

The mighty SoC is coming for the datacenter with inference as a prime target, especially given cost and power limitations. With multiple form factors stretching from edge to server, any company that provide a seamless jump from devices in the field to large-scale datacenter processing is ready for the future.
This is the new reality Israeli startup, NeuReality, is preparing for, as are others in the AI ASIC and systems space who want to seamlessly let users jump from the edge to close compute with multiple form factors and efficiency-tuned software stacks. What is often missing from those conversations are some of the most important system elements, networking capabilities in particular.
From (very) early glance, NeuReality seem to have their networking and SoC priorities straight—and serious networking and chip design pedigree to bring it together with the announcement of their first prototype inference system for the datacenter.
Founder and CEO, Moshe Tanach, most recently headed engineering at Marvell and Intel on the SoC side and built big telco cred at a 4G base station builder acquired by Qualcomm. Co-founders include seasoned Mellanox engineers, including those who helped create the company’s first smart NIC SoC. Rounding out the list is also Naveen Rao, former GM for Intel’s AI Products Group (one of the founders of Nervana Systems, which Intel acquired in 2016).
In short, high-efficiency processing and networking is in the startup’s blood. But how does all that telco and edge know-how translate to the datacenter? And so far, to do all of this with current funding at only $8 million in seed?
Tanach says a physical tightening of the spaces between edge and the server is already happening, especially for telcos, but it’s the cloud builders and largest AI users that are in the crosshairs for the longer haul. “The cloud users for AI are hitting scalability limits, they’re looking at their system flows in inference, the whole AI pipeline with all the pre- and post-processing and how that interfaces with the network and storage. We came to the conclusion that the system needs to be built differently and the chips themselves need to be designed differently for the next 10X jump in efficiency.”
 NeuReality’s answer to this is its first prototype system for the datacenter with 16 Xilinx Versal cards to show off what the NR1 SoC can do.
NeuReality’s answer to this is its first prototype system for the datacenter with 16 Xilinx Versal cards to show off what the NR1 SoC can do.
While Xilinx is likely thrilled to have any chance to show off a densely packed box with inference-ready Versal FPGAs, Tanach notes that the FPGA angle is more for showcasing what the NR1 can do in terms of performance and efficiency. He says the configuration they’re moving to market with for evaluation is cooler out of the gate than comparable platforms. The Versal FPGAs Each run at 75-100kW (1.6kW total) but the value of what the NR1 is that there’s no x86 socket or PCIe switch or NICs gobbling energy. “When the SoC tapes out and isn’t just running on FPGA the power efficiency will improve tremendously,” he says.
While there are no CPUs or NICs or PCIe switches, the NR1 contains NeuReality’s network engine, which is where most of the patents/IP lie. In essence, when an AI request comes in from any virtual machine in the cloud to the server it doesn’t touch software, it goes directly through the network engine via the “AI hypervisor” that routes it to the processing elements.
In contrast to most datacenter inference systems today with dual-socket CPUs, accelerators, and two NICS, NeuReality is trying to get around the overhead of the CPU entirely. Currently, the remote client sends an offload request, which is shuttled to the CPU in DRAM into queues so the scheduler can decide what’s next as well as handle load balancing and other management functions. The hypervisor, as Tanach calls it, is actually hardware with all of that built in.
The existing architecture of a CPU-centric approach versus the path for NeuReality:
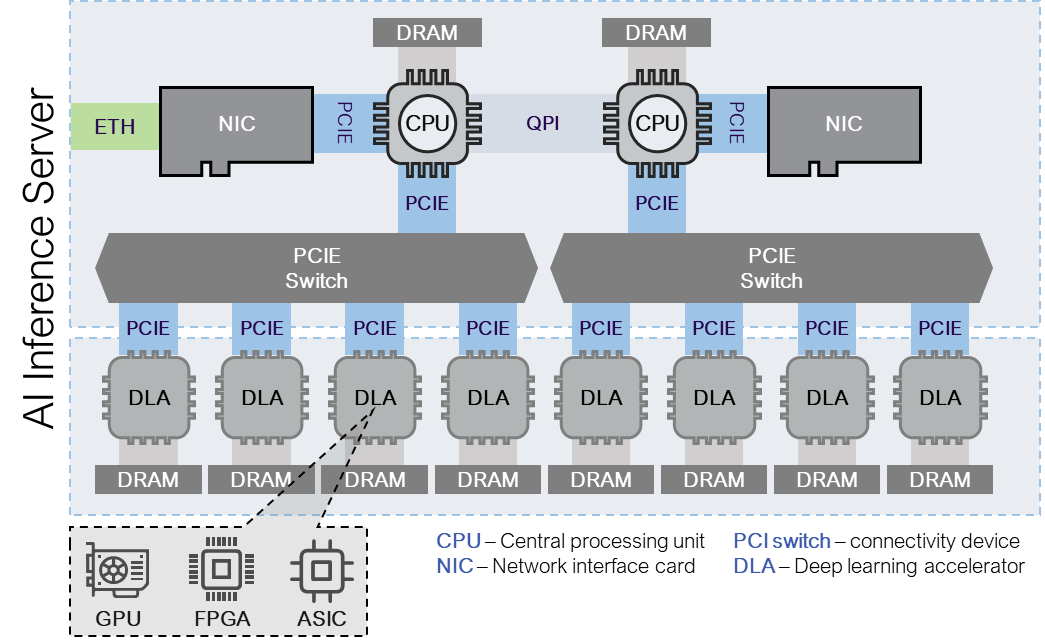
This classic and outdated architecture is introducing high system overheads, cost and power to host the inference accelerators, Tanach says. “In training it makes sense due to the close relationship between the CPU and GPU/ASIC. But in inference case, where the accelerator is offloading the complete computation, it makes no sense to host it with expensive CPUs. In the NeuReality approach below we see the inference server’s datapath for each AI request and response.
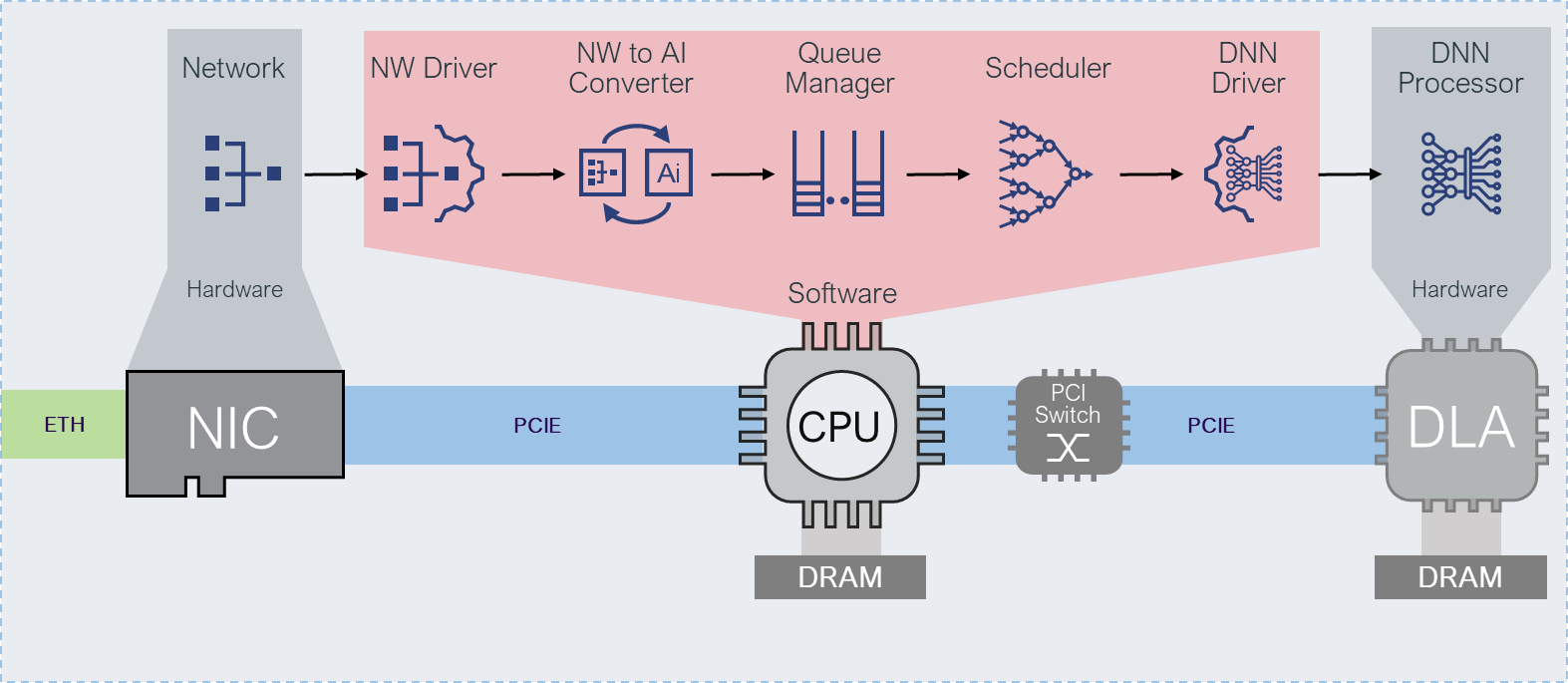
“The amount of expensive datapath functions that runs on the CPU is creating bottlenecks that cause underutilization of the DLAs as well as having a sub optimal architecture using expensive x86 CPUs just for data movement and management. Our AI-hypervisor technology moves all these functions to hardware to reduce power and cost, improve performance as well as provide linear scalability solution with no system bottlenecks,” he adds.
There is quite a bit of other overhead that can be skipped when removing the CPU entirely beyond data shuttling. For instance, “When you’re building a CPU-centric server you have to pay the memory twice,” Tanach tells us. “The x86 CPUs where the data is in the beginning and now, since this is inference, not training, you also have to store the payload (inputs, models, etc) in CPU then copy those. In our case, since it’s all in one chip, it’s a shared memory instance—we need a lot of memory but not more than other deep learning accelerators (128MB of internal DRAM and 6 channels of DDR5) looking ahead.”
NeuReality will support Ethernet and all the standard protocols but will also allow for RDMA (RoCE v2) to truly optimize inference cost on both the client and server side to let users connect to different configurations in the datacenter.
“What we are bringing to market will be realized in a chip we’ll manufacture. The first approach here was to build a full system, map all the flows, and let people fine-tune the architecture before we tape out. This is why we’re using FPGAs for this prototype,” Tanach says. He expects the first device for datacenter will be around 100W with edge consuming less power (with less performance, of course) at around 20W. The goal is to have the same device in the edge and server nodes.
“Datacenter owners and AI as-a-service customers are already suffering from the operational cost of their ultra-scale use of compute and storage infrastructure,” Tanach says. “This problem is going to be further aggravated when their AI based features will be deployed in production and widely used. For these customers, our technology will be the only way to scale their deep learning usage while keeping the cost reasonable. Our mission was to redefine the outdated system architecture by developing AI-centric platforms based on a new type of SoC.”


Chiplet Cloud Can Bring The Cost Of LLMs Way Down
If Nvidia and AMD are licking their lips thinking about all of the GPUs they can sell to the hyperscalers and cloud builders to support their huge aspirations in generative AI – particularly when it comes to the OpenAI GPT large language model that is the centerpiece of all of …
Optimizing AI Inference Is As Vital As Building AI Training Beasts
The history of computing teaches us that software always and necessarily lags hardware, and unfortunately that lag can stretch for many years when it comes to wringing the best performance out of iron by tweaking algorithms. This will remain true as long as human beings are in the loop, but …
Meta Platforms Crafts Homegrown AI Inference Chip, AI Training Next
As we pointed out a year ago when some key silicon experts were hired from Intel and Broadcom to come work for Meta Platforms, the company formerly known as Facebook was always the most obvious place to do custom silicon. Of the largest eight Internet companies in the world, who …
Be the first to comment