

Managing infrastructure at Google is a lot more than just putting stuff into containers and letting Borg push it around. There is a whole art to keeping services running at scale up and running, and the people who do it are called site reliability engineers, or SREs. More and more, the practices that Google created are being adopted and so is the SRE term.
Most companies can’t hire the smartest people in infrastructure in the world, like the hyperscalers and cloud builders can. And so we rely on someone to create the software tools that embody their experience. This happened with Linux containers and container orchestration, for instance, which were largely perfected at Google, and has certainly happened for cloudy infrastructure in general. And for that software-encapsulated SRE experience, the IT community is relying on people like Brian Singer.
In 2012, Singer co-founded Orbitera, a company that built a marketplace platform for buying and selling cloud software. An important part of that was ensuring that the billing was timely and accurate, something that Orbitera struggled with at times. Well, until the company was bought in 2016 by Google Cloud as part of the larger cloud provider’s efforts to expand its presence in the enterprise services space.
It was there that Singer and Marcin Kurc, then CEO of Orbitera, got a look at the work that Google was doing in the area of site reliability engineering (SRE), which uses software engineering practices to help maintain infrastructure operations. The goal is to ensure that the infrastructure continues to run at levels that enable companies to meet SLA and other goals, not always an easy task at a time when an enterprise’s infrastructure environment can span hybrid clouds, multiple clouds, the edge and legacy datacenters.
“We got to understand some of the production practices used inside Google to meet what customers were looking for,” Singer tells The Next Platform. “One of the things that Google has done a really, really good job of over the years is applying engineering principles to the problem of managing and running infrastructure. That has given rise to a set of production practices and a job title, so to speak, called site reliability engineering, or SRE, something that started inside of Google probably a decade and a half ago. It’s obviously been practiced on some of the highest scale systems out there, but for us as a smaller startup, we came into Google and immediately had to adapt our practices to what they do to run production and specifically adopted a lot of these SRE principles.”
At its core, SRE uses DevOps practices to reduce the amount of work that is needed over and over, such as resetting machines on a regular schedule because they otherwise will run out of memory. The goal is to figure out how not to have to reset those machines on a scheduled basis.
“This set of production practices inside of Google that gave rise to SRE have actually given rise to a lot of the infrastructure that we start to take for granted today, such as Kubernetes,” Singer says. “Kubernetes is something that grew out of Google’s work on their own container orchestration platform board and that’s something that was built by Google SREs [site reliability engineers] over many, many years. For SREs, one of the lynchpins that enables them to do their job really successfully is that they are able to build feedback loops between what the developers who are building features are doing and the operators who are responsible for actually ensuring that a service works in production.”
Those feedback loops help developers and SREs see if what they are doing is hurting the end user experience or falling short of expectations, which in turn can blow back on the company in terms of lost customers or hit on their reputation. That has given rise to service level objectives, or SLOs, which essentially are goals that companies need maintain in order to satisfy SLAs. (Also in the mix are SLIs, or service level indicators, which measure compliance with SLOs.)
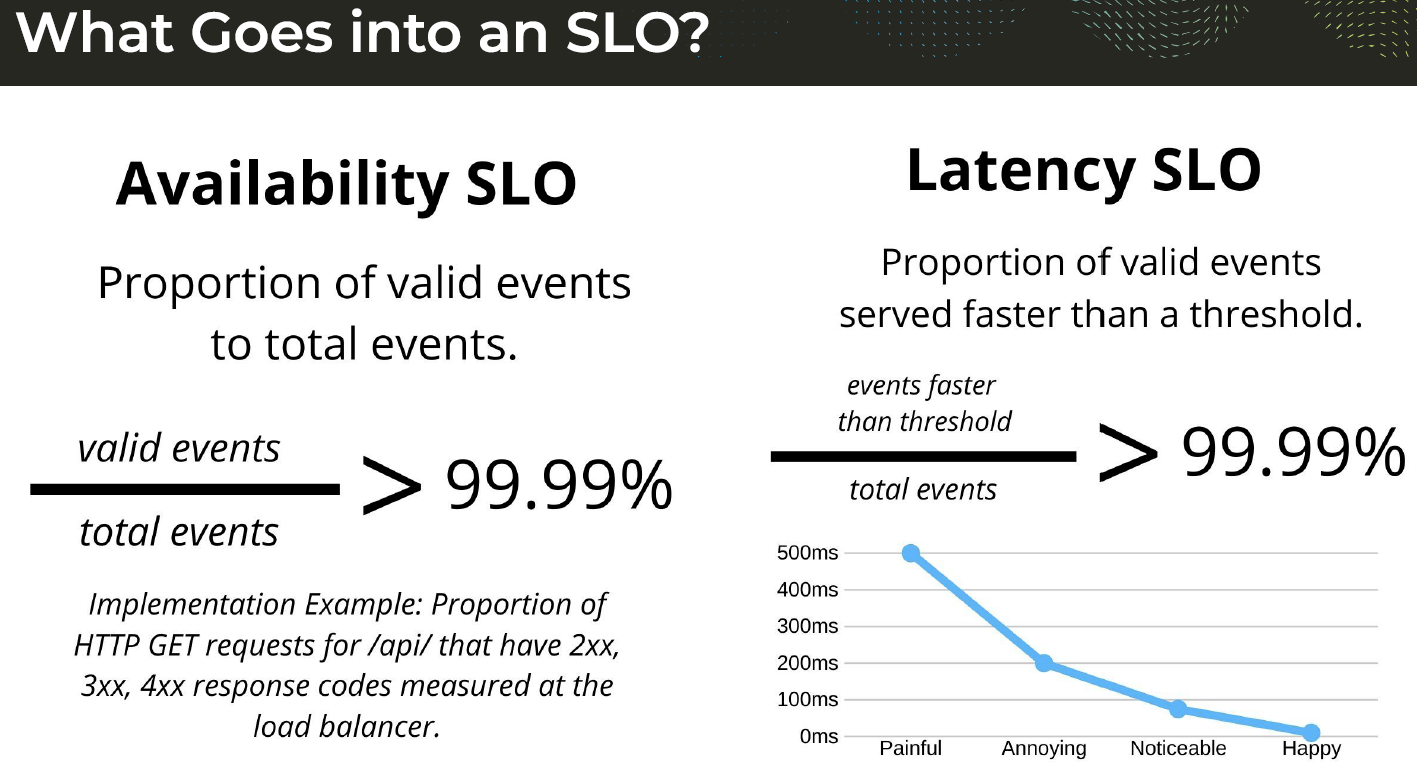
“In principle, it’s a pretty straightforward thing,” Singer says. “It makes a lot of sense to have a goal and to understand how we’re trending toward that goal, given all the things that we do to our infrastructure and all the changes that we make to our software. But in practice, historically, these sorts of things required some very sophisticated engineers to be able to get up and running. What we found in the market over the last two or three years is that SRE, because of the benefits that it has in terms of gaining leverage and scale over infrastructure and improving the lives of developers and customers, is it’s starting to gain widespread adoption. What we’re seeing is many companies starting to try to figure out, ‘How do we actually adopt and implement a solution?’”
Singer and Kurc, seeing a growing interest among enterprises to adopt SRE, in 2019 launched Nobl9, with the goal of giving organizations a commercial service that will enable them to leverage SLOs, a cornerstone of SRE. After about nine months of beta testing with an array of organizations, the startup in early February made its eponymous software-as-a-service (SaaS) SLO Platform generally available. A week later Nobl9 announced $21 million in Series B funding that included a number of venture capital firms, including Battery Ventures, CRV, Bonfire Ventures and Resolute Venture, all of which contributed to the almost $7.5 million the company raised in September 2019.
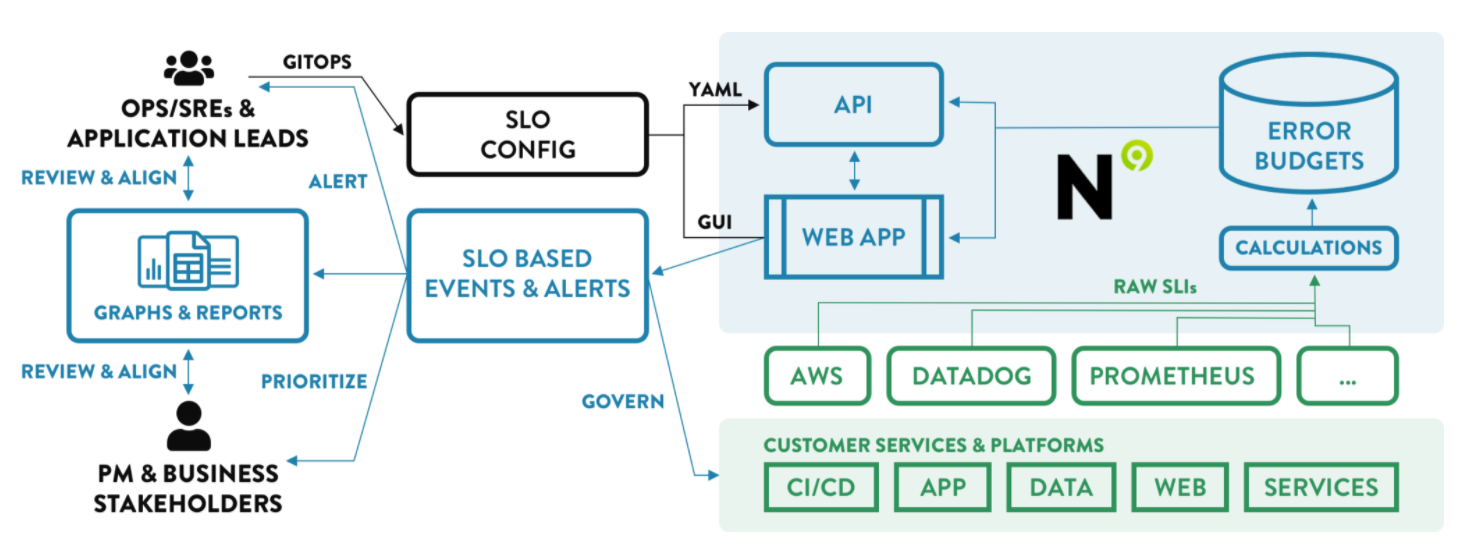
The platform is designed to use existing data sources like monitoring systems to collect metrics and determine reliability targets. The tools within the platform help enterprises create feedback loops and ensure infrastructure reliability to enable them to keep in line with their SLOs while balancing the development of software features, reliability, business objectives and costs. The SaaS offering can work not only with cloud infrastructures but also legacy on-premises operations, says Singer, Nobl9’s chief product officer. (Kurc is the CEO.) It’s priced based on the number of services SLOs are being calculated for in a system. A midsize company may have a couple of hundred services; larger enterprises in the thousands. The pricing scales based on that, as well as if the infrastructure is in the cloud or on premises.
Early customers include Adobe and Brex, a financial services organization based in San Francisco.
“The concepts are so straightforward that you don’t have to be that sophisticated to want to move into to using SLOs,” he says. “The sophistication comes in distilling this concept. It’s very simple and applying it to your own architecture, you think a typical customer might have one monitoring system for VMware that they’re running and another that they’re running for their cloud infrastructure and then another that they’re running for some legacy on-prem stuff. Then some of the stuff is living in log files somewhere. The trick is getting a holistic view and using SLOs across all of that requires a platform that’s been built for that use case.”
Key to SLOs is a metric called the error budget. SLOs don’t monitor such aspects as CPU consumption or available memory; instead they rely on error budgets, which gives administrators a way of measuring reliability.
“If your reliability target for availability of a system is 99.9 percent, your error budget is that 0.1 percent,” Singer says. “We think about it in terms of spending that error budget over a period of time. If you are 0.1 percent unreliable over a 30-day period, you’ve actually done perfectly well in a lot of situations. That allows you to take very targeted actions based on how quickly you are consuming that error budget. But if all of a sudden I’m consuming it five times faster than I expect, then I actually probably want a developer to go look at that immediately just based on the rate of that error budget being consumed. If the error budget is being burned too quickly, if we’re going to run out of our budget, then it’s a problem.”
Nobl9 – the “Nobl” part of the name is a nod to noble gases, the most stable and reliable gases – is entering into a larger observability market that includes some established players, including Splunk, Sumo Logic, AppDynamics and Dynatrace, as well as startups like Honeycomb, which launched in 2016 and in early February announced a $20 million Series B round, bringing the total amount raised to $46.9 million. This week it rolled out Refinery, aimed at helping enterprises improve their observability data at scale. And now, you can turn your system and database and application administrators into a kind of virtual SRE with the help of software.

Be the first to comment