

Sponsored Feature: In an ideal world, if you knew exactly and precisely what application you are going to run, then co-designing a custom application and its processor would be a fairly simple matter and price/performance and performance per watt would always be as perfect as it could be.
But we don’t live in that sort of world.
It’s not economically possible for each application to have its own processor. Most enterprises run hundreds to thousands of distinct applications. At the same time they need to buy as few different kinds of CPUs and the systems that wrap around them as is practical – and yet still deliver some degree of optimized value per dollar and per watt expended.
Because of this, we will always have a hierarchy of compute, moving from general-purpose to custom and moving out from the core to the socket and across a high-speed bus. And in many cases, varying degrees and amounts of application acceleration – a very special kind of processing for specific portions of applications – will move from the outside of the CPU into the socket and back into embedded processor cores. Or, move out from the cores to discrete accelerators, or co-exist in some fashion in many different layers of compute.
So it is with the newly launched 4th Gen Intel® Xeon® Scalable processors. This is the most powerful and high-speed compute engine that Intel has ever delivered.
The new CPUs have a hierarchy of acceleration that not only reflects the state of compute in the datacenter at this point in time, but that is positioned to provide a balance of performance and optimal total cost of ownership (TCO) for applications that are not yet mainstream, but are moving rapidly in that direction.
There are times when discrete accelerators outside of the CPU are going to be used, but now in a lot of cases, such acceleration can be done on the CPU itself. Take artificial intelligence (AI) as an example. Intel sells its Habana discrete accelerators – the “Goya” line for AI inference and the “Gaudi” line for AI training.
These are very precise devices for very specific applications, aimed at large-scale AI infrastructure where the best bang for the buck and the lowest energy consumption is paramount. For organizations that need to accelerate various kinds of AI and HPC applications on the same infrastructure and at large scale, Intel is bringing the Intel® Data Center GPU Max Series, codenamed “Ponte Vecchio”, to market, which operates cooperatively with its Sapphire Rapids CPUs. But for many HPC and AI applications, the Sapphire Rapids CPU will be able to do the math without having to change code substantially by moving to an offload model.
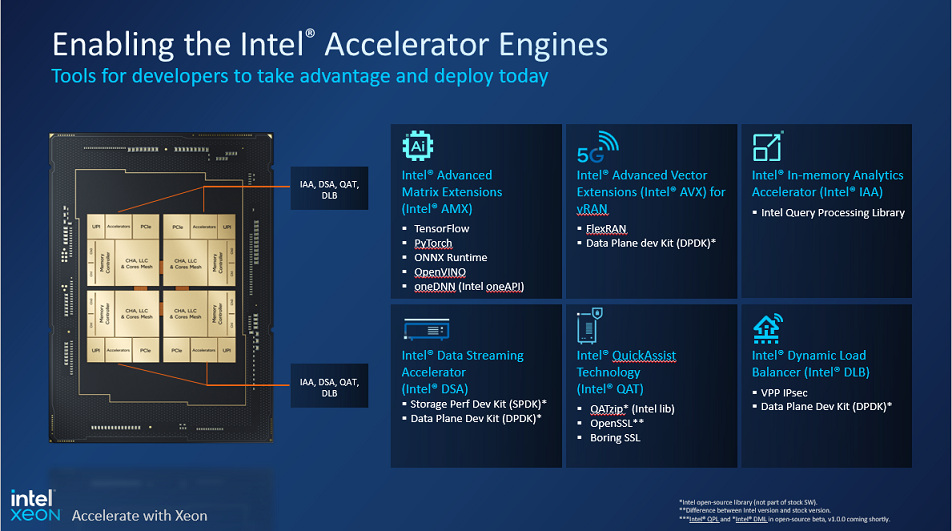
The Sapphire Rapids processing complex has all kinds of acceleration technology both integrated into each embedded core and also in adjacent accelerator engines. In the chart below, we highlight the newest and most significant accelerators on Sapphire Rapids, along with the tools that allow developers to take advantage of them for critical workloads.
These are equally as good for those applications that need a different ratio of vector or matrix math compute to raw, general-purpose compute on the CPU cores, or for organizations looking for math acceleration to be closer the CPU cores because of latency requirements. Customers that need other kinds of acceleration for networking, compression, data analytics or encryption, or those who are just not sure yet how much acceleration they need, can also benefit.
Newest Accelerators on 4th Gen Intel Xeon Processors
As an example, AI is important to all enterprises large and small, and regardless of industry or geography. The prior three generations of Xeon Scalable processors – the “Cascade Lake” CPU, the “Cooper Lake” CPU, and the “Ice Lake” CPU – supported varying degrees of lower precision floating point and integer processing on the AVX-512 vector math units on each of their cores to support that AI requirement.
Cascade Lake introduced INT8 8-bit integer data formats and Cooper Lake added 16-bit floating point BF16 data formats aimed at AI inference, for example. But AI inference and tuning, and retraining of existing AI models, has become so important and pervasive in the datacenter that the 4th Gen Intel Xeon Scalable processors have gone one step further. In the latest generation of chips a whole new matrix math unit, called Intel® Advanced Matrix Extensions(Intel® AMX), is being added to the cores and the Intel Xeon Scalable processor instruction set.
The benefit of the Intel® AVX-512 and now the Intel AMX units, and indeed a slew of other accelerators that are part of the CPU core instruction set, is that they are programmed like any other part of the Intel Xeon Scalable processor core or package. As such, they do their processing within the confines of the processor socket and therefore do not have a more complex governance or security profiles like the discrete processors accessed on the PCI-Express bus or out across the network.
The important thing with this accelerator architecture is that Intel has not just taken a chunk of an external, discrete accelerator and plunked it down onto the CPU core or onto the server CPU package. The compilers know how to dispatch work to them, and libraries and algorithms from Intel and others will be tweaked to make use of Intel AVX-512, and now Intel AMX, as appropriate.
The Windows Server and Linux operating systems require code tweaks to support these accelerators and any new functions that come with Sapphire Rapids. Any middleware and third party application software will also need to be tweaked to make best use of those acceleration capabilities. But the good news for a lot of customers is that most of these capabilities will be available out-of-the-box with no heavy lifting required by developers and/or system integrators. Even those who write their own code will be able to take advantage of this acceleration just by recompiling it.
Intel and its software ecosystem partners do a lot of work to make this as seamless and as invisible as possible. Most importantly, the CPU core cycles that are freed up from these accelerators, allowing them to do more general purpose work, more than offset the cost of moving routines to the accelerators. And they do not have to go all the way to an off-chip accelerator to get the benefits of acceleration, which can be more complex to program (although the Intel® oneAPI development environment effort is trying to fix this problem, too).
The important thing is that the collection of accelerators on the Sapphire Rapids chips – be they Intel AVX-512 and Intel AMX on the cores or the adjacent Intel® In-Memory Analytics Accelerator (Intel® IAA), Intel® Data Streaming Accelerator (Intel® DSA), and Intel® QuickAssist Technology (Intel® QAT) on the CPU package – is that they don’t take up very much space, relatively speaking.
And they provide tremendous performance and performance per watt benefits for selected – and important – libraries and algorithms and therefore for specific applications. The benefits are substantial, as illustrated below:
Intel accelerator performance
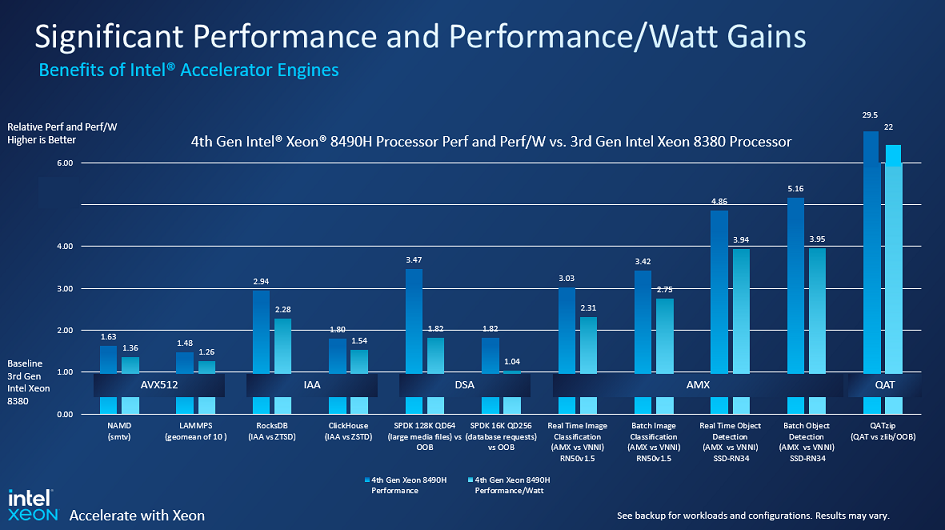

The charts above shows the performance and performance per watt advantages of the 4th Gen Intel Xeon Scalable processors compared to their 3rd Gen Ice Lake predecessors on a variety of application codes where certain functions are being accelerated and, importantly, are not being done in raw software on the general purpose cores. The performance and efficiency gains for the Intel AMX matrix unit and the Intel QAT encryption and compression accelerator are particularly high between these two generations of processors.
The trick with good on-CPU accelerators is that they offer enough flexibility and agility to be generally helpful for a lot of applications across a lot of customers. And routines can run on both the accelerators and on the CPUs as needed. So when additional encryption performance is required for example, CPUs can be utilized in addition to the accelerators – it’s not a case of one or the other. It’s not even a matter of paying for features on an Intel Xeon Scalable processor CPU even if you might not need them.
Perhaps more importantly is that because Intel knows that CPUs are going to be in server fleets for many years, it has created the Intel OnDemand activation model that allows for the off-core accelerators – Intel® Dynamic Load Balancer (Intel® DLB), Intel QAT, Intel DSA, Intel IAA etc – to be shipped in SKUs in a latent form and activated in the field as they become necessary for a supplemental fee.
There are already a wide variety of these SKUs in the Sapphire Rapids stack which allow for customers to pick and choose the core counts and accelerator features that best fit their needs – buyers don’t have to just count cores and clocks and hope it all works out. As such, the Intel OnDemand model is likely to prove very popular in the enterprise because of the flexibility it allows and the acceleration it affords – and we think other CPU makers will have to follow suit with the same type of flexibility and innovation.
You can learn more about the latest 4th Gen Intel Xeon Scalable processors by clicking here.
Sponsored by Intel.
https://www.intel.com/LegalNoticesAndDisclaimers

Do you know if Intel has exposed utilization metrics for the accelerators? How will I know if my app is consuming the accelerators or not (assuming there is no monitoring)?
I think some have active accelerators and some don’t, and then it is all down to software. If the software is tweaked to use an accelerator, it does, and if not, algorithms are run in software on the CPUs. That’s the idea anyway, as Intel has explained it to me.