

Sponsored Feature: With each new successive generation of Intel Xeon Scalable processors, more and more of the workloads that might be otherwise offloaded to discrete accelerators or SmartNICs have been pulled back onto the processor socket – and often in a way that does not burden the CPU cores with running routines and algorithms implemented in software.
Rather, a modern Intel Xeon Scalable processor – namely, the 4th generation family of chips – has a variety of accelerators offering enough oomph to turn itself into a general purpose processor for the modern era in terms of core compute, networking, and storage workloads.
There are many different kinds of acceleration available with the 4th Gen Intel Xeon Scalable processors. So a definition is probably in order to begin so we are all on the same page. Accelerators are hard-coded blocks of transistors located either on vector or matrix units in the CPU cores or in the non-core areas of the CPU socket. They run algorithms and routines much faster than CPU cores that use software to run those same algorithms and routines.
By offloading to accelerators, of which there are many in the new architecture, those CPU cores are left with extra capacity to do more work. The synergistic effect between the cores and the accelerators is that the applications can run faster overall than they would if the accelerators were not present.
In an interesting aside, customers buying 4th Gen Intel Xeon Scalable processors can also choose between fat and reasonably fast DDR5 memory, or skinny but extremely zippy HBM2e stacked memory – or mix the two as required for particular applications. So in a sense, even the memory is an accelerated option, given that HBM2e memory can provide anywhere from a 3.8X to 5.3X performance improvement for bandwidth-sensitive HPC applications compared to the DDR5 option.
In this article, we are going to zero in on three areas where the new chips provide important acceleration: artificial intelligence, data analytics, and networking. That’s not to say there aren’t other important areas where in-socket acceleration can be brought to bear – there are, and we discussed these in a previous article in this series.
Artificial Intelligence Acceleration
There’s a misconception that all that AI training takes is a massive amount of systolic flops. That’s not the case – there are many different kinds of AI models and they require very different things, as this chart below shows:
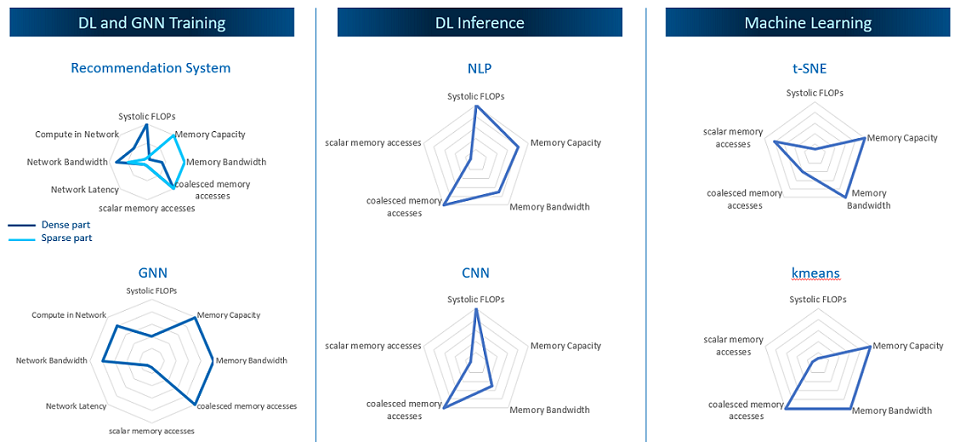
But the situation is actually more complex than this chart implies. AI workloads are comprised of pipelines that span data preparation and model training for both classical machine learning (statistical techniques that are decades old and that have long-since been optimized to run well on the X86 architecture) and deep learning (for which X86 servers with the right kind of vector and matrix units can run small and medium models as well as do transfer learning from pretrained models).
And then, of course, the pipeline includes running inference on something. And at this point in history, after a decade of machine learning on GPUs and custom ASICs, Intel market modeling suggests 70 percent of inferencing in the datacenter is still running on Intel Xeon processors.
That inferencing requirement is helped by the Intel Advanced Matrix Extensions (Intel AMX) included in the latest Intel Xeon Scalable processors, which compared to previous generations can achieve up to 10x higher PyTorch real-time inference and training performance (you can access Intel’s performance metrics here, results may vary depending on configuration).
And for a lot of companies that Intel AMX acceleration, combined with the Intel AVX-512 vector capabilities that also come with the 4th Gen Intel Xeon Scalable processors, will be sufficient for running the data preparation, modeling, and production inference workloads – all on a single kind of server that can also be employed for supporting other kinds of less demanding enterprise workloads.
There’s no question that training an AI model from scratch is one of the most compute intensive activities in the history of computing. And that it often takes GPUs or other kinds of custom ASICs with massive amounts of parallel processing engines with mixed precision on data formats to do it efficiently. But not every end user organization is going to train an AI model from scratch. In many cases, customers are just going to adapt a pre-existing, trained AI model to work with their own adjunct data in order to add AI processing to their applications.
In this case, companies will tweak the model to incorporate sentiment analysis or employ whatever lexicon is specific to their industry or particular business. That will require a lot of compute to be sure, but not the significant number of GPU (or GPU-hours) and large amount of money spent on GPUs (if in the cloud) that the initial training of a foundation model would otherwise require. It will in fact be possible to perform this adjunct work on standard 4th Gen Intel Xeon Scalable processors – the kind that customers are expecting to deploy to run their applications anyway – on a single node without requiring additional processing resources.
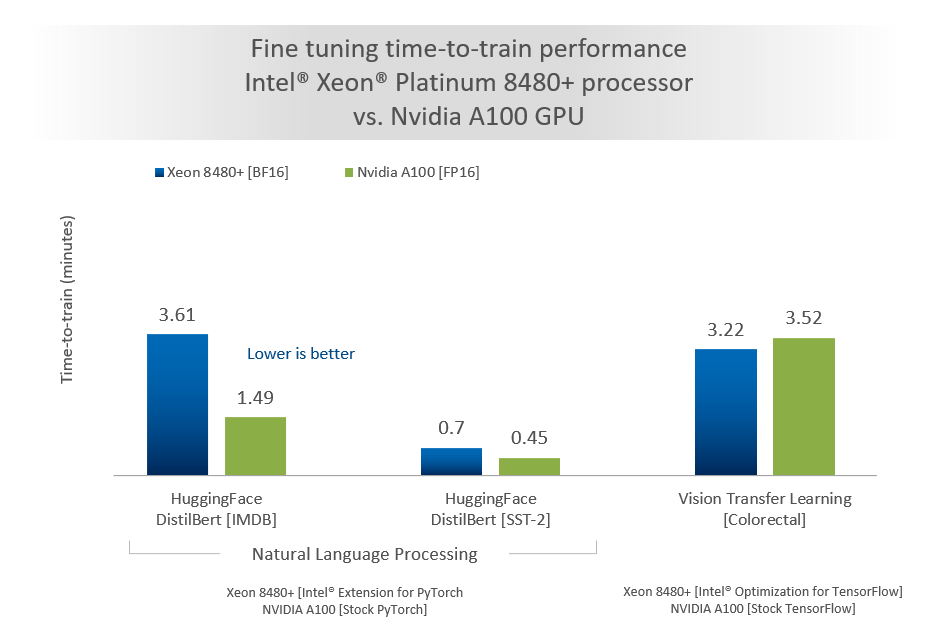
And in the case of Hugging Face DistilBert and Vision workloads, some of the new Intel Xeon processors can fine tune time-to-train performance in less than four minutes on a single node. So while Nvidia’s A100 CPU may be faster, the Intel Xeon processor gets back to the point of meeting customer service level agreements (SLAs) without the need for additional hardware as shown in the chart below (results may vary according to specific configuration).
Database And Analytics Acceleration
It doesn’t matter whether it is traditional relational databases like SAP HANA or more modern in-memory analytics platforms like Spark or Redis. The use of accelerators on the 4th Gen Intel Xeon Scalable server processors boost portions of the workload such as compression and decompression, CRC security checks, along with analytics primitives like scan and filter. By doing this, they take much work off the CPU cores and allow them to spend more time running the actual queries along with other database functions.
This synergy between the accelerators – the important ones for analytics are Intel In-memory Analytics Accelerator (Intel IAA), Intel Data Streaming Accelerator (Intel DSA), Intel Advanced Vector Extensions (Intel AVX-512), and Intel QuickAssist Technology (Intel QAT) – and the cores means databases and analytic applications run considerably faster.
How much faster? If you take the open source RocksDB database engine and run it on the “Ice Lake” Xeon SP-8380 Platinum processor, which has 40 cores running at 2.3 GHz, and compare it to a Xeon SP-8490H Platinum processor, which has 60 cores running at 1.9 GHz, it will run 2.94X faster (results may vary). That’s despite the combination of cores, clock speed, and relative instructions per clock (IPC) leading you to believe that RocksDB should only run 42.5 percent faster (bear in mind that the average IPC on the “Golden Cove” cores used in the 4th Gen Intel Xeon Scalable processors is 15 percent higher than the “Sunny Cove” cores used in the Ice Lake CPUs). A lot of this performance increase comes from the Intel IAA accelerator, but not all of it.
This additional latency reduction is driven largely by the Intel Data Streaming Accelerator, which moves data into and out of main memory as the database is running. And it’s not at all surprising that latencies for transactions running on RocksDB also decreases by 66 percent (results may vary).
Testing is still not complete, but it is expected that other relational databases – and specifically SQL Server – will show similar kinds of performance boosts thanks to these accelerator engines once Microsoft optimizes the SQL Server code to take full advantage of the 4th Gen Intel Xeon Scalable processors’ capabilities.
Networking Acceleration
On the networking front, the big change with the new chips is the ability to accelerate the signal processing in Layer 1 of the network stack for 5G base stations running the vRAN software stack. By moving from Ice Lake to 4th Gen Intel Xeon Scalable processors, regarding this vRAN processing – which involves converting digital data to radio signals and vice versa – Intel can demonstrate a 2X performance increase in the same power envelope using the Intel Advanced Vector Extensions (Intel AVX) for vRAN (see more performance metrics here, results may vary).
This is an important metric because GSMA Intelligence estimates that mobile base stations account for 73 percent of the power consumed in telco networks. And as mobile network capacity and subscribers increase, base station workload performance requirements increase in parallel, meaning smart, targeted acceleration may be necessary for telcos to save power without sacrificing network performance. Intel Advanced Vector Extensions (Intel AVX) for vRAN enable optimized, virtualized base stations, while the channel error correction acceleration integrated in 4th Gen Intel Xeon Scalable processors with Intel vRAN Boost is estimated to further reduce power by 20 percent (results may vary).
The Intel® Data Direct I/O (Intel DDIO) accelerator, which dates back to the initial “Skylake” Xeon E5 and E7 processors, has continued to evolve with the latest generation of Xeon chips. In addition, the software-based Vector Packet Processing (VPP) router delivers 2.1X more throughput running on 4th Gen Intel Xeon Scalable processors compared to Ice Lake, and 4.1X more performance per unit of memory bandwidth because of the way DDIO streamlines the movement of data from I/O interfaces through the cache hierarchy to the cores without messing about in DRAM memory (results may vary).
There are many, many more examples of how these accelerators boost performance and performance per dollar as well as performance per watt. Two important ones include Intel QAT which accelerates cryptographic ciphers, public key exchange and high performance verified compression/decompression, and Intel Dynamic Load Balancer (Intel DLB), which reduces the latency of work distribution and provides priority queuing for flow management and network policing. DLB provides a further boost to packet processing performance on the 4th Gen Intel Xeon Scalable chips compared to the previous generation Ice Lake processor, and can distribute flow management across multiple CPU cores as system load fluctuates.
You can learn more about the newest 4th Gen Intel Xeon Scalable processor product family by clicking this link.
Sponsored by Intel.
Intel Legal Notices and Disclaimers

Thank you for leaving the comments open on this and other sponsored articles. Though results may vary, I’m quite excited about all the possibilities these accelerators open up for getting around Moors Law. At the same time, developing traditional CPU-based software is already difficulty enough. What are the developer resources like for actually using these hardware accelerators? Will there be any non-production hardware platforms available for open-source developers to inexpensively explore possibilities?
For example, Nvidia generated lots of development activity for GPUs by allowing CUDA to run on consumer-class Titan graphics cards and AMD did the same for ROCm with cards such as the Radeon V. In my opinion, an affordable desktop CPU with all the accelerators turned on would greatly help Intel with regards to software-developer interest and productivity.