

Microsoft has been among the first to build and operationalize clusters based on AMD’s Milan-X processors, which were formally announced this morning. This is a big deal for HPC shops that have made the cloud leap, either for burst or production, as it means 3X the L3 cache of Milan, up to 804MB total cache per socket, up to 64 Zen 3 cores, all resulting in up to a 50 percent uplift across a broad swath of HPC applications.
The uplift has been particularly noticeable in areas like fluid dynamics and traditional physics-driven simulations, which are bound far more by memory performance than pure compute.
This defines the majority of HPC applications, although some — like molecular dynamics and older codes like the WRF weather simulation package — will not get the 50 percent boost. Even still, according to Evan Burness, Azure’s Principal Program Manager for HPC, there is still benefit — around 20 percent performance improvement with the amplification of the effective memory bandwidth and reductions in memory latency.
Here’s the other interesting bit: since it is unlikely many HPC shops will have access to Milan-X in the very near term, Microsoft is using Milan-X to upgrade its existing HBv3 virtual machines without any additional cost. This will let users take the architecture for a spin and tap into scaling and performance benefits that, according to Microsoft’s own runs through common HPC applications, go beyond the incremental improvements we’re used to seeing with new processor launches.
Take a look below at the comparison between previous processor offerings via Azure and what the Microsoft team is seeing in both node- and cluster-level performance leaps, including for real-world, common applications like ANSYS Fluent.
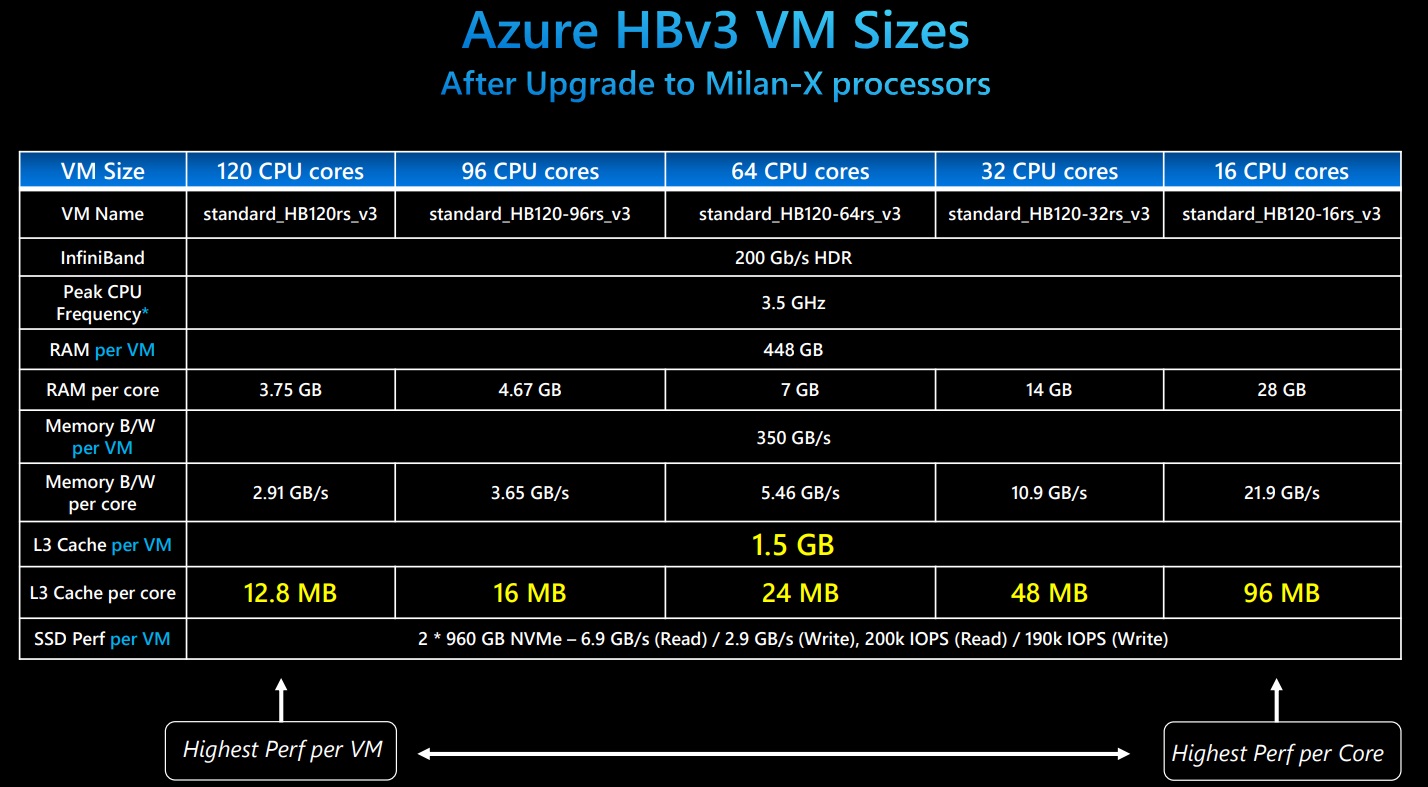
Note that looking at L3 cache size alone, absent context, can be misleading. Different CPUs balance L2 (faster) and L3 (slower) ratios differently in different generations. For example, while an Intel Xeon “Broadwell” CPU does have more L3 cache per core and often more CPU as well as compared to an Intel Xeon “Skylake” core, that does not mean it has a higher performance memory subsystem. A Skylake core has much larger L2 caches than does a Broadwell CPU, and higher bandwidth from DRAM. Instead, the above table is merely intended to make apparent how much larger the total L3 cache size is in a Milan-X server as compared to all prior CPUs.
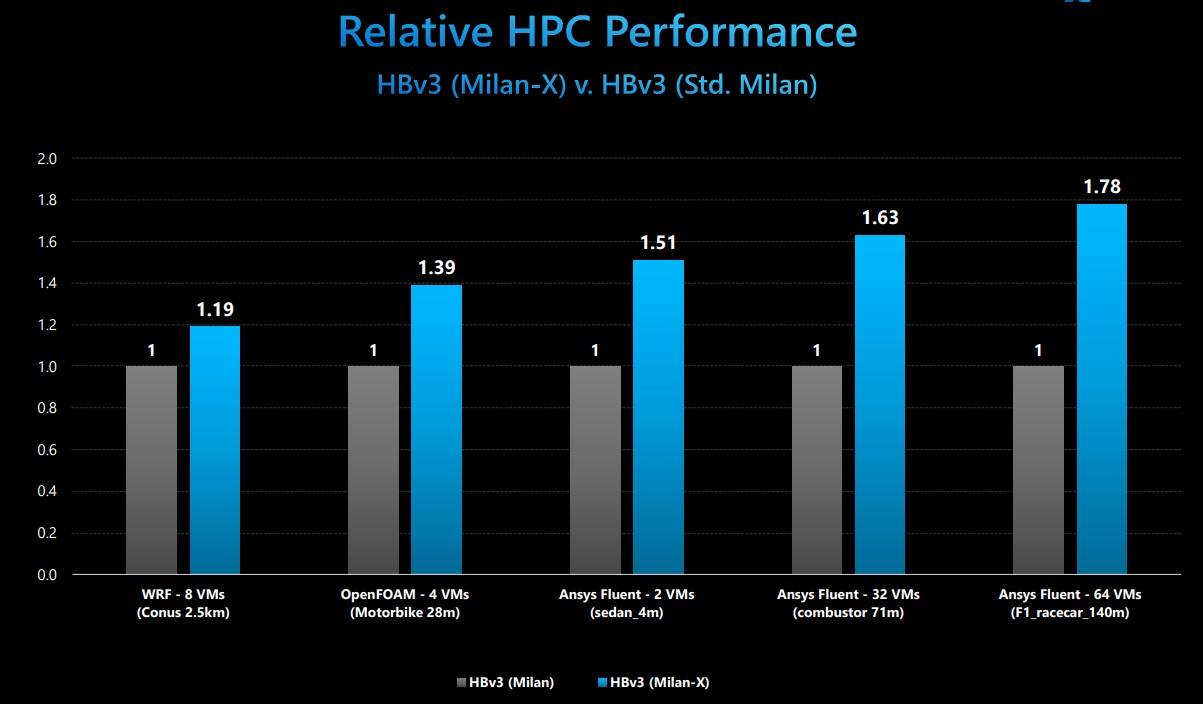
During the AMD briefing today, the company gave its own internal performance numbers but those were based on single VM performance, which is useful generally but does not represent scaling efficiency and other factors HPC users consider. Below is a range of applications with different sized models that highlight just how much of a jump that boost in cache makes a difference per server. “It’s not common to see this in a CPU generation with uplift in performance by nearly 80 percent with no change to the underlying architecture, just improvements in memory performance,” Burness says.
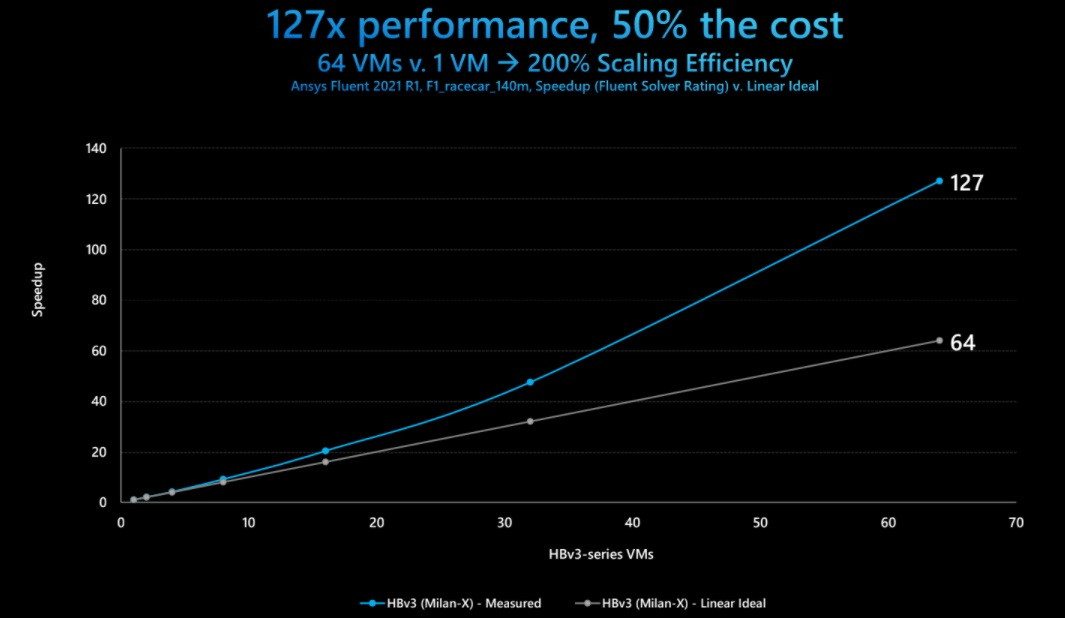
Linear speedups are common, this kind of uplift is nothing short of disruptive, Burness explains. “Many Azure customers are running ANSYS Fluent. Here we measured not just linear performance improvements to nearly 64 virtual machines (8,000 cores), we’re seeing 200 percent scaling efficiency. The more VMs you deploy, the more you can scale your problem, the less you pay. The ‘penalty’ for running 127X faster is you’re paying half the cost of a single VM. That’s the disruptive value proposition we’re getting at here, there is a material reason for customers to do more HPC on the Azure cloud,” he adds.
Burness tells us the HBv3 machine type has been one of the fastest adopted HPC products by a long shot. “Feedback has been boiled down to the basics: we had it in Azure faster than anyone could get for themselves on site, then they would find that we were faster than what they had on site.”
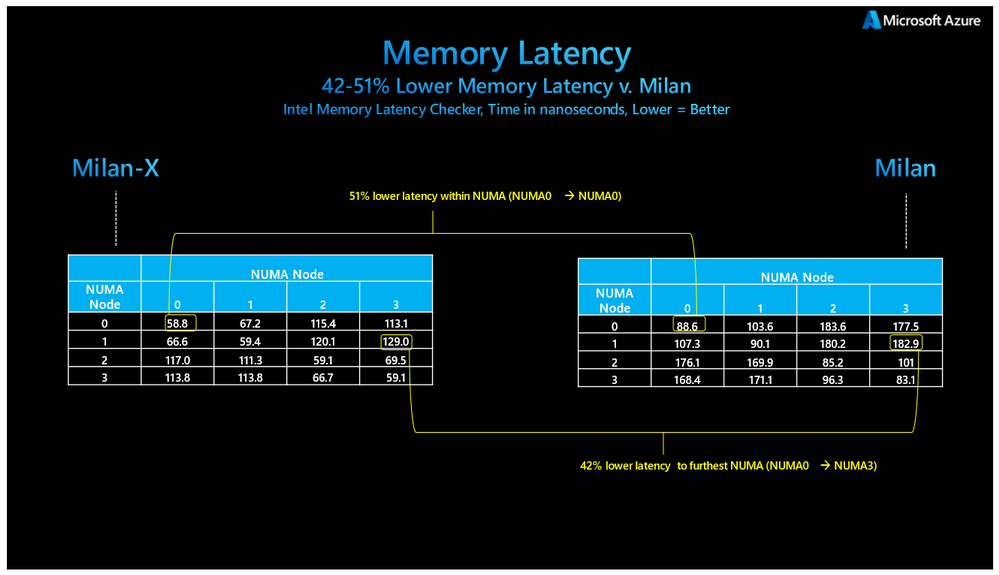
Using the Intel Memory Latency Checker, Microsoft measured best case latencies (shortest path) and found improvements of 51 percent and worst case latencies improving by 42 percent. The Azure team says these are some of the largest relative improvements for memory latencies in more than a decade when memory controllers moved onto CPU packages.
“It is important to note that the results measured here do not mean that Milan-X is improving the latency of DRAM accesses. Rather, the larger caches are causing the cache hit rate of the test to go up, which in turn produces a blend of L3 and DRAM latencies that, taken together, produce a better real-world effective results than would occur with a smaller amount of L3 cache,” Burness says.
“It is also important to note that because of the unique packaging AMD has utilized to achieve much larger L3 caches (i.e. vertical die stacking) that the L3 latency distribution will be wider than it was with Milan processors. This does not mean L3 memory latency is worse, per se. Best case L3 latencies should be the same as compared to Milan’s traditional planar approach to L3 packaging. However, worst case L3 latencies will be modestly slower.”
The Azure team is expecting big growth in existing HPC use with Milan-X and will be looking to a range of users for its preview, which starts immediately. They are watching for customers with large-scale HPC workloads as well as those that push new, niche boundaries to test speedups against that 50 percent boost common simulation applications have achieved.
Being first to serve HPC has been a priority for Microsoft Azure for the last several years. While AWS dominated early HPC cloud conversations, Microsoft has been steadily showing progress in terms of big name, large-scale users like the UK Met Office and being first to market with some notable achievements, including the first 20,000 core MPI job in 2019 and an 80,000 core run in 2020, showcasing 200Gb/sec HDR with adaptive routing — a first for any cloud. It also has shown off impressive performance in parallel file systems and Infiniband speeds (1.6Tb/sec for Nvidia A100 GPUs).
Burness says Azure expects this free upgrade will keep existing customers scaling and new customers onboarding. Among the HPC areas, one hot area for growth is expected to be the silicon design market. “They don’t have very many heavily parallelized, MPI applications but that’s the space where you can see some extraordinary uplifts in RTL simulations,” he explains. “That’s a workload because it’s lightly or single threaded with per core, expensive licensing, the gen-over-gen gains in the last decade have been in line with per-core performance benefits so the gains have been incremental. To show the kinds of gains with Milan-X that’s a rare thing for the EDA community; they haven’t seen those kinds of gains since we were in the gains of CMOS clock scaling wars.”

More CPU Cores Isn’t Always Better, Especially In HPC
If a few cores are good, then a lot of cores ought to be better. But when it comes to HPC this isn’t always the case, despite what the Top500 ranking – which is stacked with 64-core Epycs – would lead you to believe. Speaking with executives at Atos and …
The Looming Arm Server Battle Between AWS And Microsoft
Wouldn’t it be funny if Google ends up being the stalwart supporter of the X86 architecture among the hyperscalers and cloud builders? Amazon Web Services has been pushing its Graviton line for the past several years, and has had Graviton2 in production since March last year and is still previewing …
AMD 3rd Gen Epyc CPUs Put Intel Xeon SPs On Ice In The Datacenter
SPONSORED Sometimes, bad things turn into excellent opportunities that can utterly transform markets. Many years hence, when someone writes the history of the datacenter compute business, they will judge AMD tapping Taiwan Semiconductor Manufacturing Corp to etch the cores in its second and third generation Epyc server processors to be …
Be the first to comment