

Since modern machine learning came onto the scene, the push has been on to make workloads leveraging the technologies as efficient as possible. Given what these applications are being asked to do – from being a cornerstone of the oncoming autonomous vehicle era to real-time analytics to helping enterprises more user-friendly, more profitable and more able to thwart cyberattacks – the speed and efficiency of such techniques as deep neural networks (DNNs) has been at the forefront.
That has included leveraging the capabilities of accelerators like GPUs and FPGAs and introducing new devices, such as Amazon Web Services’ Trainium devices for AI and machine learning training tasks in the cloud.
However, such efforts have only addressed part of the issue, according to Yuhao Ju, a Ph.D candidate at Northwestern University. What so many of the efforts to make DNN accelerators more efficient have missed is the need to improve the end-to-end performance of the deep learning tasks themselves, where the movement of data is still a significant factor in the overall execution time of the job. Speaking at the recent virtual ISSCC event, Ju said that for high-performing machine learning jobs, a CPU also is needed for pre- and post-processing and data preparation for the accelerator.
“A heterogeneous architecture is the most commonly used architecture, combining a separate CPU core and an accelerator together,” he said during a presentation at the event, adding that a direct memory access (DMA) engine and some special cores are needed “to control the data transfer into the CPU core and the accelerator core.”
It’s an inefficient way to move data, which slows down the processing of the DNN task. The accelerator is used about 30 percent to 50 percent of the time, with most of the rest of the time spent waiting for CPU processing and the movement of data between the CPU and accelerator cores.
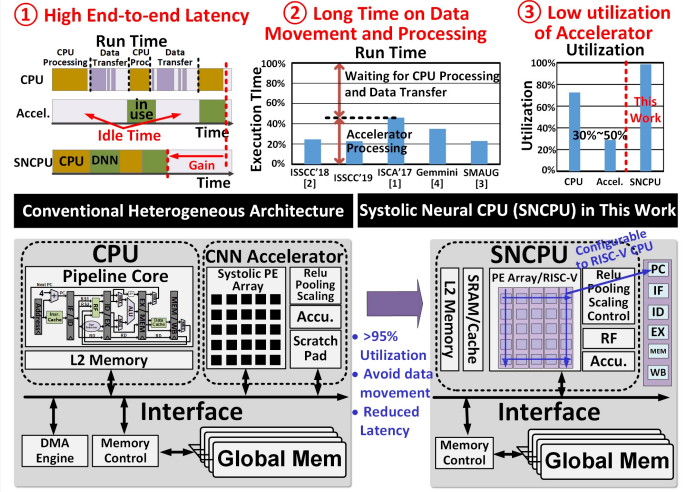
There has been other work aimed at addressing this issue, including “data compression, reduction of data movement or improvement of memory bandwidth,” Ju wrote in a research paper that was the basis for his presentation. “For instance, an accelerator coherency port (ACP) was designed to request data directly from the last level cache of the CPU instead of using the DMA engine to improve the efficiency of data transfer.”
What he and Jie Gu – who co-wrote the paper – are proposing a new architecture that brings together a conventional CPU and a systolic convolutional neural network (CNN) accelerator onto a single core, a highly configurable and flexible unified design that Ju said can deliver “upwards of 95 percent core utilization, you eliminate data transfer and you also reduce the latency for end-to-end ML tasks.”
Here is the die shot of the hybrid CPU-NNP chip:

Ju said that in a demonstration of a 65 nanometer test chip build from the new architecture – which he called a systolic CNN accelerator (SNCPU) – the architecture produced latency improvements of between 39 percent and 64 percent and a 0.65 TOPS/watt to 1.8 TOPS/watt energy efficiency while running image-classification tasks.
The SNCPU relies a lot not only on having everything in a single core to reduce the time needed to move data – and thereby ramping up the utilization of the core – but also the ability to reconfigure the chip as needed.
The chip offers a 10×10 PE array, which are the central computing tiles. The lanes through the array can run as columns or rows and can be configured as systolic MAC operations for the CNN accelerator or pipeline stages in a RISC-V CPU.
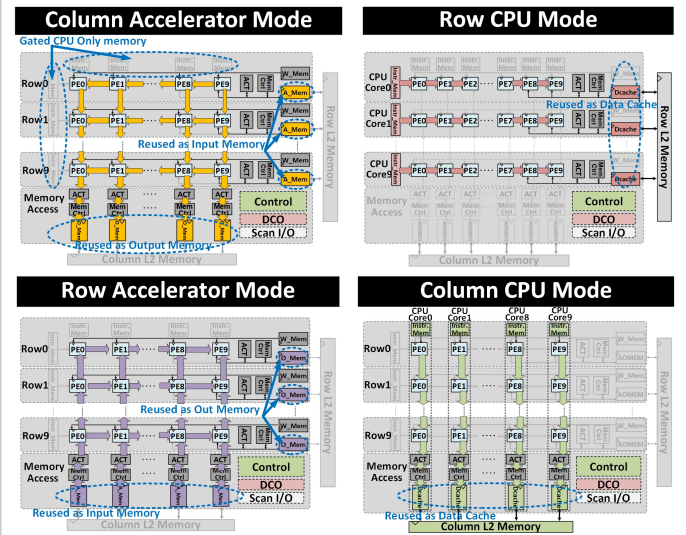
The chip also can be configured as a combination of both CNN accelerator and CPU, with half of the PE cores in each.
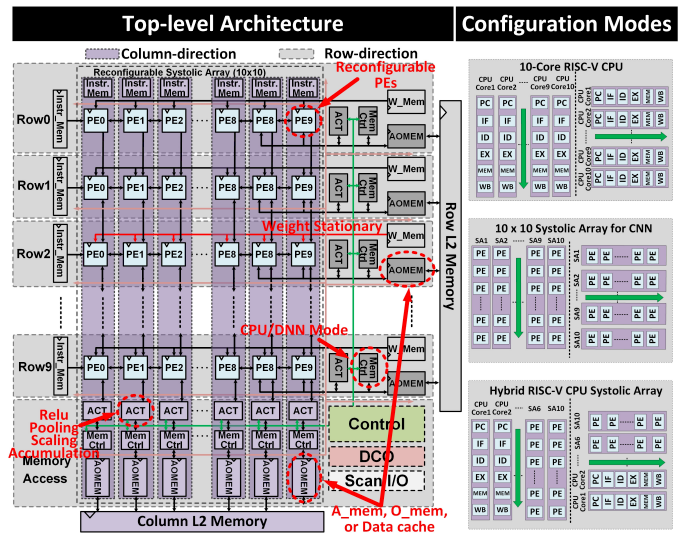
According to Ju, the accelerator mode supports typical systolic dataflows for weight-stationary operations, while as a CPU, each row or column of 10 PEs makes the RISC-V pipelines.
“Associated SRAM banks are also reconfigured for both purposes,” he wrote. “In accelerator mode, an accumulator (ACT module) for each row or column provides additional SIMD support for pooling, ReLU functionality and accumulation. Although data stays mostly local within the reconfigurable SRAM banks, L2 SRAM banks are also added to enable data exchange between different CPU cores during data processing in CPU mode.”
When building a 32-bit RISC-V CPU pipeline from a systolic PE array, each PE includes a simple pipelined MAC unit with 8-bit-wide inputs and 32 bits at the output. The first PE in each row or column used for the instruction cache address, two others are used for instruction fetch while reusing the internal 32-bit register and 8-bit input registers. Two PEs are used for the decoder stage and three PEs are combined for the execution stage, including one as ALU with additional logic for Boolean operations and a shifter, one to generate a new instruction cache address and one for the registers to pass the execution results.
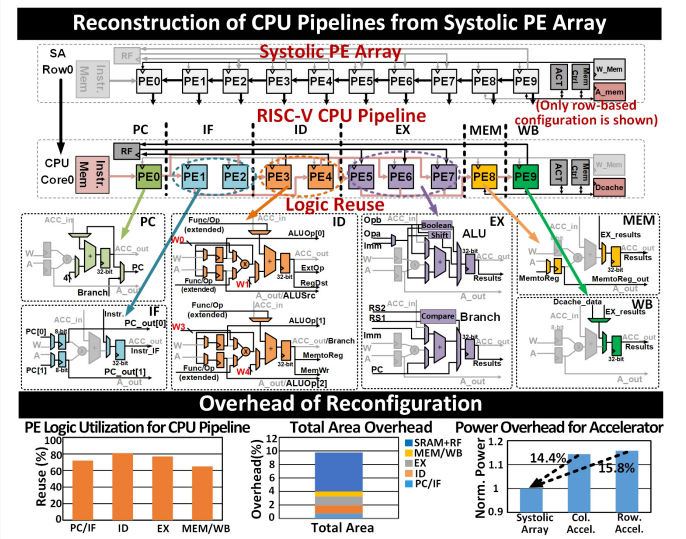
“The last two PEs are reconfigured into the memory stage (MEM) and write-back stage (WB) by reusing registers with additional MUX logic,” Ju wrote. “With an emphasis on logic sharing, the reconfiguration reuses 64-to-80% of the original PE logic for CPU construction.”
The overall overhead for reconfiguring the CNN accelerator for CPU functions is less than 9.8 percent, he wrote, including CPU functions in the PE-array (at 3.4 percent overhead), (6.4 percent) instruction and RF. The design in both the CNN and CPU modes also uses extensive clock gating to eliminate redundant power consumption from the additional logic. The power overhead for the CNN accelerator is about 15 percent more than the baseline original design, according to Ju.
“The SNCPU architecture allows the majority of data to be retained inside the processor core, eliminating the expensive data movement and DMA module,” Ju wrote. “To enhance data locality, a special dataflow sequence for CNN operation is adopted combining the 2 configurable modes (CPU, accelerator) and 2 directions (row-based and column-based).”
Ju outlined a “special 4-phase dataflow utilizing the four different configurations … for end-to-end image classification tasks.” In a typical architecture, the DMA engine transfers input data from the CPU cache to the accelerator’s scratch pad, a process that is eliminated in the four-step SNCPU dataflow.
The chip runs in CPU mode using rows to perform input-data preprocessing, such as image reshaping or rotation for the CNN. It also runs in column-accelerator mode with the data caches from the CPU mode reused as input memory for the CNN accelerator.
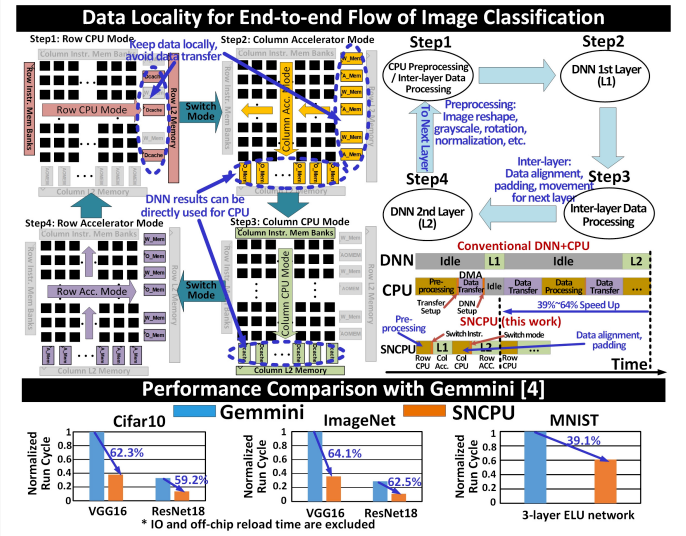
“After the accelerator finishes the entire layer of the CNN model, the SNCPU reconfigures to column-CPU mode to perform the data alignment, padding, duplication, post-processing by directly using the data from the output memory from the previous accelerator mode,” Ju wrote. In the fourth phase, “the SNCPU switches to row-accelerator mode to process the second layer of the CNN by directly using the data cache from previous CPU mode.”
The four-phase operation repeats until all CNN layers are done, thus eliminating the intermediate transfer of data across cores. Furthermore, the SNCPU can be configured into 10 CPU cores that can perform 10 separate instructions simultaneously, which improves the pre- and post-processing the CPU over the usual CPU-and-CNN architecture.

Great article