

The remote procedure call, or RPC, might be the single most important invention in the history of modern computing. The ability to reach out from a running program and activate another set of code to do something — get data or manipulate it in some fashion — is a powerful and pervasive concept, and has given rise to modular programming and the advent of microservices.
In a world that is so unlike the monolithic code of days gone by, latency between code chunks and elements of the system running across a cluster means everything. And reducing that latency has never been harder. But some innovative researchers at Stanford University and Purdue University have come up with a co-design network interface card and RISC-V processor that provides a fast path into the CPUs that can significantly reduce the latencies of RPCs and make them more deterministic at the same time. This research, which was presented at the recent USENIX symposium on Operating Systems Design and Implementation (OSDI ’21) conference, shows how a nanoPU hybrid approach might be the way forward for accelerating at least a certain class of RPCs — those with very small message sizes and usually a need for very small latencies — while leaving other classes of RPCs to use the normal Remote Direct Memory Access (RDMA) path that has been in use for several decades and that has pushed to its lower latency limits.
Stephen Ibanez, a postdoc at Stanford University who studied under Nick McKeown — the co-developer of the P4 network programming language and the co-founder of Barefoot Networks who is now general manager of the Network and Edge Group at Intel — presented the nanoPU concept at the OSDI ’21 conference. He explained why it is important and perhaps blazes a trail for other kinds of network acceleration for all manner of workloads in the future.
Here is the problem in a nutshell.
Large applications hosted at the hyperscalers and cloud builders — search engines, recommendation engines, and online transaction processing applications are but three good examples — communicate using remote procedure calls, or RPCs. The RPCs in modern applications fan out across these massively distributed systems, and finishing a bit of work often means waiting for the last bit of data to be manipulated or retrieved. As we have explained many times before, the tail latency of massively distributed applications is often the determining factor in the overall latency in the application. And that is why the hyperscalers are always trying to get predictable, consistent latency across all communication across a network of systems rather than trying to drive the lowest possible average latency and letting tail latencies wander all over the place.
The nanoPU research set out, says Ibanez, to answer this question: What would it take to absolutely minimize RPC median and tail latency as well as software processing overheads?
“The traditional Linux stack is terribly inefficient when it comes to managing tail latency and small message throughput,” Ibanez explained in his presentation, which you can see here. (You can download all of the proceedings and really hurt your head at this link.) “And the networking community has realized this and has been exploring a number of approaches to improve performance.”
These efforts are outlined in the table below:

The definition of wire-to-wire latency used in the nanoPU paper, to be crystal clear, for any of these methods above is the time from the Ethernet wire to the user space application and back to the wire. There are custom dataplane operating systems with kernel bypass techniques. But the software overhead with trying to get a specific IPC onto a specific available CPU thread is onerous and it ends up being very coarse-grained. You can get a median latency of between two microseconds and five microseconds, but the tail latencies can be anywhere from 10 microseconds to 100 microseconds. So this doesn’t work for fine-grained tasks like those that are becoming more and more common with RPCs in modern applications.
There are also specialized RPC libraries that reduce latencies and increase throughput — eRPC out of Carnegie Mellon University and Intel Labs is a good example — but Ibanez says that they don’t rein in tail latencies enough and that is an issue for overall performance. So there are other approaches that offload the transport protocol to hardware but keep the RPC software running on the CPUs (such as Tonic out of Princeton University), which can boost throughput but which only address part of the problem. And while it is great that many commodity network interface cards (NICs) support the RDMA protocol, and it is also great that the median wire-to-wire latency for RDMA can be as low as 700 nanoseconds, the issue is that bazillions of small RPCs flitting around a distributed computing cluster need remote access to compute, not memory. We need, therefore, Remote Direct Compute Access. (That is not what Ibanez called it, but we are.)
And to do that, the answer, as the nanoPU project shows, is to create a fast path into the CPU register files themselves and bypass all of the hardware and software stack that might get into the way. To test this idea, the Stanford and Purdue researchers created a custom multicore RISC-V processor and an RPC-goosed NIC and ran some tests to show this concept has some validity.
This is not a new concept, but it is a new implementation of the idea. The Nebula project, shown in the table above, did this by integrating the NIC with the CPU, and got median latencies down into the range of 100 nanoseconds, which is very good, and tail latencies were still at two microseconds to five microseconds (what dataplane operating systems do for their median latencies), but the Stanford and Purdue techies said there was more room to drive latency and throughput. (The Nebula NIC came out of a joint effort between EPFL in Switzerland, Georgia Tech in the United States, and the National Technical University of Athens, working with Oracle Labs.)
Here is what the nanoPU looks like:
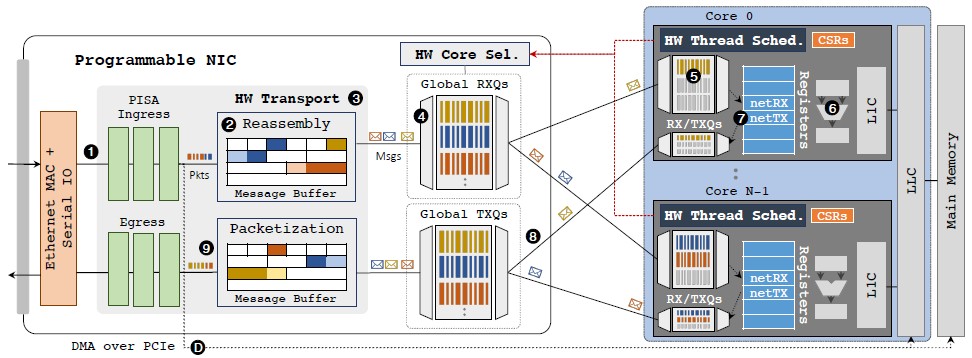
The nanoPU implements multicore processors, with hardware thread schedulers as you might imagine, each with their own dedicated transceiver queues, integrated with the NIC, and like Tonic, it has a programmable transport implemented in the NIC hardware. The DMA path from the hardware transport in the NIC to the last level cache or main memory of the CPU is still there, for those applications that have much longer latencies and do not need the fast path directly from the network into the CPU registers. The hardware thread schedulers operate on their own and do not let operating systems do it, since that would add huge latencies to go all the way up the OS stack and back down again.
The nanoPU prototype, implemented in FPGAs, is simulated to run at 3.2GHz, which is about what a top-speed CPU does these days, and uses a modified five-stage “Rocket” RISC-V core. The wire-to-wire latency comes in at a mere 69 nanoseconds, and a single RISC-V core can process 118 million RPC calls per second. (That’s with 8 B messages in a 72 B packet.)
Here is what the nanoPU can do running one-sided RDMA with legacy applications, compared to a NIC supporting RDMA:
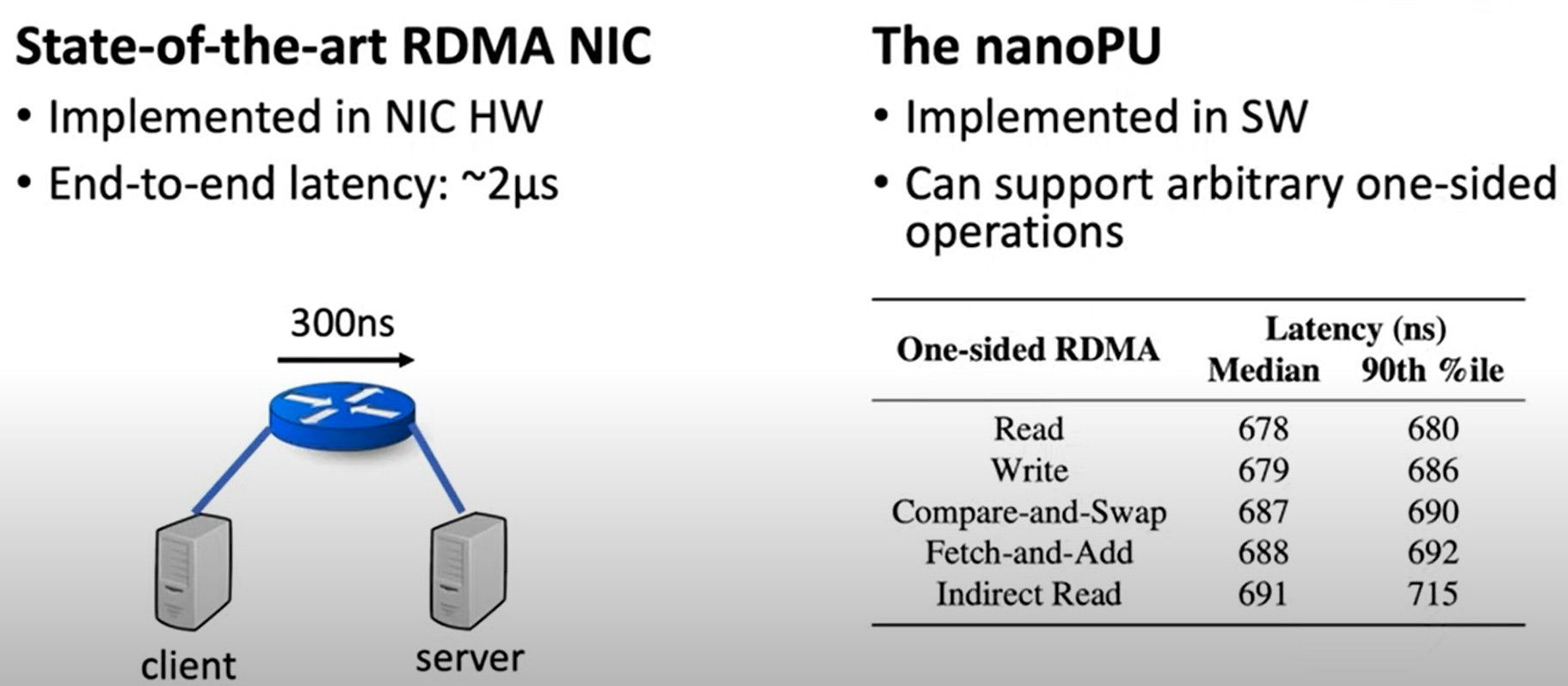
We presume this is InfiniBand for the left side of the chart, but do not know the vintage; it could be Ethernet with RoCEv2.
And here is how nanoPU does running the MICA key-value store, which also came out of Carnegie Mellon and Intel Labs:
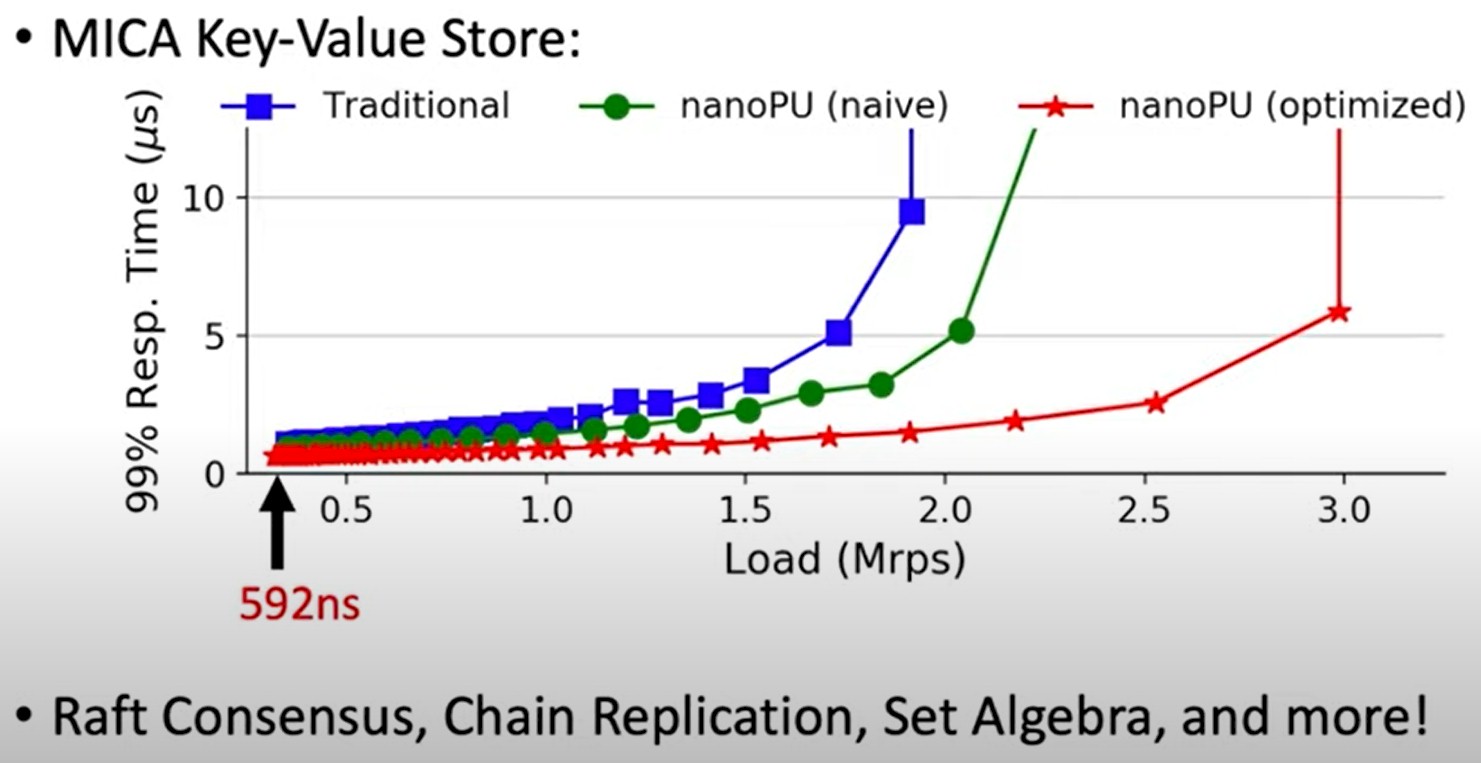
As you can see, the nanoPU can boost throughout compared to traditional RDMA approaches on this key-value store as well as significantly lower latencies — and do them at the same time.
It is looking like we may need a new standard to allow for all CPUs to support the embedded NICs without making anyone commit to any specific embedded NIC. Or, more likely, each CPU vendor will have its own flavor of embedded NIC and try to tie the performance — and the revenue — of the two for each other. The market always goes proprietary before it goes open. That’s the best way to maximize sales and profits, after all.
By the way, the nanoPU work was funded by Xilinx, Google, Stanford, and the US Defense Advanced Research Projects Agency.
And one final thought: Would not this approach make a fine MPI accelerator? Way back in the day, according to the nanoPU paper, the J-Machine supercomputer and then the Cray T3D had support for low-latency, inter-core communication akin to an RPC, but because they required atomic reads and writes, it was hard to keep threads from reading and writing things that they were not supposed to. The integrated thread scheduler in the nanoPU seems to solve this problem, with its register interface. Maybe all CPUs will have register interfaces one day, like they have integrated PCI-Express and Ethernet interfaces, among others.

Does the nanoPU has briad based adavantages in computing? Given the current cloud native based stacks, it would be difficult to levearge this in short term
The size and location of the RPC server’s memory footprint is key to the viability of this approach. In general, said footprints are large, host-memory-based; and often RPC serving is merely part of a larger overall application running on the serving host. Putting the RPC server in the NIC then becomes less compelling as it must fetch all its data from host memory, across PCIe Express, etc.