
The industry is impatient for disaggregated and shared memory for a lot of reasons, and many system architects don’t want to wait until PCI-Express 6.0 or 7.0 transports are in the field and the CXL 3.0 and beyond protocols that ride on it to reach out to external memory have been tweaked to do proper sharing across servers.
Recently, we detailed what one startup was working on to help bridge that CXL memory gap by mashing up a combination of Gen-Z transports and protocols with CXL at the endpoints of servers and memory devices. Now, we have another on that is using a mix of OpenCAPI and a PCI-Express 5.0 switch that is coming out from a new vendor plus the CXL protocol on servers to create sharable extended memory that will range up to 16 TB on a single memory appliance.
That company, called TORmem, which is short for top-of-rack memory, was founded in March 2021 by Thao Nguyen, who is the company’s chief executive officer, and Steven White, who is chief technology officer.
Nguyen got his bachelors in electrical engineering at the University of Missouri and his masters at Syracuse University, and did a number of logic design and product development jobs for IBM before joining the technical staff at NetApp’s compute and storage engineering division. Things got really interesting for Nguyen when he joined Facebook and was director of Open Compute compliance and interoperability at the social network, where was put in charge of managing the manufacturing and deployment of millions of servers for Facebook based on Open Compute Project standards. He left Facebook to become vice president of hardware engineering and distinguished hardware engineer at the hosting company Packet, and moved over to Equinix as Principal of hardware engineering after Equinix acquired Packet in January 2020 for $335 million.
While both Facebook, Packet, and Equinix all deal with stranded server memory, Nguyen was watching the evolution of OpenCAPI, CXL, and other memory sharing technologies as well as the steady bandwidth increases of the PCI-Express interconnect, and a little more than a year ago decided to build a family of memory appliances based on CXL on the front end and OpenCAPI on the backend with a PCI-Express switching complex bringing them together to create an appliance that can both pool memory like a SAN does disk or flash storage as well as share memory – meaning multiple servers can literally access the same physical memory over the PCI-Express fabric so data does not have to be moved.
The nitty-gritty of making all of these things work together falls on White, who got his bachelors in electrical engineering from West Virginia University back in 1999, when the dot-com boom was roaring and White could set up his own shop to help companies prototype and test all kinds of gear.
In the summer of 2011, when Chris Kemp, the former NASA CTO who helped create the “Nebula” cloud controller that formed the compute half what became OpenStack, left NASA to create a management appliance (also called Nebula) version of OpenStack, Kemp chose White to be principle hardware engineer and hardware architect for the company he called Nebula. Many of the Rackspace and OpenStack people eventually went on to create Vapor IO, which originally designed innovative circular datacenter designs but which has subsequently taken the automation created for those datacenter designs and turned it into a control plane for national-scale edge computing. White was a co-founder and vice president of hardware engineering at Vapor IO, and wanted to get back to hardware when he ran across Nguyen last year.
“It’s funny,” Nguyen tells The Next Platform. “Eight years ago, my vice president at Facebook asked me to tackle this memory disaggregation problem because memory costs a lot of money but we also did not have any expertise in memory chips and we did not have any internal designs. After my time at Facebook, we got together and decided to tackle this problem.”
Like all of the other CXL memory startups we have looked at so far, TORmem is implementing some of its key technologies using FPGAs but is working towards creating specific chips to do its particular flavor of memory sharing. Frankly, the protocols are changing so fast and are converging in somewhat unpredictable ways now that Gen-Z and OpenCAPI technology has been absorbed by the CXL Consortium.
The reason that TORmem has chosen IBM’s OpenCAPI Memory Interface – the same OMI spec that Big Blue uses for its Power10 servers and that it opened up and donated to the CXL Consortium – is the same reason that IBM developed OpenCAPI memory in the first place. It takes a lot fewer wires to do a serial interconnect than it does a parallel one.
To get started, TORmem is taking an X86 server loaded up with its memory management stack and allowing connectivity to a memory server over InfiniBand or Ethernet with RoCE. This is called the M1000, and it will be available in June 2023.

This M1000 development platform has a pair of Epyc 7313 processors from AMD and 32 memory slots that can host up to 8 TB of memory.
With the M4000, which is in development now and scheduled for production in Q4 2023, the TORmem architecture will be brought to market for the first time.
To create the memory sleds for its initial M4000 memory appliances, White says that TORmem had to balance the cost of various sizes of FPGAs against the number of lanes it would take to drive a reasonable amount of memory bandwidth and capacity. Looking at the options for making a memory sled for its appliance, White says that putting 16 modules per FPGA-based OMI was optimal.

“The FPGA pin count requirement for 16 parallel interface memory modules pushes FPGA prices to unacceptable levels,” White tells The Next Platform. “If you do the math connecting 16 memory modules with parallel interfaces to one chip, that is hundreds of signals. And you just can’t get an affordable FPGA that can do that. The key to getting all this memory attached to one chip is to go with a serial memory interface, and even before IBM’s OMI was pulled into the CXL Consortium, we chose it for this reason. But importantly, OMI is using serial lanes, just like PCI-Express is with access to the memory. So that cuts down the pin count, and that allows us to get things connected to the FPGA in a much denser method with without sacrificing any performance.”
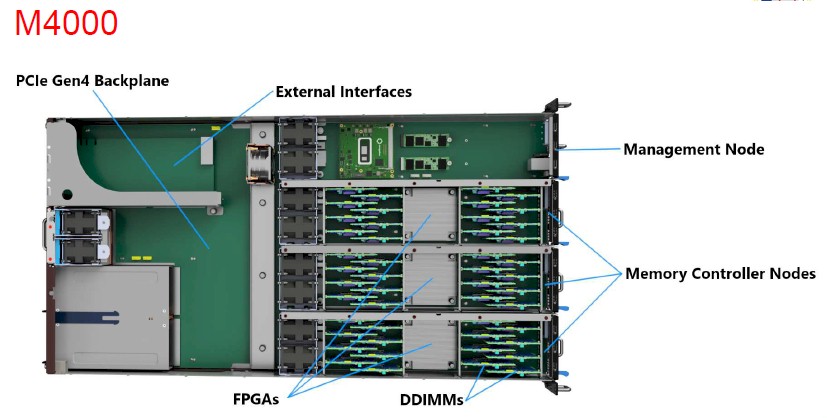
The M4000 will have a PCI-Express 4.0 switch with 100 lanes of I/O plus three OMI memory controllers (one per memory sled) implemented in FPGAs that front end a total of 48 OMI differential DIMMs with 12 TB of capacity using 256 GB memory sticks. The M4000 device will have three PCI-Express Gen 4.0 slots for external connectivity and will run a memory access protocol developed by TORmem that works on PCI-Express 4.0 fabrics and does not require PCI-Express 5.0 switching like CXL does.
With the M5000 memory appliance, which is expected to launch in Q2 2024, the memory server will be able to support memory pooling and will use the CXL 2.0 protocol atop a PCI-Express 5.0 fabric set up inside the box, like this:
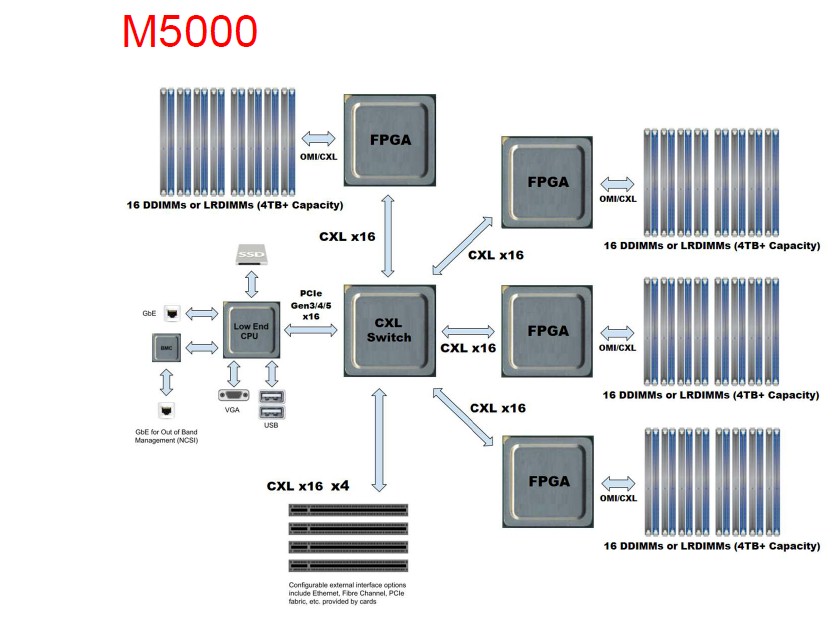
The TORmem M5000 memory server will have four FPGAs that implement the PCI-Express 5.0 and CXL 2.0 protocols on one side and the OMI serial interface on the other side, linking out to a total of 64 OMI differential DIMMs and a maximum capacity of 16 TB using 256 GB differential DIMMs. It is reasonable to assume this will be a four-sled design based on the diagram, but TORmem has not been specific. Each sled will have four PCI-Express 5.0 x16 slots coming off the FPGAs, linking out to an integrated 144 lane PCI-Express 5.0 switch. (TORmem is also looking at a 256 lane PCI-Express 5.0 switch to use here possibly.)
All of these devices above will support memory sharing – allowing for dynamic allocation of memory blocks that a server can use as main memory in addition to or as a replacement for its own internal DRAM. And it will not be until TORmem has raised some venture capital, the CXL protocols settle down a bit, and it creates a custom ASIC and replaces the FPGAs that it will support memory sharing, according to Nguyen. And that is expected to happen in 2024, but it will all depend on when the CXL 3.0 and PCI-Express 6.0 protocols are done and come into commercial being.

Meta Platforms Hacks CXL Memory Tier Into Linux
We have been excited about the possibilities of adding tiers of memory to systems, particularly persistent memories that are less expensive than DRAM but offer similar-enough performance and functionality to be useful. In particular, we have been strong advocates for disaggregating DRAM memory from the CPUs that make use of …
HBM Gives Xeon SPs A Big Boost On Bandwidth Bound Work
If there is one bright spot in the Xeon SP server chip line from Intel, it is the version of the “Sapphire Rapids” Xeon SP processor that has HBM memory welded to it. These chips make a strong case for adding at least some HBM memory – or something that …
Marvell Throws Hat Into Intel’s Universal Chiplet Interconnect Ring
Marvell Technology is the latest chipmaker to join the emerging Universal Chiplet Interconnect Express (UCI-Express) consortium, which is working toward an open interconnect standard for chiplet architectures. The chipmaker joins several heavy hitters in the tech arena that have thrown their weight behind the project, including AMD, Arm, Qualcomm, and …
Be the first to comment