

Not so very long ago, distributed computing meant clustering together a bunch of cheap X86 servers and equipping them with some form of middleware that allowed for work to be distributed across hundreds to thousands to sometimes tens of thousands of nodes. Such scale-out approaches, which added complexity to the software stack, were necessary because normal SMP and NUMA scale up techniques, with very tightly coupled compute and shared memory across a dozen or two nodes, simply could not stretch any further.
These distributed systems, which were difficult enough to build, are child’s play compared to what we at The Next Platform are starting to call “hyperdistributed systems,” which are evolving as disaggregation and composability have entered the imagination of system architects at the same time as a wider and wider variety of compute, memory, storage, and networking components are available – and are expected to be used in flexible rather than static ways.
The problem, say the co-founders of a stealth-mode startup called Enfabrica, is that this new hyperdistributed architecture has more bottlenecks than a well-stocked bar. And they say they have developed a combination of silicon, system hardware, and software that will create a new I/O architecture that better suits hyperdistributed systems. Enfabrica is not uncloaking from stealth mode just yet, but the company’s founders reached out to us as they were securing their first round of funding – $50 million from Sutter Hill Ventures – and wanted to elaborate the problems they see in modern distributed systems before they eventually disclose how they have solved those problems.
Enfabrica was formed in 2020 by Rochan Sankar, its chief executive officer, Shrijeet Mukherjee, its chief development officer, plus other founding engineers, and its founding advisor is Christos Kozyrakis, a professor of electrical engineering and computer science at Stanford University for the past two decades who got his PhD in computer science at the University of California at Berkeley with none other than David Patterson as his PhD advisor. Kozyrakis runs the Multiscale Architecture and Systems Team (MAST) at Stanford and has done research stints at Google and Intel, among other organizations; he has done extensive work on vector processors, operating systems, cluster managers for clouds, and transactional memory systems.
Sankar got his bachelor’s in electrical engineering from the University of Toronto and an MBA from the Wharton School at the University of Pennsylvania and spent seven years at Cypress Semiconductor as an application engineer and chip architect and was notably the director of product marketing and management at Broadcom who drove five generations of its “Trident” and “Tomahawk” datacenter switching ASICs, which had over 300 million ports sold and generated billions of dollars in revenue for Broadcom.
Mukherjee got his Master’s at the University of Oregon and spent eight years at Silicon Graphics working on high-end graphics systems before joining Cisco Systems as a member of its technical staff and becoming a director of engineering on the groundbreaking “California” Unified Computing System converged server-network system, specifically working on the virtual interface card that is a predecessor to the DPUs we see emerging today. After that, Mukherjee spent nearly seven years at Cumulus Networks as vice president of software engineering, building the software team that created its open source switch software (now part of the Nvidia stack along with the switch ASICs, NICs, and switch operating systems from the $6.9 billion acquisition of Mellanox Technologies.) When Nvidia bought Cumulus, Mukherjee did a two year stint at Google working on network architecture and platforms – and he can’t say much more about what he did there, as usual.
Sankar and Mukherjee got to know one another because it was a natural for the leading merchant silicon supplier for hyperscaler and cloud builder switches to get to know the open source network operating system supplier – Cumulus needed Broadcom more than the other way around of course. Mukherjee and Kozyrakis worked together during their stints at Google. The team they have assembled – the exact number is a secret – are system architects and distributed systems engineers that have deployed “planetscale software,” Mukherjee put it, including people from Amazon Web Services, Broadcom, Cisco Systems, Digital Ocean, Facebook, Google, Intel, and Oracle.
“We jointly saw a massive transformation happening in distributed computing,” Sankar tells The Next Platform. “And that is being keyed by the deceleration of Moore’s Law and on the fact that Intel has lost the leadership role in setting the pace on server architecture iterations. It is no longer a tick-tock cycle, which then drove all of the corresponding silicon and operating system innovation. That has been completely disrupted by the hyperscalers and cloud builders. And we are now in a race with heterogeneous instances of compute, storage, and networking. where we see a diversity of solutions, cloud sourced processors, other ASICs, GPUs, transcoders, FPGAs, disaggregated flash, potentially disaggregated memory. What we saw happening at the datacenter level in terms of the disaggregation of the architecture and the need for interconnects at the datacenter level is now headed straight into the rack.”
It is hard to argue with that, and we don’t. We see the same thing happening, and the I/O is way far out of whack with the compute and the storage. Take AI as an example.
“AI chips are basically improving their processing capabilities by 10X to 100X, depending on who you believe,” says Kozyrakis. “At the same time is that systems are becoming bigger. If you look at just hyperscalers, it’s an order of magnitude increase in the size of datacenters. So we have this massive increase in compute capacity. But we need to provide the 10X, the 100X, the 1000X really, in the I/O connectivity infrastructure. Otherwise, it will be very difficult to bring the benefits of this capacity to bear.”
To put it bluntly, hyperscaling was relatively easy if no less impressive for its time, but hyperdistribution is much more complex and it is never going to work without the right I/O. With hyperscaling, says Sankar, distributed systems were built with parent-child query architectures mapped onto homogeneous two-socket X86 server nodes with the same memory and storage and the same network interfaces. The hardware was essentially the same, and that made it all easy and drove volume economics to boot.
“Datacenters are evolving into data pipelines,” Sankar explains. “The diversity of what is happening in the software layer with respect to how data is being processed is mapping into the infrastructure layers, and it is driving increasing heterogeneity in the server architectures to make them optimized. We firmly believe that the solutions that are being sketched out today suffer from problems with scalability and performance, and they suffer from the inability to be best of breed across a wide range of composable architectures.”
And without really getting into specifics, Enfabrica says it is building the hardware and software that is going to glue all of this compute, storage, and networking together in a more scalable fashion. We strongly suspect that Enfabrica will borrow some ideas from fast networks and DPUs, but that this is also more than just having a DPU in every server and lashing them together. Pensando, Fungible, Nvidia, and Annapurna Labs within Amazon Web Services are already doing that. And to be frank, what those companies will tell you is that many of the ideas that are in those smart-NICs or DPUs came from the work that Mukherjee did on the virtual network and storage interfaces in the UCS platform. The work Mukherjee did with Cumulus has also figured prominently in the way certain hyperscalers do their networking today, by the way.
Without getting into specifics, since the company is still in stealth mode, Enfabrica thinks it has come up with a better idea for massively distributed I/O.
“If you look at all of these companies, they have built a product and now they are going to try to convince people to use them,” says Mukherjee. “Whereas we assembled a team of people who know what the product needs to do and how it will actually fit in into the lattice of compute, network, and storage that it needs to fit into. This difference actually changes how we emphasize what’s hardware and what’s software, and where you need to put effort in and where you don’t. For example, to make a very illustrative point: how big should a table of something be? Hardware is always going to be limited, software will always want everything to be unlimited. How do you make of those decisions and how do you partition? It requires people who have delivered these kinds of solutions because they understand where people are willing to take a cutback and where absolute line performance matters.”
We realize that none of this tells you what Enfabrica is doing. But we can tell you how the company is thinking about I/O in the datacenter and the market sizes and players in these areas that it plans to disrupt. Take a look at this chart we have assembled:
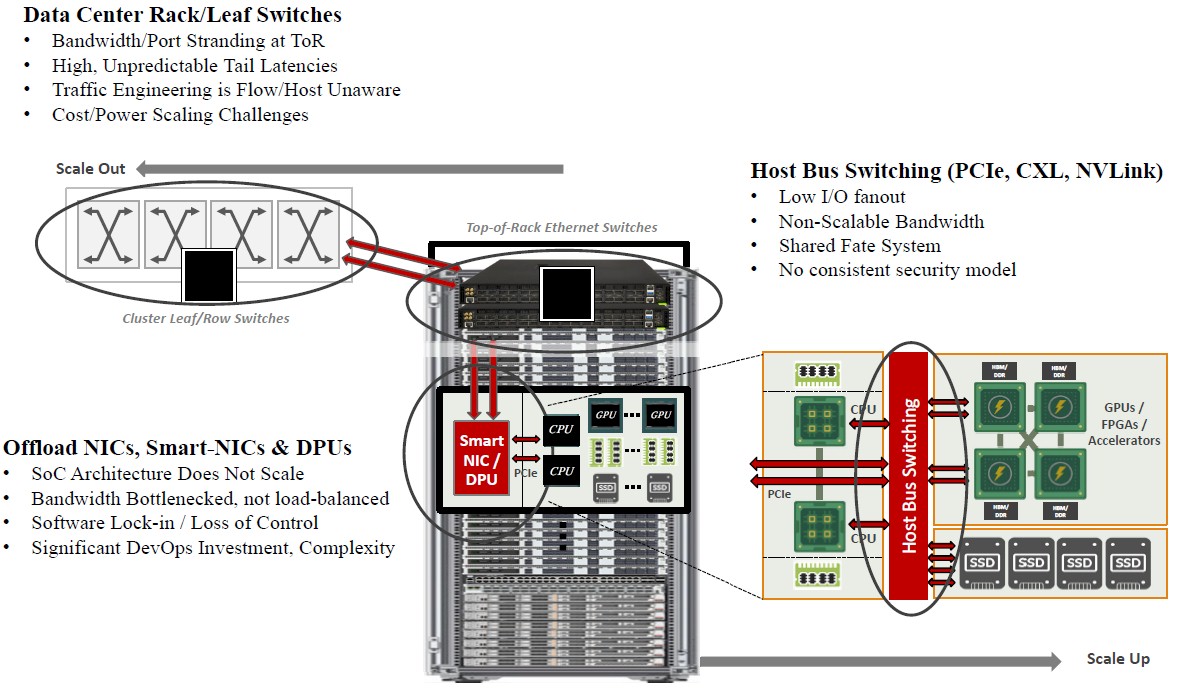
This is what Sankar calls “the $10 billion I/O problem” that Enfabrica is trying to solve, and that is roughly the total addressable market of all of the silicon for interconnects shown above. This lays out all of the shortcomings of various layers of the interconnect stack.
Whatever Enfabrica is doing, we strongly suspect that it is going to disrupt each of these layers withing the server, within the rack, across the rows, and within the walls of the datacenter. The company is still in stealth mode and is not saying, but we expect to hear more in 2021 and 2022 as it works to intercept a slew of different technologies and scale out systems that are being architected for 2023 and beyond.



Be the first to comment