

The rapid movement of data to the cloud, the sharp rise in the amount of east-west traffic and the broadening adoption of modern applications like artificial intelligence (AI) and machine learning are putting stress on traditional networking infrastructures that were designed for a different era and are struggling to meet the demands for better performance, more bandwidth and less latency.
That is forcing networking vendors to consider not only tweaks to their current products in hopes of eking out a bit more of each but to rethink the way modern networks need to look and operate and innovate accordingly.
We wrote about startup Enfabrica’s take on this in June and earlier this month Aruba Networks introduced its CX 10000, the latest member of its CX family of top-of-rack switches that is based on the vendor’s AOS-CX network operating system. It will also run its Aruba Fabric Composer software for provisioning the CX switches and unifying an enterprise’s datacenter infrastructure that also includes systems from Hewlett Packard Enterprise, Aruba’s parent company.

The CX 10000 – which Aruba calls the first “distributed services switch” – will offer up to 3.2 Tb/sec of switching capacity and 48 10 Gb/sec and 25 Gb/sec ports and six 40 Gb/sec and 100 Gb/sec ports (that’s Ethernet). The company also promises a 10X improvement in performance and 1,000 times the scalability over traditional network infrastructure and all at a third of the cost.
The key to this is HPE’s partnership with Pensando Systems, a four-year-old startup founded by former Cisco Systems executives and chaired by ex-Cisco chief executive officer John Chambers. Aruba is leveraging Pensando’s Elba data processing unit (DPU) – or SmartNIC – to offload the network security tasks that currently run on separate appliances and deliver them as services. Those tasks include firewalls, encryption, network address translation and load balancing. With the Elba DPU, enterprises can get rid of the appliances and extend network and security capabilities farther out to the edge or into colocation facilities where space or power might be at a premium.
“While data center network fabrics have evolved over the past decade, providing higher-performing 25G, 100G, 400G leaf-spine topologies to address the volume and velocity of emerging application architectures, security and services architectures have not kept pace,” David Hughes, chief technology and product officer at Aruba and former founder and CEO of network vendor Silver Peak Systems (which HPE bought last year for $925 million), wrote in a blog post. “Centralized security appliances weren’t designed to inspect and protect application traffic that is moving east-west within the data center. It’s not operationally or economically practical to deploy a suite of security appliances in every server rack. And hair-pinning traffic to an appliance sitting in a centralized services leaf comes with heavy performance and cost penalties.”
Now comes Rockport Networks, a startup launched in 2012 that this week came out of stealth with a networking architecture that does away with switches. Rockport’s official entrance onto the scene comes at a time when enterprises and HPC alike are adopting workloads like AI and machine learning, which demand performance but aren’t finding it in traditional network, according to Rockport chief technology officer Matthew Williams.

“When you have a lot of bandwidth-sensitive and latency-sensitive workloads that exist in the same environment, you get a lot of challenges in maintaining good performance,” Williams tells The Next Platform. “It’s this emergence – not only in the true HPC community – of requirement for a high-performance network, but also in the enterprise as you adopt these advanced applications. We’re also seeing that the architecture in the network hasn’t really been designed for this high-performance, east-west traffic requirement and the datacenter needs to be optimized for that, especially the high-performance cluster, in order to get adequate performance.”
East-west traffic is becoming more of a concern, with as much as 70 percent of traffic moving in that direction.
“With all these high-performance applications, it’s not a machine figuring out the answer and delivering the answers,” running north-south, Williams says. “That’s traditionally how things have worked: a request and a response. These workloads are, to these 20 or 50 or 100 servers, here’s a problem you have to work on together. All of a sudden, it’s not about the request and a response. It’s how these different machines are going to work together to come to the answer. It’s this parallelism that’s prevalent in all these high-performance applications. It’s AI, it’s machine learning, deep learning, traditional HPC. It’s an entire process communication that’s heavy east-west traffic. And you need a network that can not only support that east-west, but deliver consistent latency, or you run into the challenges that pop up.”
The complexities that have built up in the datacenter in general and networks have driven the need to rethink architectures, he says. That has happened with compute and storage through increasingly composable and disaggregated models aimed at improving performance and efficiency at scale. Networks haven’t kept up, Williams says.
Rockport’s architecture is designed to get the switch out of the way to enable improvements in performance, bandwidth and latency. At its core is the Rockport Network Operating System (rNOS), designed to essentially navigate data through the best paths in the network to reduce congestion and latency and break down packets into small pieces called FLITs to more efficiently move down those paths, according to the company.
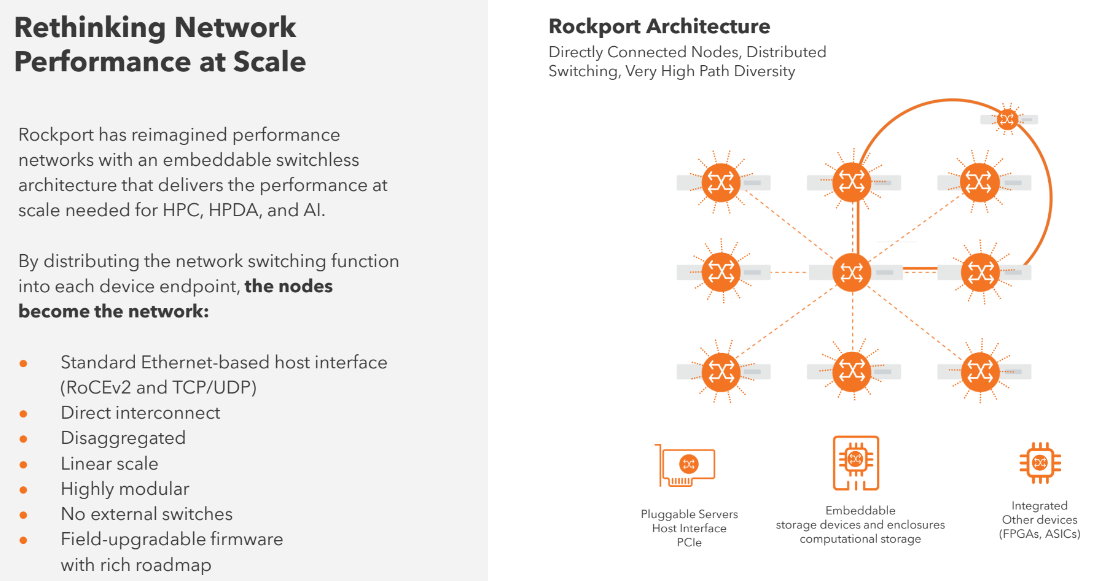
The rNOS is housed in the Rockport NC1225, which Williams said shouldn’t be confused with network interface cards (NICs) or SmartNICs found in servers or storage enclosures and rely on switches to create traditional network fabrics. The NC1225 also is housed in the servers and storage enclosures but doesn’t interface with a network because it essentially moves the functions of switching to each endpoint. The nodes become the network.
“The hosts, when they plug in one of our cards, see a standard Ethernet-based host interface, full RDMA TCP, all of the standard stack offloads,” he says. “Everything is there on day one – full support of all workloads, all drivers, all software stacks. It just works. It’s plug-and-play replacement. Whether a customer is using Ethernet or InfiniBand, it really doesn’t matter. We’ve moved everything to the endpoint. Everything is linear. We don’t have to worry whether switch ports are available or whether the switches are full and I have to create a new wiring pattern. Each node is bringing along its own switching capability. You can add nodes as you wish, you can remove them. Everything is just very easy to scale.”
The card, armed with a Xilinx FPGA, also is programmable, driving more flexibility. It’s a half-height, half-depth PCIe card that provides a standard Ethernet host and creates a 300 Gb/sec fabric per each node. It’s also the only active component in the Rockport’s architecture. A passive fiber optic cable connects the card to another component the company calls a SHFL (pronounced “shuffle”), a passive cabling device that sits where top-of-rack switches traditionally are housed.

“What we have are up to twelve links coming from this card on a single cable,” Williams says “You plug it into the SHFL. Those twelve links are distributed to the correct neighbor nodes. It’s a physical wiring pattern within the SHFL that creates a pattern of connectivity. There are rich topologies that supercomputers have traditionally supported and the SHFLs are pre-wired to those topologies. I just plug into my cable, I plug in my card and I plug in my cable. Nothing else is required, and it builds out a lossless, highly scalable, power-efficient supercomputer network.”
The result is a network architecture that Williams says can reduce workload completion time under load by up to 28 percent and decrease end-to-end latency at scale by three times over traditional networks. A single switch by itself is a high-performance, powerful device, he says. However, one they’re hooked up together to create a fabric, system level effects like congestion, packet loss, complexity, inefficiencies and costs related to power and cooling set in. A key issue becomes tail latency, when a large-scale parallel-processing systems where multiple machines are working on a problem and communicating with each other. They all have to wait for the last message to arrive and often those messages are stalled in the network.
“This high-tail latency that you see in traditional networks extends your workload completion times and makes them unpredictable,” he says. “You don’t know how much congestion there is going to be. You just know it’s going to be impactful and that means people waiting for results. I’m not doing the workloads for fun. I have to wait longer for my results and the scale of a workload is limited. The more machines involved in working on a workload, the more communication there is. The more communication there is, the more sensitive it is to a network issue. The scale of these things, the size of a simulation, the amount of data you can process, is actually limited by the network’s performance. Not because of bandwidth. It’s because if it doesn’t work well and it’s congested and if workloads are taking longer, you can run fewer workloads.”
Rockport, based in Ottawa, Canada, has about 165 employees, including about 100 engineers, and has raised $18.8 million. Williams says the company is working with a number of high-performance datacenter customers and is collaborating with the Texas Advanced Computing Center (TACC), which houses the Dell-based “Frontera” supercomputer. TACC has installed 396 nodes on the supercomputer running production workloads such as quantum computing and life sciences research related to the COVID-19 pandemic on Rockport’s technologies. TACC director Dan Stanzione said in a statement that the group has seen promising initial results related to congestion and latency and noted the ease of installing and managing the architecture.


Economics And The Inevitability Of The DPU
The advent of the Data Processing Unit or the I/O Processing Unit, or whatever you want to call it, was driven as much by economics as it was by architectural necessity. The fact that chips are pressing up against reticle limits and CPU processing for network and storage functions is …
With DPU-Goosed Switches, HPE Tackles VMware, Security – And Maybe HPC And AI
Pendulums are always swinging back and forth in the datacenter, with functions being offloaded from one thing and onloaded to another cheaper thing that is often more flexible or faster. So it is with network functions that were originally in distinct devices, then pulled onto CPUs during the software-defined networking …

Cisco Cuts Network Costs By Welding Nexus Switch To AMD DPU
There are two ways to make a programmable switch that can run network applications and accelerate certain network functions. The first and more obvious way to create a programmable switch is to add programmability – hopefully through the addition of engines that can run algorithms created in the P4 programming …
Be the first to comment