 percent and 70 percent of the flops can be utilized running the High Performance Linpack benchmark test – a lot depends on how the Slingshot Ethernet interconnect from Hewlett Packard Enterprise (which replaced Omni-Path 200 in the design) scales across more than 10,000 nodes – then Aurora should be at the top of the Top500 in November this year with a sustained performance of between 1.31 exaflops and 1.41 exaflops sustained on Linpack.

Paying a net $200 million for a 2 exaflops machine, if this is indeed what happened, is one hell of a deal. In fact, there never was an HPC system deal like this and, heaven willing, there never will be such a one again. And even if Argonne paid $500 million for a 2 exaflops peak machine, that is on par with what Lawrence Livermore is paying for El Capitan.
From our point of view, if this is again indeed what happened with Aurora with that $300 million writeoff, Intel has justly compensated Argonne for its grief and perhaps Rick Stevens, associate laboratory director for computing, environment, and life sciences, will smile when he stands in front of the running system, which he did not when standing in the rows of the Aurora machine or in front of the racks in this profile that appeared in Chicago magazine back in January 2023. Smile, Rick. It’s almost over, Argonne has done what it is supposed to do, which is to blaze new trails of compute and make sure there are alternative suppliers, and now the science can start.
The Feeds And Speeds
The original Aurora 2018 machine had Cray as a subcontractor for its “Shasta” Cray XE system designs, was slated to have a mix of HBM, DDR, and Optane weighing in at more than 7 PB across the 180 petaflops machine, with more than 30 PB/sec of aggregate memory bandwidth. The Omni-Path interconnect was supposed to employ silicon photonics on the switches and deliver an aggregate of more than 2.5 PB/sec of aggregate node link bandwidth (that is bytes, not bits) and more than 500 TB/sec of bi-section bandwidth. The design had a burst buffer based on Intel flash drives, and a Lustre file system from Intel on a set of disks with more than 150 PB of capacity and more than 1 TB/sec of throughput.
The specs of the Aurora 2023 machine were released by Jeff McVeigh, general manager of the Super Compute Group, in a prebriefing ahead of the ISC 2023 supercomputing conference, which is happening in Hamburg, Germany this week:
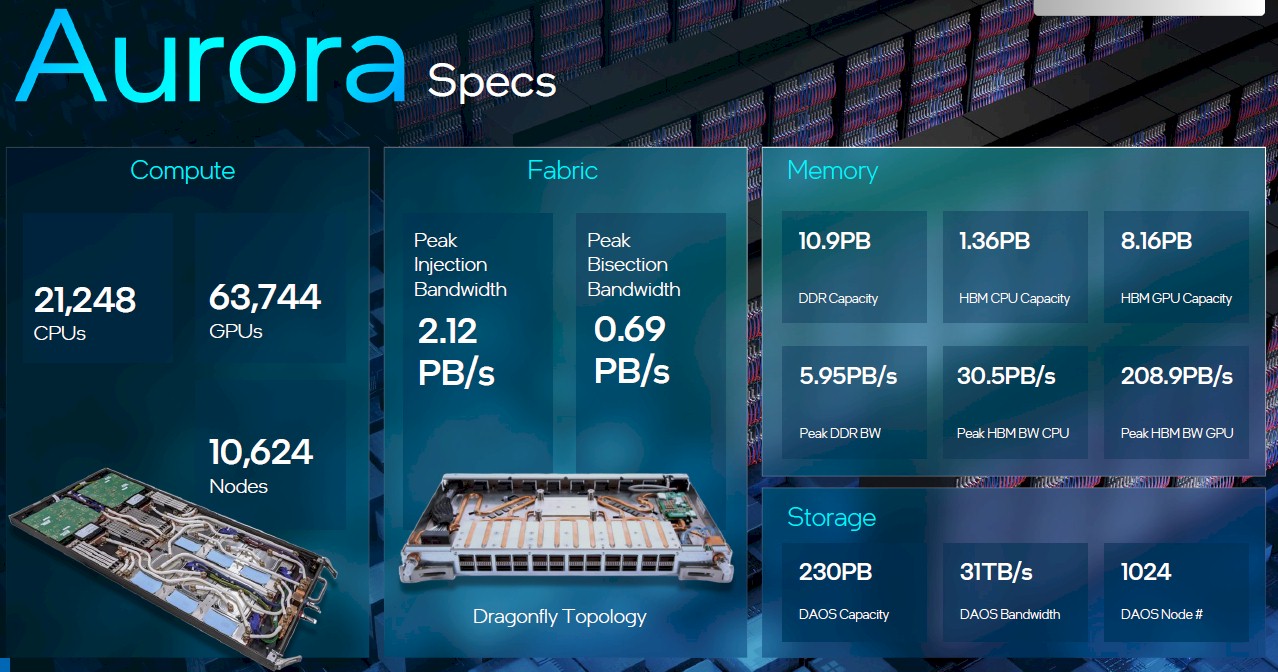
That is the Aurora 2 x 6 node in the lower left, and the HPE 200 Gb/sec Slingshot switch, based on the “Rosetta” ASIC, right next to it. Intel has delivered all of the blades, but it is not clear if all of the CPUs and GPUs are on them as yet since it did not say the machine was fully manufactured.
“We are very pleased to announce we have delivered over 10,000 blades,” McVeigh said on the conference call. “We have much more work to do for full optimization, delivering on the codes, and acceptance. But this is a critical milestone that we’re very, very happy to have accomplished.”
At 2,007 petaflops (rounding up to 2.01 exaflops), the Aurora 2023 machine is 11.2X more powerful than the Aurora 2018 machine would have been, which is, by the way, two times faster than Moore’s Law at a two-year doubling would provide over that same time. The combined memory capacity across the CPUs and GPUs in Aurora 2023 is 20.4 PB, which is 2.9X that of the original machine, and the aggregate memory bandwidth at 245.4 PB/sec is 8.2X higher. At 2.18 PB/sec of injection bandwidth, the Cray network is about 15 percent lower than was expected with the Omni-Path 200 network at 2.5 PB/sec (and across a much larger machine, mind you), and the bi-section bandwidth was about 38 percent higher at 0.69 PB/sec. As for storage, Aurora has 1,024 nodes running the DAOS file system, which has 230 PB of capacity and 31 TB/sec of bandwidth. That’s 53 percent more capacity, but around 30X the bandwidth on the file system for the Aurora 2023 machine.
On the briefing, McVeigh said that Intel and Argonne were working with the technical community to create AuroraGPT, which is a generative large language model that has been pumped full of corpus of scientific data. McVeigh also showed a bunch of benchmarks for Ponte Vecchio GPUs, but given how far the Aurora GPUs are scaled back – no doubt for thermal reasons – we are not sure if these numbers are all that valuable when it comes to Aurora. But this one running the OpenMC Monte Carlo simulation on Aurora testbed machines against other testbed machines using AMD Instinct MI250X and Nvidia A100 GPUs might be useful:
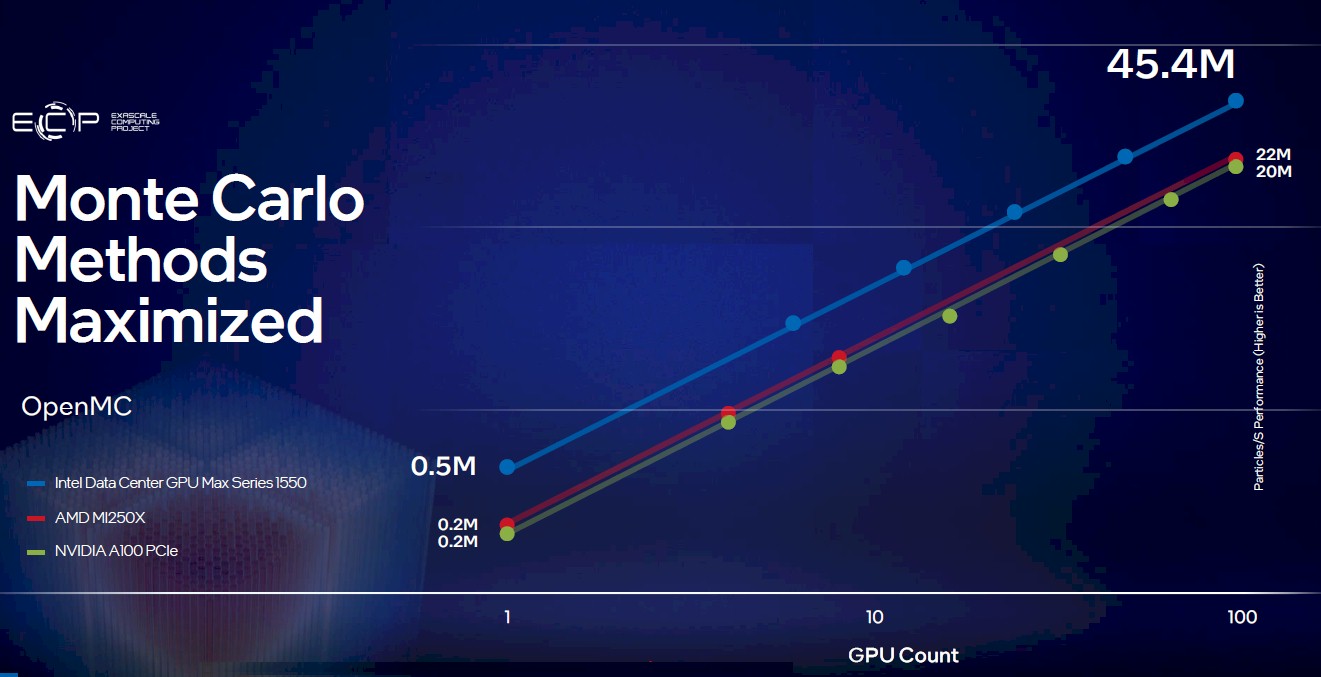
We need to know more about this OpenMC test to see how the Aurora nodes will compare to current Nvidia “Hopper” H100 GPUs and future AMD Instinct MI300A CPU-GPU hybrids.




25% of the blades do not contain the final revision of the Sapphire Rapids silicon (as reported here: https://www.tomshardware.com/news/intel-delivers-10000-aurora-supercomputer-blades-benchmarks-against-nvidia-and-amd).
With a 2 exaflop system it will be interesting to know what percentage of cycles are consumed by capability class jobs that, for example, parallelize to more than 10 percent of Aurora’s total capacity during a run.
Hopefully the final effect is not too many nodes with too many uncorrectable ECC faults and a slow network.
Well, Intel sure had a lot of ‘splainin to do for being such a pants-down no-show at the June List partyxtravaganza and mega-battle-royale, all the way from the beer-garden capital of the world, where three liters of the good stuff are considered a proper meal, Munich … oh wait …! This prebriefing by McVeigh puts things in perspective to be sure … a better machine, 8 years in the making, at lower cost …
Still, with Aurora tied-up, lacing-in the back of its wedding dress, couldn’t they have sent Sunspot to the ring, as a stand-in replacement, for pre-rehearsal purposes of exhibition, a presence of evidence if you will? At 1/100th the size of Aurora, with the very same configuration, it should still punch 20 PF/s, placing it at #40 in HPL in this very June’s List, if only to reassure bookies.
Maybe it’s that fine-tuned software libraries issue, rearing its ugly street-urchin head again, to remind all contemporary programmers that just because compilers exist, for your unlikely language of choice, doesn’t mean you’ll get any decent performance from your specific hardware, when running the resulting binary on it, unless your libraries are indeed particularly well-tuned to it. Acne, shmacne, but if I had to bet, say 10-to-1, I’d say the libraries (their tuning) are the current hold-up (and hopefully the last).
Having worked on the successful but ill-fated Blue Waters proposal, the performance promised is impressive. But the price is stunning!
>>What Argonne is actually getting is a Ponte Vecchio GPU rated at 31.5 teraflops, which is 61 percent of the peak performance of a standalone GPU<<
. . . and now it's clear why the big red reset button on the GPU group was punched.
Pretty right. But as long as your skunkworks engineering team gave you “effort beyond”, it would be tech suicide to lay them off, and so I think that this “big red reset button” is mostly a “pause actuator” here. Given where Intel was on this 5 years ago, the progress is very impressive! — even if it does not yet match the competition, it is now very close…
“Smile, Rick. It’s almost over…”
Love your writing, Timothy.