
As we’ve talked about in the past, the focus on data – how much is being generated, where it’s being created, the tools needed to take advantage of it, the shortage of skilled talent to manage it, and so on – is rapidly changing the way enterprises are operating both in the datacenter and in the cloud and dictating many of the product roadmaps being developed by tech vendors. Automation, analytics, artificial intelligence (AI) and machine learning, and the ability to easily move applications and data between on-premises and cloud environments are the focus of much of what OEMs and other tech players are doing. And all of this is being accelerated by the COVID-19 pandemic, which is speeding up enterprise movement to the cloud and forcing them to adapt to a suddenly widely distributed workforce, trends that won’t be changing any time soon as the coronavirus outbreak tightens its grip, particularly in the United States.
OEMs over the past several months have been particularly aggressive in expanding their offerings in the storage sector, which is playing a central role in help enterprises bridge the space between the datacenter, the cloud and the network edge and to deal with the vast amounts of structured and – in particular – unstructured data being created. That can be seen in announcements that some of the larger vendors have made over the past few months. Dell EMC has bolstered its storage portfolio to address the needs of today’s enterprises. The company has unveiled its PowerStore flash systems that lean on technologies like storage-class memory (SCM), NVM-Express and software based on AI and Cloud Validated Designs for PowerStore for hybrid clouds. A month later, Dell EMC introduced PowerScale aimed unstructured data, uncoupling the OneFS operating system from the Isilon hardware and pairing it with PowerEdge systems.
Dell also has partnered with Google Cloud to create OneFS for Google Cloud, bringing file data management to the public cloud to enable organizations to handle data-intensive workloads between corporate datacenters and Google’s public cloud. The companies also use Isilon filesystems on premises and the compute and analytics services in Google Cloud so businesses can move workloads a large as 50 PB in a single file system between the two environments.
It certainly hasn’t been only Dell EMC. Hewlett Packard Enterprise last month made enhancements to its Primera and Nimble storage lineups that add more intelligence, automation and capabilities, and do so in an as-a-service way. The upgrades came in part via HPE’s InfoSight predictive analytics platform, making the systems smarter and better able to predict and prevent issues before they become problems. The Primera systems for higher-end storage can automatically act on intelligence from the AI platform while InfoSight enables Nimble systems – for mid-range storage workloads – to offer cross-stack analytics to simplify virtual machine (VM) management for both VMware and Microsoft Hyper-V. The vendor also brought all-NVMe support to Primera and SCM to Nimble.
Pure Storage, with its recent Purity 6.0 release, enables its FlashArray systems to support both file and block storage natively on the same system. Pure launched the latest version of its storage OS at its virtual Accelerate event in June.
IBM this week is running out new storage hardware and software designed to put more structure around what it says is the needed infrastructure to support AI-optimized workloads. IBM over the past few years – including recently under new CEO Arvind Krishna – that building a smarter business around AI is a key mission for the company, right up there with leveraging the cloud in large part through its $24 billion acquisition of Red Hat last year. IBM is awash in AI efforts in most areas of the company, such as what it is doing with its Watson technology and IBM Cloud Pak for Data, an integrated data and AI platform.
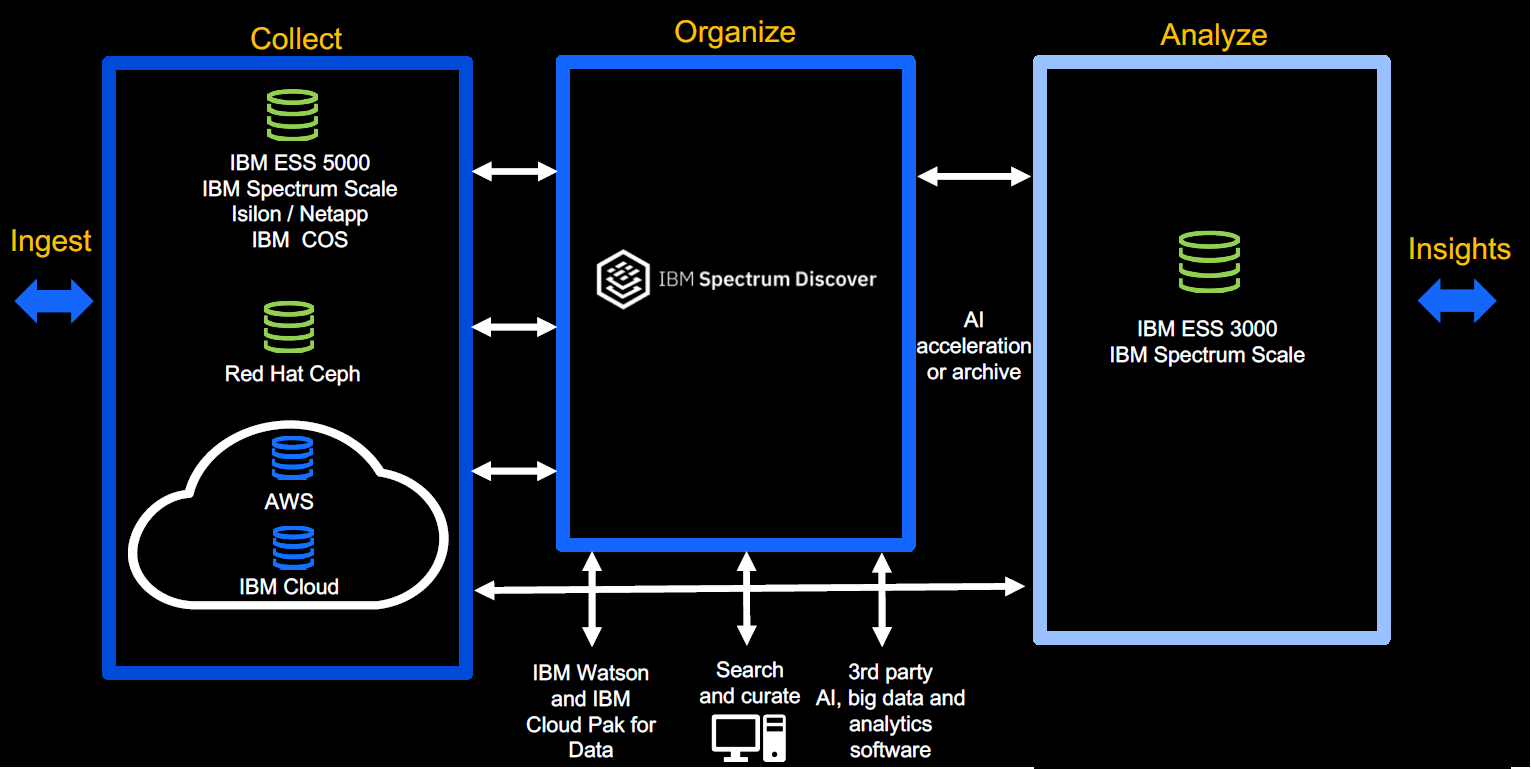
What IBM is doing with the new storage offerings is helping to create an architecture that can support the complex AI- and analytics-optimized workloads that enterprises are grappling with, according to Eric Herzog, vice president and chief marketing officer of worldwide storage channels for IBM Storage. To efficiently run such workload, organizations need to be able to collect, organize and analyze the data, and then leverage the information to accelerate business decisions and product and services development. That means ensuring access to all the necessary data sources and managing and analyzing the data together regardless of how many places it’s located.
“If you don’t have this information architecture, then you’re doomed to mess up your AI or your analytics or your big data,” Herzog tells The Next Platform. “They’re just not going to work. As everyone’s rushing to do this – not just global enterprise accounts, but everybody’s getting into this game, small and medium companies, too. The point is, it’s a big, medium and small world now. AI originally was HPC and supercomputing, all university stuff. Now it’s moved into the enterprise and now it’s spreading from the big enterprises down to small shops.”
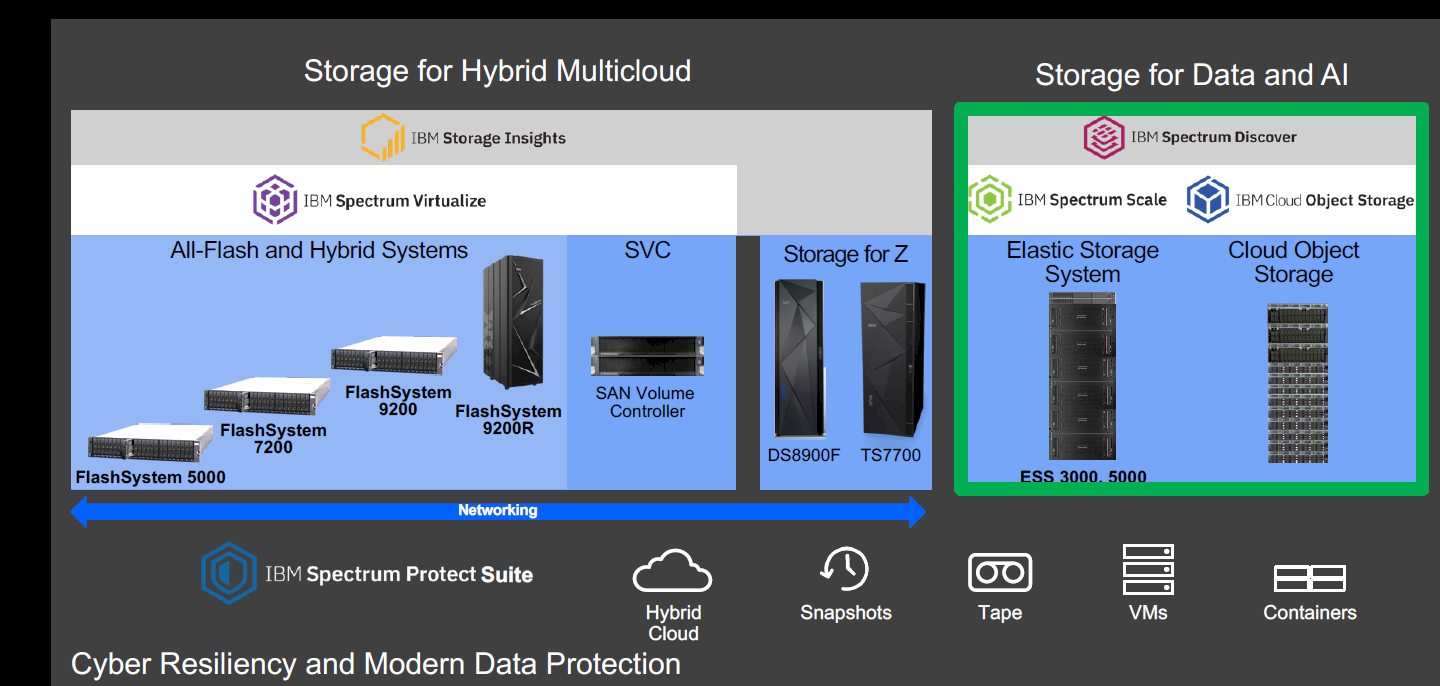
So what is IBM doing? For one, the company unveiled the Elastic Storage System (ESS) 5000, an all-hard drive array optimized for data collection and long-term capacity and designed for data lakes. The 2U system complements the ESS 3000, an all-flash NVMe array introduced in October 2019 and also optimized for AI and analytics jobs, and offers lower cost and high density. As seen below, the SL model fits into a standard rack and can scale up to 8.8 petabytes, while the SC model fits into an extended rack and offers a capacity of up to 13.5 PB. The systems also can scale up to 8 yottabytes per data lake.

Powered by IBM’s Spectrum Scale high-performance clustered file system, it can integrate with the ESS 3000 and other ESS systems.
“What we’ve done with Spectrum Scale is we’ve enhanced its capability both in the ability to move object storage around, but secondarily so that the Spectrum Scale global namespace can see objects, not just files,” Herzog says. “Why do we do that? It could eliminate a silo. You talk to the end users, some end users are all-file, some users are all object, and a lot of end users are both, so if … some of the data is in file and some of the data is an object, you already had at least two silos of data. With a Spectrum Scale data accelerator, we actually can make the object storage into the same global namespace as the files. When your software is going to do the searching of what data to actually analyze and what data to collect, it’s all in the same data log.”
IBM also modernized its Cloud Object Storage (COS), increasing performance to 55 GB/sec in a 12-node configuration, with improvements in read by 300 percent and writes by 150 percent, based on object size. COS also supports Shingled Magnetic Recording (SMR) drive, high-capacity disk drives that deliver 1.9 PB in a 4U disk enclosure. All that will enhance integration with high-performance AI and HPC workflows.
In another nod to object storage, IBM rolled out Spectrum Scale for Data Acceleration, which enables it to move data from object storage, another step in eliminating silos between data sources and accelerating workloads and use cases, Herzog says.


Big Blue Turns In A Solid Quarter For Systems
By all accounts, Big Blue had a pretty good quarter ending in June, with sales of its System z16 mainframes skyrocketing upwards as they do every couple of years at the beginning of a new cycle and sales of its high-end Power10 machines also getting some traction. If everything goes …
Inside The Massive GPU Buildout At Meta Platforms
If you handle hundreds of trillions of AI model executions per day, and are going to change that by one or two orders of magnitude as GenAI goes mainstream, you are going to need GPUs. Lots of GPUs. And apparently Meta Platforms does, and it is getting out its big, …

Amazon Says It Can Embiggen AWS Past “Multi-$100 Billion” With AI
Here is how you know the cloud revolution is not done: Throughout the 77 quarter financial history of Amazon Web Services, which was formally launched in March 2006, there have been so few quarters of sequential revenue decline that you can literally count them on one hand. And the last …
Be the first to comment